ワークフロー内でClaude、ChatGPT、Gemini間のメモリとコンテキストを同期する方法(2026年ガイド)

はじめに
最良のAIモデルを使い分けることは、現代の知識労働者にとって標準状態です。複雑な技術文書の下書きにはClaudeを使い、アイデアを練り直すときはChatGPTに切り替え、ライブのWebと調査結果を突き合わせるためにGeminiを開く、といった使い方が考えられます。しかし、このマルチモデル・アプローチには即座にボトルネックが生まれます。ツールを切り替えるたびに、プロジェクトのコンテキストが途切れてしまうのです。
その結果、同じ背景情報を何度も貼り付け、同じソース文書を再アップロードし、制約条件を何度も説明し直すことになります。コンテキストが断片化することによる摩擦は生産性を奪い、トークンを浪費し、異なるアシスタント間で出力の一貫性を損ないます。
Claude、ChatGPT、Gemini間でメモリとコンテキストを同期するには、個々のAIプラットフォームの外側にある集中型の永続メモリ層—たとえばMemoryLake—が必要です。プロジェクトファイル、背景知識、過去の意思決定をAPIまたはMCP経由でアクセスできる持ち運び可能なシステムに保存しておけば、繰り返しのコピー、貼り付け、再アップロードをせずに、どのAIモデルにも同一のコンテキストをシームレスに供給できます。
このガイドでは、同じ説明を何度も繰り返さないための方法、統合されたクロスモデルのAIメモリの構築方法、そしてClaude、ChatGPT、Geminiを完全に同期させるための具体的なステップバイステップのワークフローを詳しく解説します。
本当の問題:なぜClaude、ChatGPT、Gemini間でコンテキストが壊れるのか
異なるAIモデルは、それぞれ異なる認知タスクに優れています。用途に最も適したツールへ個別の作業を振り分けるのは自然なことです。しかし、個々のAIプラットフォームは囲い込まれた閉じた世界です。
あるプロジェクトをChatGPTからClaudeへ移すと、新しいモデルには、あなたが先ほど下した判断に関する認識が一切ありません。ClaudeからGeminiへ移ると、基礎となるPDF文書やデータファイルは一緒に持っていけません。単一のアプリ内にある組み込みの「カスタム指示」や「プロジェクトスペース」は、その特定のエコシステムを一歩も出ない場合にしか問題を解決できません。
その結果、いくつかの構造的なワークフロー障害が生じます:
トークンの無駄:同じ巨大な文書を、異なるツールのコンテキストウィンドウに何度も投入することになります。
情報の劣化:コンテキストを打ち直すのが面倒なため、2つ目のAIツールには短く雑なプロンプトしか与えず、結果として出力の質が下がります。
バージョン管理の混乱:どのAIがプロジェクトの状態について最新の理解を持っているのか、追跡できなくなります。
コンテキストウィンドウは一時的な作業メモリです。チャット履歴は分離された検索不能なログです。どちらも、日々のワークフローのための持ち運び可能で永続的なメモリパスポートとしては機能しません。
私の2026年版、AIツール間でメモリを同期するワークフロー
持続可能なクロスAIワークフローには、データをAIモデルから切り離すことが必要です。ClaudeやChatGPTをプロジェクトの保管庫として扱うのではなく、純粋に計算エンジンとして扱ってください。ファイル、指示、コンテキストは、統合されたメモリ基盤レイヤーに置くべきです。
同期されたワークフローの全体アーキテクチャは次のとおりです:
中央集約されたプロジェクトファイル:すべてのソース文書、調査論文、データシートは、個別に各チャットインターフェースへアップロードするのではなく、1つの外部メモリ層に置かれます。
共有された長期記憶:主要なプロジェクト制約、背景情報、ユーザーの好みは永続的に保存され、必要なときだけ呼び出されます。
タスク固有のプロンプト:Claude、ChatGPT、またはGemini内のプロンプトには、その場で必要なタスク指示だけを含め、コンテキストの重い処理は統合機能を通じてシームレスに処理されます。
共有メモリ層を使う方が、あらゆるアプリで設定を重複させるよりも、圧倒的に効率的です。データポイントを1つも失わずに、AIアシスタントをその場でアップグレード、入れ替え、組み合わせられます。
実際に同期すべきものは何か
AIツール間で継続性を保つには、どの種類の情報が実際に「コンテキスト」を構成するのかを見極める必要があります。適切なメモリ層は、次の要素を捕捉し同期すべきです:
プロジェクトの背景
あなたが構築しているものの、目標、対象読者、タイムライン、主要目的といった上位レベルの情報です。これにより、AIが本来のミッションとずれた一般論の出力を生成するのを防げます。
作業ファイルとソース文書
生データ、PDF、スプレッドシート、参考資料です。これらはAIワークフローの事実上の支点となります。これらを同期することで、どのモデルもまったく同じ真実のソースを分析できます。
再利用可能な指示と好み
フォーマット規則、ブランドボイスのガイドライン、コーディング標準、AIに従ってほしい特定のフレームワークです。
過去の決定と議論の履歴
以前のAI会話であなたが導いた結論です。昨日ChatGPTが構成案を確定するのを手伝ったなら、Claudeは今日、その内容を書く前にその構成を知っている必要があります。
ドメイン知識 / 調査コンテキスト
業界特有の用語、専門データセット、ベースのAIモデルが本来は持っていないかもしれない詳細なリサーチです。
タスク固有のコンテキストと長期記憶
AIに永遠に知っておいてほしいこと(たとえば、あなたの会社のトーン)と、今この瞬間に知る必要があること(たとえば、このメールを要約すること)を分ける必要があります。構造化されたメモリ層は前者を担い、日々のプロンプトを軽量に保ち、後者に集中させます。
ステップバイステップ:MemoryLakeを使ってワークフロー全体でコンテキストを同期する方法
このクロスAIワークフローを実行するには、AIアシスタントのための持ち運び可能なメモリパスポートとして特別に設計されたシステムが必要です。MemoryLake はまさにそれとして機能します—ファイル、知識、会話履歴を異なるツール間でつなぐ、永続的でユーザー所有のメモリ層です。
ここでは、それをあなたのスタックの中核となるメモリ基盤として設定する方法を説明します。
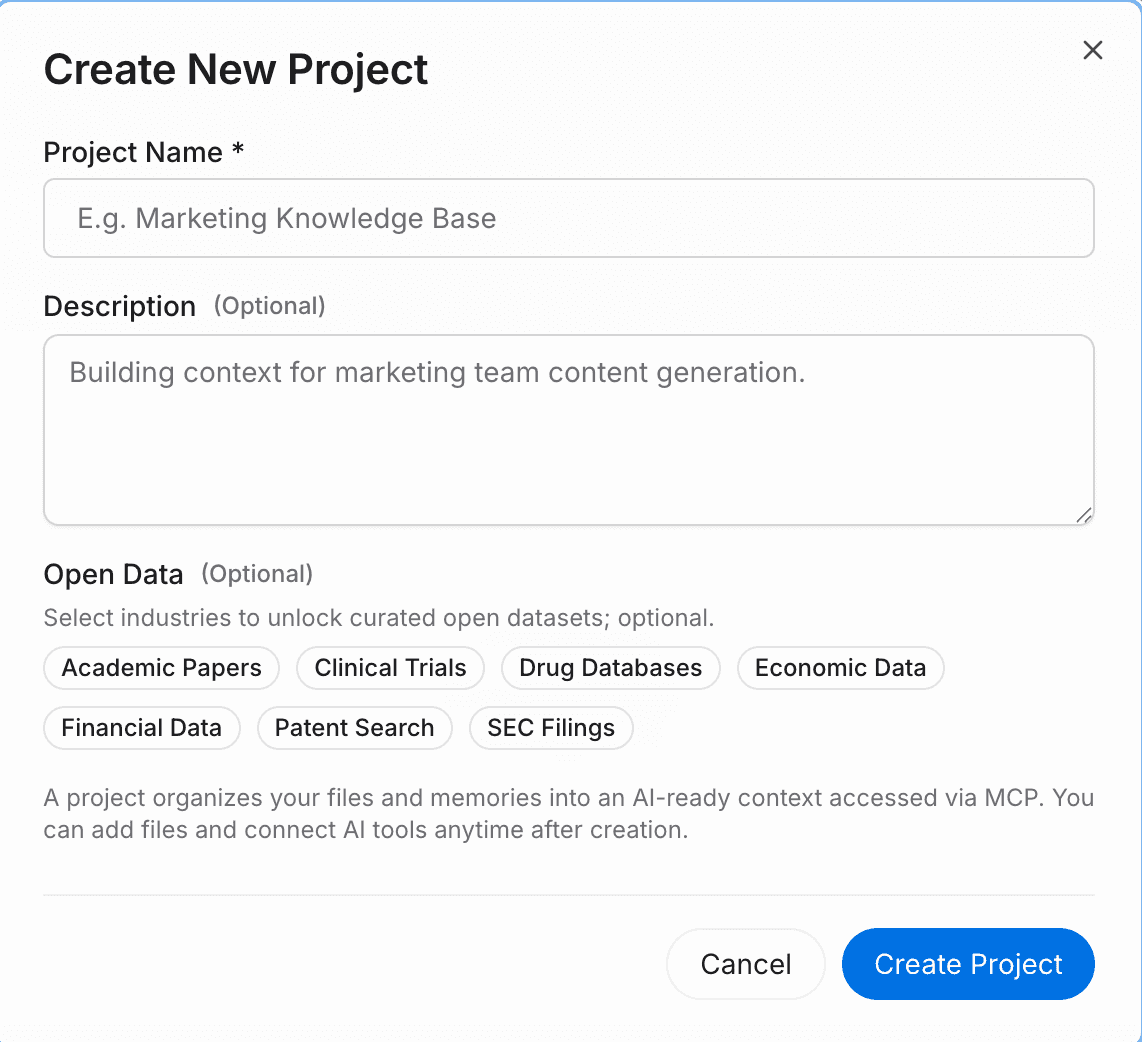
ステップ1 — プロジェクトを作成し、ファイルとデータをアップロードする
まず、取り組みのための専用ワークスペースを作成します。添付ボタンをクリックしてソース文書を直接アップロードしてください。MemoryLake が内容を自動的に解析、抽出、構造化し、すぐに取り出せるようにします。
PDF、Word、Excel、Markdownをはじめとする幅広い形式をネイティブでサポートしています。データが別の場所にある場合は、ファイルセクションに移動して外部データソースを直接接続することもできます。これにより、AIメモリは常に最新の運用データを参照し、手動で再アップロードする必要がなくなります。
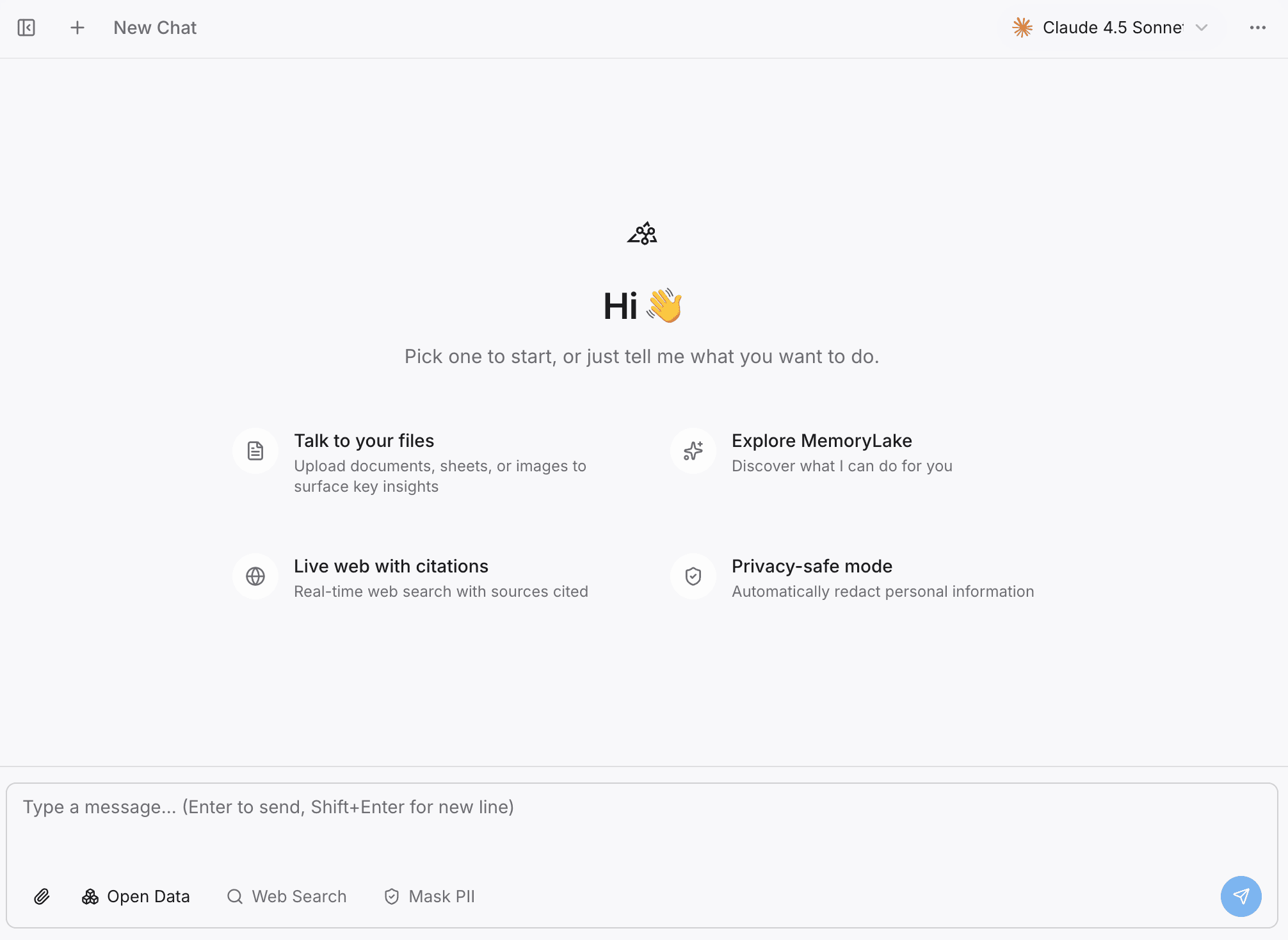
ステップ2 — プロジェクトを検索するか、チャットする
外部のAIツールを接続する前に、組み込みのPlaygroundでコンテキストを確認できます。プロジェクトに対して直接質問することで、システムが知識を正しくインデックス化できていることを確かめられます。
このステップは、MemoryLake が単なる静的なクラウドストレージではなく、検索可能で、対話可能で、非常に再利用性の高いプロジェクト用メモリ層であることを示しています。コンテキストを事前処理するため、ClaudeやChatGPTがアクセスする時点では、情報はすでにAIが理解しやすい形に最適化されています。
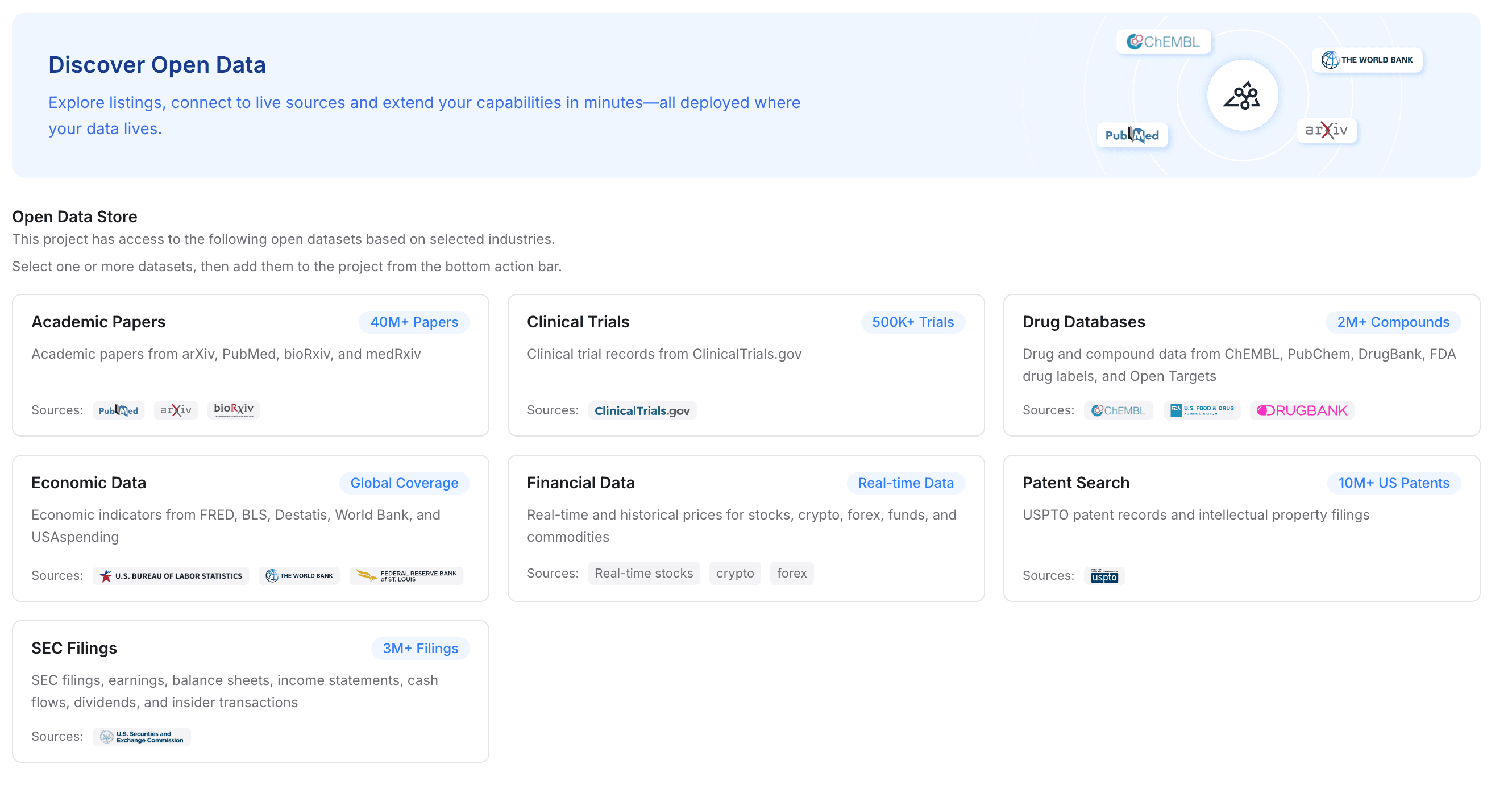
ステップ3 — オープンデータを追加してプロジェクトを強化する
ワークフローに深い専門知識が必要な場合は、プライベートファイルにオープンデータを追加して補強できます。MemoryLake では、特定の業界データセットをワンクリックでプロジェクトに追加できます。
学術論文、臨床試験、医薬品データベース、経済データ、金融記録、特許検索、SEC提出書類へのアクセスを即座に統合できます。リサーチ中心のワークフローでは、これは比類のない利点になります。Claude、ChatGPT、Gemini に、あなたのプライベートファイルと権威ある世界規模のデータセットを組み合わせた、深く強化されたコンテキスト層を与えられるからです。
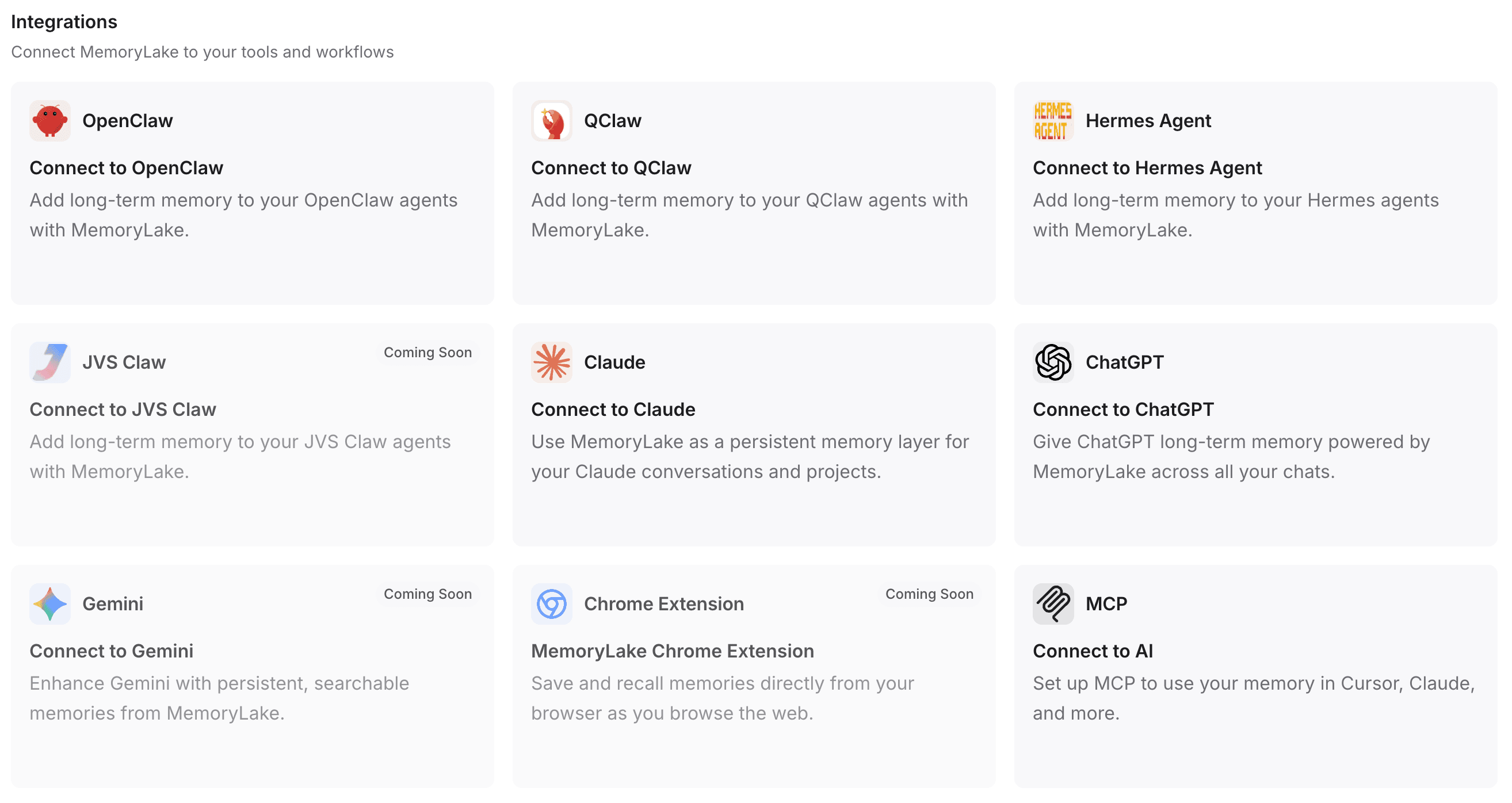
ステップ4 — MemoryLake をあなたのツールとワークフローに接続する
これは、断片化したツール群と統一されたクロスモデルAIメモリの間をつなぐ重要なステップです。この基盤を日々のアシスタントに接続することで、コンテキストを何度も貼り付け直す必要がなくなります。
まず、個人用APIキーを選択または作成します。MemoryLake は迅速な統合をサポートしています:
ワンクリックインストール:対応環境では、必要なプラグインのインストールと設定は1つのコマンドだけで完了します。
自動設定:OpenClawのようなツールを使う場合は、提供された連携ガイドラインをコピーしてクライアントに貼り付けるだけです。プラグインを自動的にインストールし、設定を完了し、ゲートウェイを再起動してくれます。
幅広い互換性:このメモリ層をChatGPT、Claude、OpenClaw、Hermes Agentなどへシームレスに流し込めます。
高度な統合:開発者や上級ユーザー向けには、MCP(Model Context Protocol)またはネイティブAPIエンドポイント経由でプログラム的に接続することで、カスタムスクリプトやエージェントもまったく同じメモリパスポートを共有できます。
メモリが同期されたあと、Claude、ChatGPT、Gemini の役割分担はこうする
MemoryLake が永続的なコンテキストを担うようになれば、マルチモデル生産性の摩擦は消えます。ファイルも背景知識も、どこからでもアクセス可能になります。エコシステム全体でタスクを自信を持って分担する方法は次のとおりです:
Claude は、詳細な下書きと推論に使う:メモリ層が構成案とソースPDFを提供してくれるので、Claude は大量の文章生成、複雑なコーディングアーキテクチャ、ニュアンスのある分析的な執筆に最適です。
ChatGPT は、反復、整形、発想出しに使う:同じメモリ空間に接続して、代替案を素早くブレインストーミングしたり、Claudeが解析したデータを整形したり、高度な推論モデルを使ってデータ分析を行えます。
Gemini は、マルチモーダルなタスクとエコシステムの照合に使う:永続的なメモリに接続したGeminiを使えば、Google Workspace のライブ文書、Web検索、複雑なマルチモーダル入力とプロジェクトデータを相互参照できます。
目標は、どれか1つのモデルを絶対的な勝者と宣言することではなく、同じ統合された脳にアクセスする交換可能な作業者としてモデル群を設計することです。
それでもマルチAIワークフローを壊してしまうよくあるミス
複数のツールにアクセスできても、多くのユーザーは旧来の習慣にしがみつくことで生産性を自滅させています。次の落とし穴を避けてください:
あらゆるプロンプトを詰め込む:毎回の新しいチャットウィンドウに背景情報を1万語も手で貼り付けるのは、時間の無駄であり、コンテキストウィンドウを肥大化させ、モデルの注意を散漫にします。
1つのチャットウィンドウに依存する:1本の無限に続くチャットスレッドを「プロジェクトデータベース」とみなすと、AIが以前の指示を忘れたり、過去の決定を幻覚で補ったりするのは避けられません。
長期記憶とタスクコンテキストを区別しない:2文のツイートを書くためだけに、50ページのブランドガイドラインをAIに読ませるのは非効率です。
ファイルをツールごとにばらばらに置く:CSVをChatGPTに、関連するPDFをClaudeにアップロードすると、2つのモデルが矛盾した助言を返すのは確実です。
構造化されたプロジェクト知識がない:生データを整理せずにAIへ投げると、まともな検索ができません。
チャット履歴を再利用可能な知識層として扱う:昨日AIと話した内容は、構造化された対話であって、信頼できる持ち運び可能なナレッジベースではありません。
メモリ層 vs チャット履歴 vs コンテキストウィンドウ
マルチモデルAIの生産性セットアップを使いこなすには、AIが情報をどう扱うかという技術的な違いを理解しなければなりません。
コンテキストウィンドウ(RAM):これは、単一のやり取り中における特定のAIモデルの能動的な短期記憶です。トークン上限によって制限されます。上限を超えると、AIは最初に与えられた情報から「忘れ」始めます。
チャット履歴(ログ):あなたが入力した内容とAIの回答の履歴記録です。特定のアプリ(たとえばChatGPTのサイドバー)の中に閉じ込められています。実質的には死んだテキストであり、他のツールでは検索できず、ClaudeやGeminiには役立ちません。
メモリ層(ハードドライブ):ファイル、知識、コンテキストを特定のAIツールに依存せずに保存する、永続的で構造化された基盤(MemoryLake のようなもの)です。検索可能で、対話可能で、AIスタック全体で完全に持ち運び可能です。
このワークフローが最も向いている人
永続的なコンテキストのワークフローは、出力の正確性、一貫性、深い調査に依存する専門家に強く推奨されます:
研究者・アカデミア:同じ膨大な論文群やデータセットを、ナラティブの筋を失わずに複数のAIモデルで分析する必要がある人。
創業者・オペレーター:あるAIでは財務モデリング、別のAIではマーケティングコピー、さらに別のAIではプロダクト戦略を扱うなど、すべてに同じビジネスコンテキストが必要な人。
コンサルタント・アナリスト:複数のクライアント向けに、区別された極めて機密性の高いプロジェクトを管理し、AIツールキット全体をまたいで移動できる、厳格に分離されたメモリ空間が必要な人。
プロダクトチーム:技術文書、ユーザーフィードバック、ロードマップをまたいで共有コンテキストが必要で、どのAIアシスタントも古い仕様で動かないようにしたい人。
日常的にAIを使い倒す人:同じプロンプトをさまざまなチャットインターフェースに延々とコピー&ペーストする無限ループに疲れている人。
最後に
クロスAI生産性の本当の秘訣は、モデルそのものが消耗品だと理解することです。今日Claudeがコーディングに最適でも、明日は新しいChatGPTの更新がそれを上回るかもしれませんし、来週にはGeminiがマルチモーダル推論で突破口を開くかもしれません。
もしワークフロー、ファイル、プロジェクトコンテキストがこれらツールのうち1つのチャットインターフェースに閉じ込められているなら、移行と断片化の摩擦に絶えず直面することになります。真のマルチモデル効率は、各アシスタントに「あなたを覚えておく」よう強いることでは実現しません。触れるすべてのツールに対して単一の真実の源として機能する、高度に整理され、簡単にアクセスでき、完全に持ち運び可能なメモリ層を確立することによって実現します。
もしワークフローが繰り返されるコンテキスト切り替えで崩れ始めているなら、MemoryLake のような持ち運び可能なメモリシステムが、あなたのスタック全体を大幅に使いやすくしてくれます。ファイルを一元化し、オープンデータを接続し、その知識をClaude、ChatGPT、Geminiへシームレスに流し込むことで、ようやくAIコンテキストを自分のものとして管理できるのです。
よくある質問
Claude、ChatGPT、Gemini間でコンテキストを同期するにはどうすればよいですか?
異なるAIツール間でコンテキストを同期するには、データをAIモデルから切り離す必要があります。サードパーティのメモリ基盤レイヤーを使ってプロジェクトファイル、指示、背景知識を保存し、APIまたはMCPの統合を通じてClaude、ChatGPT、Geminiに接続してください。
Claude、ChatGPT、Geminiはメモリを共有できますか?
ネイティブでは、できません。これらは分離されたエコシステムの中に存在します。ただし、3つすべてのツールが同時にアクセスできる中央集約型ナレッジベースとして機能する外部の持ち運び可能なAIメモリ層を使えば、メモリを共有できます。
AIツール間でコンテキストを再利用する最善の方法は何ですか?
最善の方法は、テキストを貼り付けるのをやめ、代わりに専用のメモリシステム内に構造化されたプロジェクトワークスペースを作ることです。ファイルをアップロードし、指示を一度だけ定義しておけば、新しいタスクを始めるたびに、任意のAIアシスタントからそのデータベースを参照できます。
別のAIアプリで同じプロンプトを繰り返さないようにするにはどうすればよいですか?
中核となるシステムプロンプト、ブランドガイドライン、プロジェクトフレームワークを、永続的なメモリ層に保存してください。異なるアプリを使うときは、必要な背景情報を外部メモリから呼び出す最小限のプロンプトだけを書けば十分です。
複数のAIアシスタント間でメモリを保存できるツールは何ですか?
MemoryLake のような、クロスモデル向けメモリ基盤として特別に設計されたツールは、ファイル、オープンデータ、会話コンテキストを1か所に保存でき、AIスタック全体に対する सार्व用のメモリパスポートとして機能します。
チャット履歴だけでマルチAIワークフローは十分ですか?
いいえ。チャット履歴は、会話が行われた特定のプラットフォームに固定されています。別のモデルへ動的にエクスポートできないため、ChatGPTからClaudeやGeminiへ切り替える際の継続性維持には役立ちません。
ファイルを1回アップロードして、複数のAIツールで使うにはどうすればよいですか?
ソース文書(PDF、スプレッドシート、Markdown)を、外部のAPIアクセス可能なメモリ層にアップロードしてください。文書がそのシステムで解析されベクトル化されたら、連携機能を使って複数のAIツールに同じファイルリポジトリを問い合わせさせることができます。
コンテキストウィンドウ、チャット履歴、メモリ層の違いは何ですか?
コンテキストウィンドウは、単一のプロンプトに対するAIの一時的な処理能力です。チャット履歴は、過去のやり取りを記録した分離されたテキストログです。メモリ層は、ファイルとコンテキストを構造化し、あらゆるAIツールから सार्व用にアクセスできる、永続的で持ち運び可能なユーザー所有のデータベースです。