コンテキスト、記憶、これまでの作業を失わずに AI ワークフローを新しいエージェントへ移行する方法(2026年版ガイド)

はじめに
AIの状況は驚くほど速く変化しています。ある週はChatGPTに大きく依存していても、次の週にはClaudeの優れたコーディング能力を試したくなったり、あるいはOpenClawやHermes Agentのような特化型エージェントへ移行していたりします。
タスクの専門性、チームの好み、あるいは機能差に合わせてツールを切り替えるのはよくあることです。しかし、ユーザーはすぐに、本当の難しさはツールの切り替えではなく、ワークフローの連続性を保つことにあると気づきます。
新しいエージェントに移ると、要するに空っぽのオフィスに入るようなものです。ファイル、メモ、プロジェクトの文脈、繰り返しの指示、途中までの成果物は、旧ツールに取り残されます。やり直さずにAIエージェントを切り替えたいなら、持ち運べるAIメモリのための戦略が必要です。
このガイドでは、AIワークフローの移行が構造的に難しい理由、一般的な移行の近道が失敗する理由、そしてエージェント間で文脈を共有するために永続メモリ層をどう使うかを解説します。
簡潔な答え: 文脈を失わずにAIワークフローを新しいエージェントへ移す方法
文脈、メモリ、過去の作業を失わずにAIワークフローを新しいエージェントへ移すには、メモリをチャットインターフェースから切り離す必要があります。次の基本手順に従ってください:
MemoryLakeのような持ち運び可能なメモリ層を採用し、AIシステムの永続的な第二の脳として機能させます。
ファイル、メモ、過去の結論を単一のエージェントに直接入れるのではなく、この独立した層にアップロードして、文書とデータを集約します。
API、プラグイン、またはMCP(Model Context Protocol)を介して、新しいAIエージェントをこのメモリ層に接続します。
新しいエージェントが既存のプロジェクトメモリを読み込むよう設定し、再出発やファイルの再アップロードなしでワークフローの連続性を確保します。
AIワークフローの移行が思ったより難しい理由
AIワークフローを別のエージェントへ移すとき、単に入力するUIを変えるだけではありません。文脈が複雑に絡み合った網の目を移動させようとしているのです。AIツールは自然とサイロ化し、使えば使うほど蓄積される文脈も増えていきます。
AIエージェントを切り替えると何が失われるのか
新しいタブを開いて新しいエージェントに入力し始めるだけでは、作業の重要な要素がいくつも置き去りになります:
アップロード済みファイル: PDF、スプレッドシート、Word文書など、アップロードと説明に何時間も費やしたもの。
メモと過去の結論: 前のエージェントが生成した戦略的判断、要約、統合されたリサーチ。
時間をかけて構築された文脈: AIが何十回ものやり取りを通して学んだ、プロジェクトの目的、トーン、制約に関する繊細な理解。
ワークフローの連続性: 複数日にわたるプロジェクトの、進行中の段階的なロジック。
過去の指示: 繰り返し使うルール、書式の好み、プロジェクトレベルのメモリ。
一般的な移行の近道が失敗する理由
多くのユーザーは、手作業の回避策でエージェント切り替えを力づくで乗り切ろうとします。残念ながら、こうした方法では実際のワークフローの連続性はほとんど保てません。
コピペ: あるエージェントから別のエージェントへ長いテキストの連鎖をコピーすると、雑然としてトークンを大量に消費するプロンプトになり、新しいモデルを混乱させます。
チャットのエクスポート: チャット履歴を書き出しても、検索可能で文書を理解するメモリシステムにはならず、静的なテキストファイルになるだけです。
文書の再アップロード: すべてのファイルを手作業で再アップロードするのは時間の無駄であり、以前のエージェントがそれらのファイルから導き出した履歴上の知見を完全に失わせます。
プロンプト詰め込み: プロジェクトの背景をすべて1つの「スーパー・プロンプト」に押し込もうとすると、コンテキストウィンドウを超過し、モデルの性能低下を招くことがよくあります。
より良いワークフロー移行の形とは
AIワークフローを移行する目的は、単にチャットログを移すことではありません。再利用可能な文脈、文書、メモ、過去の作業を、持ち運べる層に保存することです。
AIエージェントを、処理装置(脳)と保存先(メモリ)の両方として扱うのではなく、この2つを分ける必要があります。AIワークフローのために永続メモリ層を導入すると、「メモリパスポート」を作れます。これにより、新しいエージェントを既存のナレッジ基盤に接続できるようになります。
ここで登場するのがMemoryLakeのようなインフラです。MemoryLakeは、AIシステムのための永続メモリ層として設計されています。単なるチャット履歴の書き出しではなく、ツール、モデル、セッション、エージェントをまたいで使える持ち運び可能なメモリ層です。文書を理解し、ワークフローを理解するメモリ基盤として機能することで、ユーザーがゼロからやり直すことなくエージェント間を移行するのを支援します。
ステップごとに見る: MemoryLakeを使ってワークフローを新しいエージェントへ移す方法
過去の作業を失わずにAIワークフローを別のエージェントへ移行したいなら、MemoryLakeを使った実践的な移行手順は次のとおりです。
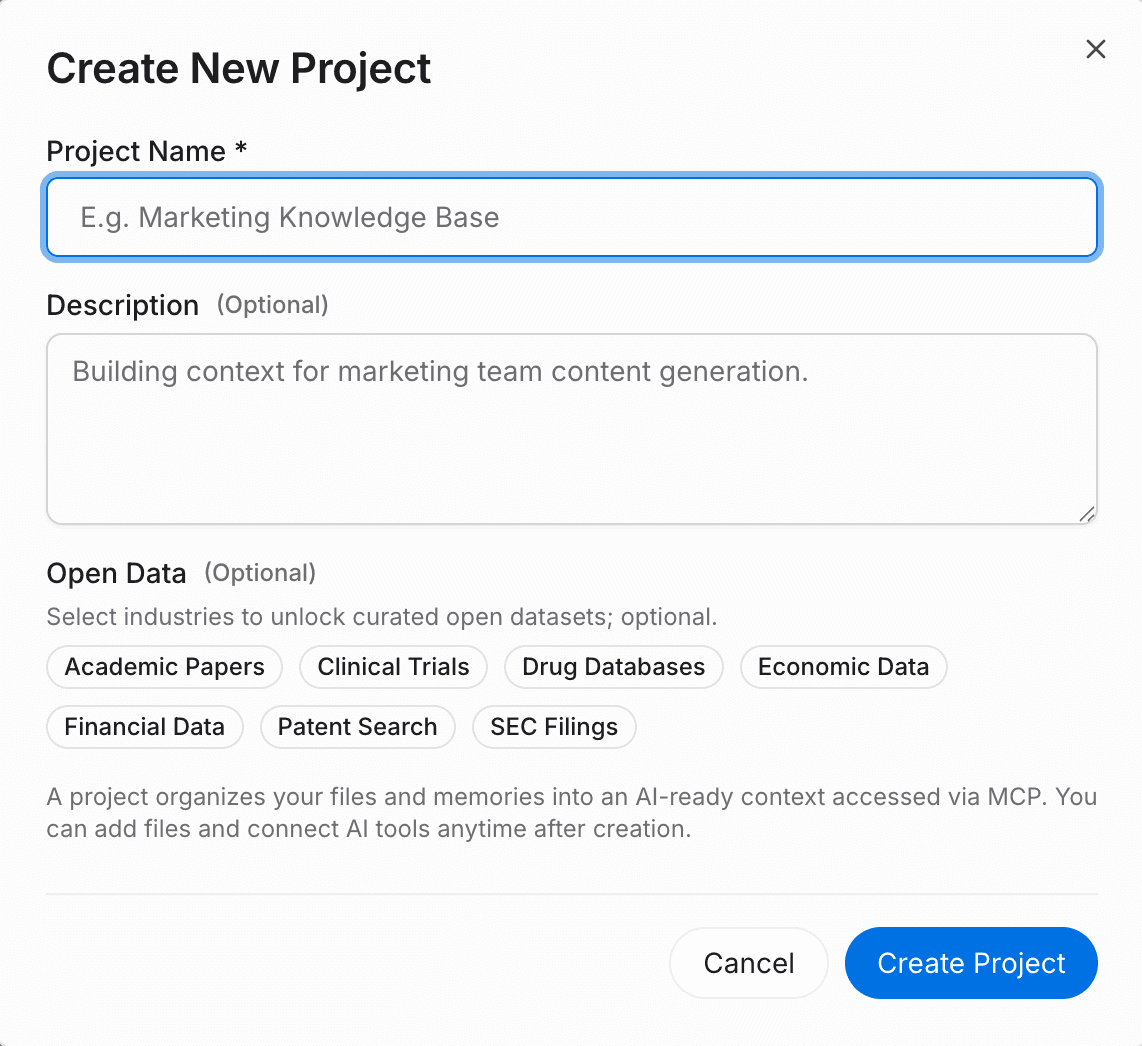
ステップ1: プロジェクトを作成し、ファイルとデータを集約する
持ち運び可能なAIメモリを実現する第一歩は、生の素材を旧エージェントから永続層へ移すことです。
MemoryLakeで新しいプロジェクトを作成します。
添付ボタンをクリックして、主要な文書をアップロードします。このプラットフォームはPDF、Word、Excel、Markdownなど、さまざまな形式をサポートしています。
MemoryLakeはコンテンツを自動的に解析・索引付けし、再利用可能なメモリに変換します。
ファイルセクションから外部データソースを直接接続することもできます。
移行の価値: これを永続層で一度行えば、文書コンテキストを持ち運べる形で保持できます。AIツールを切り替えるたびにファイルを何度も再アップロードする必要が完全になくなります。
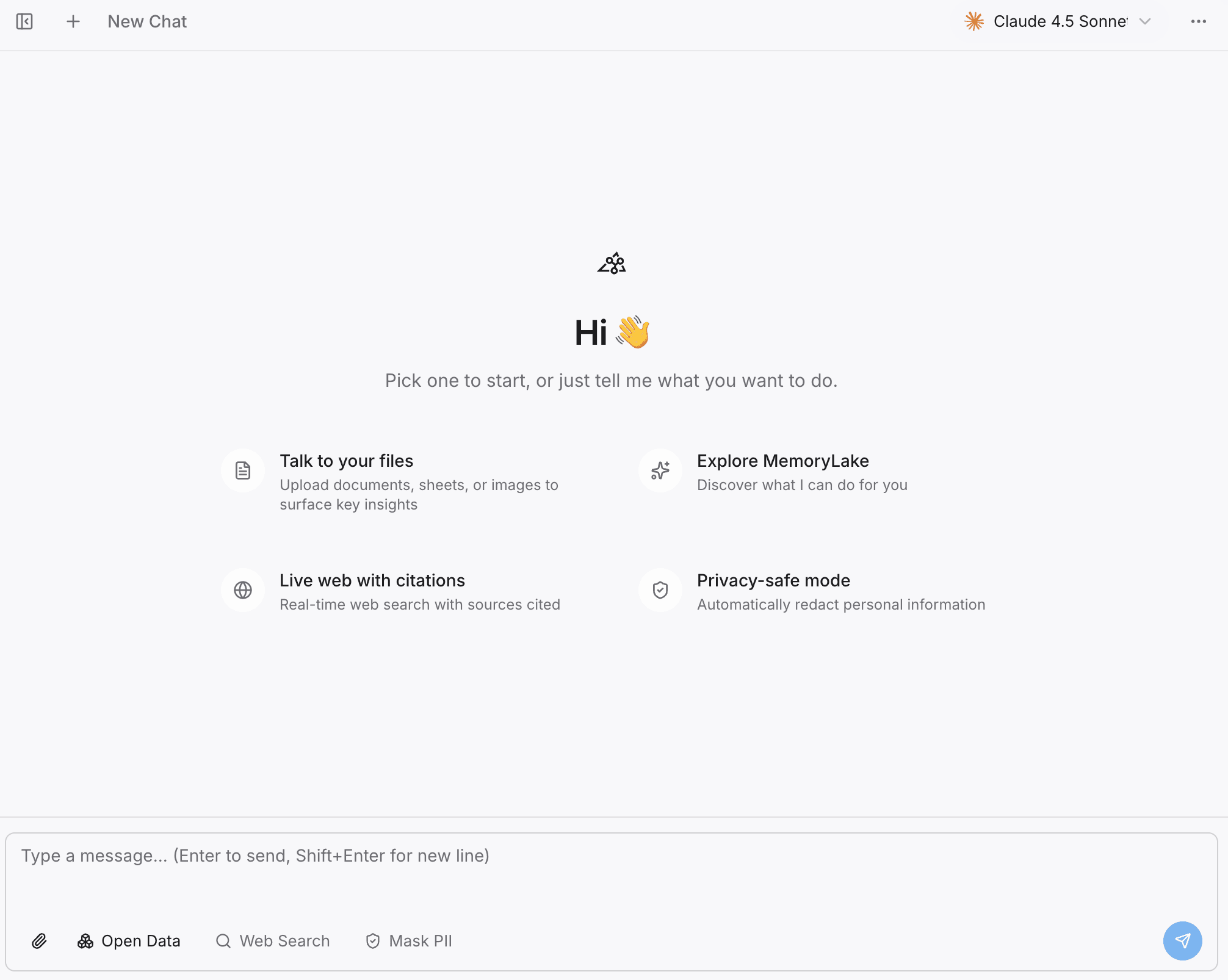
ステップ2: 検索と対話の機能をテストする
新しい外部エージェントに移る前に、文脈が正しく保持されていることを確認しましょう。
MemoryLake Playgroundを開きます。
プロジェクトメモリに直接質問し、メモ、過去の作業、文書の知見をシステムが正確に取得できることを確認します。
移行の価値: これにより、過去の作業が実際に使えて検索可能であることが保証され、新しいツールを接続する前からワークフローの連続性が確保されます。
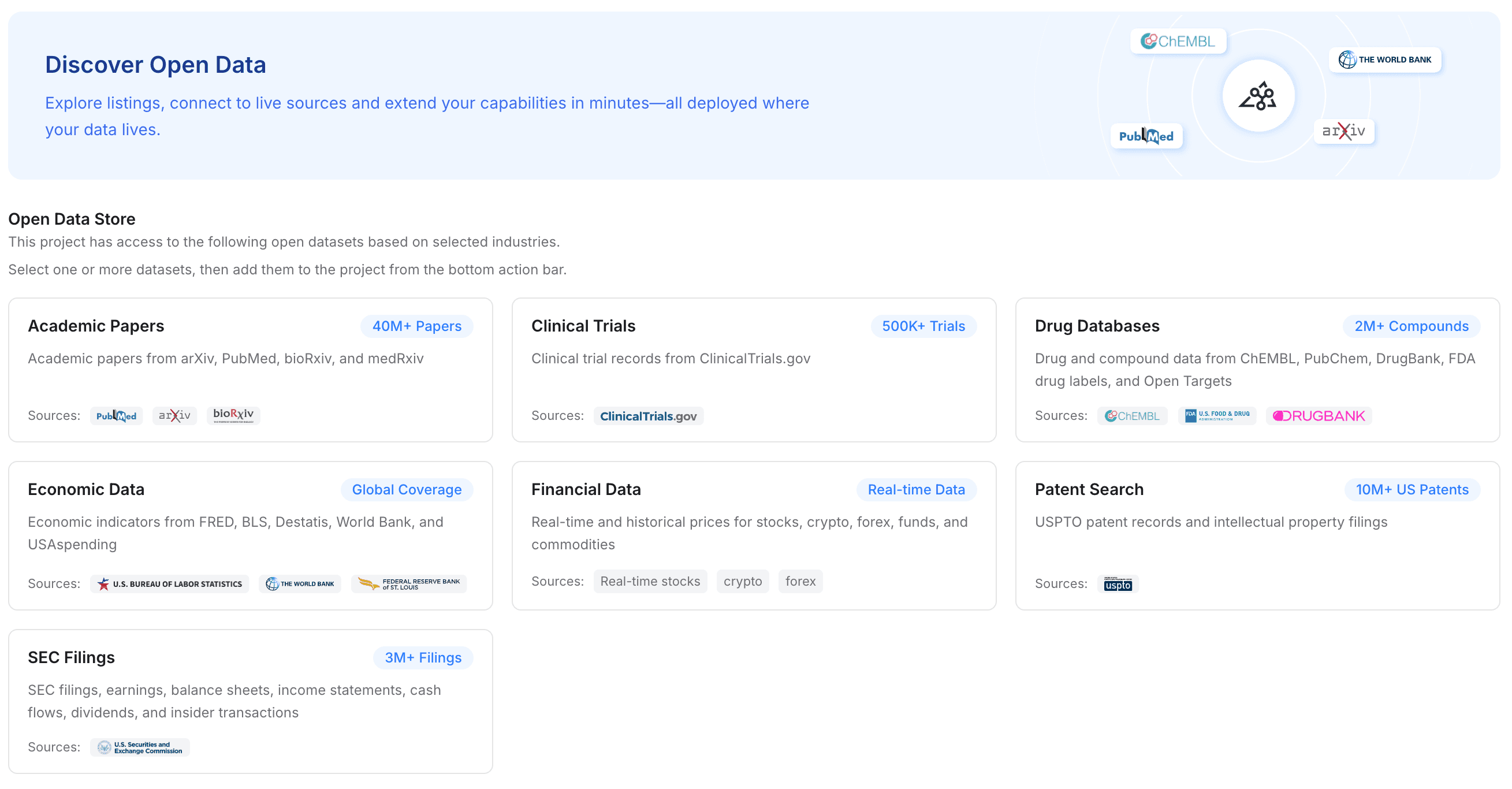
ステップ3: オープンな業界データを追加してプロジェクトを強化する
新しいエージェントに移るとき、多くの場合、以前よりも高い性能を期待します。MemoryLakeを使えば、個人的な文脈により広い業界知識を補強できます。
クリックしてプロジェクトに「Open Data」を追加します。
無料で利用可能な業界データセットから選び、プロジェクトのドメイン知識を即座に強化します。
選択した業界に応じて、公開ドキュメントには学術論文、臨床試験、医薬品データベース、経済データ、金融データ、特許検索、SEC提出書類などへのアクセスが記載されています。
移行の価値: これにより、新しいエージェントがより早く実用的になります。業界標準を新しいモデルに何時間も教える代わりに、非常に構造化されたドメイン固有のメモリをワークフローに直接注入できます。
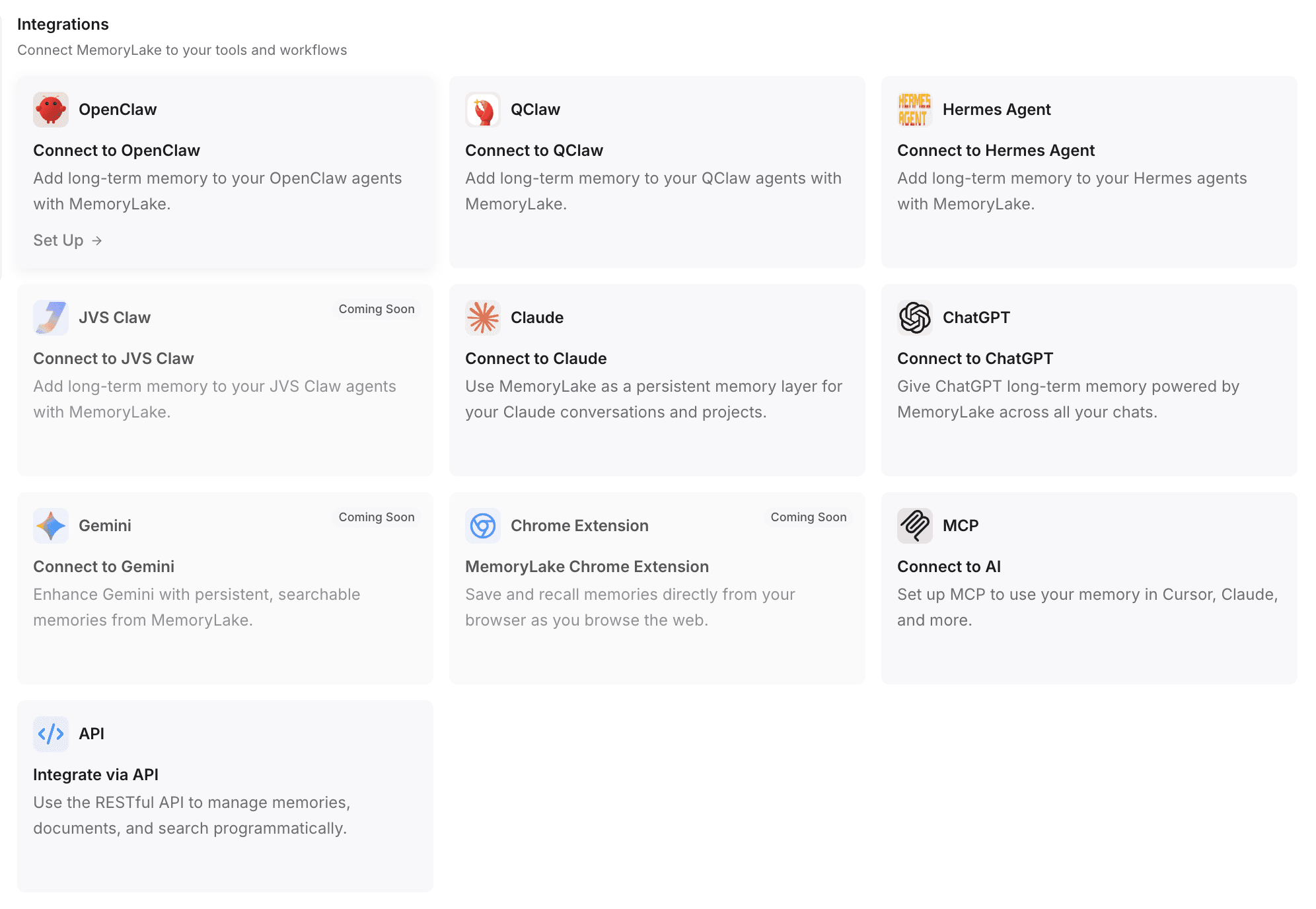
ステップ4: MemoryLakeをツールとワークフローに接続する
最後のステップは、この永続メモリ層を新しいAIエージェントに接続することです。
API設定に移動し、自分のAPIキーを選ぶか作成します。
自動設定の場合: ドキュメント化されたセットアップ手順によると、自動セットアップコマンドを使えることがよくあります。たとえばOpenClawへ移行する場合、統合ガイドをコピーしてそのままOpenClawに貼り付けられます。エージェントは必要なプラグインを自動でインストールし、設定を完了し、ゲートウェイを再起動します。
他のツールの場合: MemoryLakeは、ChatGPT、Claude、OpenClaw、Hermes Agent、およびその他のツールとの統合を、プラグインや1クリックインストール(多くの場合、実行に必要なのは1つのコマンドだけ)でサポートしています。
カスタムワークフローの場合: APIやMCPスタイル(Model Context Protocol)の接続によって、プログラム的な統合も可能です。
移行の価値: これが、エージェント間メモリを実現する方法です。新しいエージェントは、古いエージェントとまったく同じファイル、メモ、文脈に即座にアクセスできます。プロンプトを作り直す必要がなくなり、ワークフローのリセットをゼロにできます。
AIワークフロー移行時に避けるべきよくあるミス
チャットログをメモリと混同すること: ChatGPTの履歴を
.txtファイルとしてダウンロードし、それをClaudeにアップロードしてもうまくいきません。構造化されていないチャットログは文脈を薄めてしまいます。必要なのは、構造化された文書対応のメモリシステムです。ツールごとに移行すること: Claude内にカスタム指示を設定すると、その指示はClaudeの中に閉じ込められます。システムプロンプト、繰り返し使うルール、重要なプロジェクト文脈は、ツール非依存の層に保存してください。
データセキュリティを軽視すること: データを移行する際は、特に法務や財務の文書を扱う場合、プライバシーとコンプライアンス要件を尊重するメモリ層を使っていることを確認してください。
この移行アプローチが最適な人
再利用可能なメモリ層の採用は、文書中心または継続性重視のAIワークフローを持つ人に特に推奨されます。このアプローチは、特に次のような人に有効です:
研究者とアナリスト: さまざまな推論モデルをまたいで、数多くの学術論文や財務レポートへのアクセスを維持する必要がある人。
創業者とプロダクトチーム: 異なる特化型AIエージェントを使って、製品仕様、市場調査、コードベースを反復改善する人。
金融、法務、バイオテック、コンサルティングの専門家: 微妙なプロジェクト文脈や過去の分析結果を失うと、ワークフロー全体が崩れかねない分野の人。
結論
すべてを1つのAIエージェントに頼る時代は終わりつつあります。タスクがより専門化するにつれて、AIワークフローを新しいエージェントへ移すことは日常的な必要事項になるでしょう。ただし、ツールを移すことは、作業を捨てることを意味すべきではありません。孤立したチャットウィンドウから永続メモリ基盤へ移行することで、やり直さずにAIエージェントを切り替えられます。
ワークフローがファイル、メモ、プロジェクトの文脈、再利用可能なメモリに依存しているなら、MemoryLakeのような持ち運び可能なメモリ層が移行をずっとスムーズにしてくれます。日常的にツールを切り替えるチームや個人にとって、MemoryLakeはゼロから再構築するのではなく、ワークフローの連続性を維持する有力な選択肢です。
よくある質問
文脈を失わずにAIワークフローを新しいエージェントへ移すにはどうすればよいですか?
文脈を失わずにAIワークフローを移すには、文書やプロジェクト履歴をAIエージェントの内部に保存するのをやめるべきです。代わりに、永続メモリ層(MemoryLakeのようなもの)を使ってファイル、メモ、文脈を保持し、新しいエージェントをAPIまたはMCP経由でその層に接続します。
AIエージェントを切り替えると何が失われますか?
AIエージェントを切り替えると、通常はアップロード済みファイル、プロジェクト固有の指示、履歴的な文脈、過去の結論、そして何十回ものやり取りで築いたワークフローの連続性が失われます。
新しいAIツールに移るとき、チャット履歴だけで十分ですか?
いいえ。チャット履歴のエクスポートは静的なテキストログを提供するだけで、検索可能で文書対応のメモリにはなりません。チャットログを新しいエージェントに貼り付けると、たいていはコンテキストウィンドウを圧迫し、出力品質が低下します。
エージェントをまたいでメモや過去の作業を保持するにはどうすればよいですか?
持ち運び可能なAIメモリ層を使えば、エージェントをまたいでメモや過去の作業を保持できます。作業を中央集約型の、エージェントに依存しないプラットフォームにアップロードしておけば、採用した新しいAIツールはその永続メモリに問い合わせて過去の知見を取得できます。
MemoryLakeとは何で、どう役立ちますか?
MemoryLakeは、AIシステム向けの永続メモリ層として設計されています。文書、文脈、メモを特定のAIツールから独立して保存できる「第二の脳」やメモリパスポートとして機能し、ワークフローを新しいエージェントへ簡単に移行できるようにします。
ワークフローをゼロから作り直さないようにするにはどうすればよいですか?
標準業務手順、繰り返しの指示、主要文書を外部メモリ基盤に集約することで、ゼロからの再構築を避けられます。新しいエージェントを導入したら、プラグインやMCPを介してその基盤に接続するだけです。