PDF、Excel、研究メモリを保存して、AIが毎回最初からやり直さないようにする方法

はじめに
AI を 文書レビュー、財務分析、または 学術研究に使っているなら、同じ PDF や Excel スプレッドシートを何度も何度も AI アシスタントにアップロードする、もどかしいサイクルに心当たりがあるはずです。新しいセッションを始めるたびに、AI は「健忘症」になってしまいます。昨日アップロードした50ページの研究論文を忘れ、財務モデルの文脈を見失い、プロジェクトの目的をゼロから説明する必要があるのです。
なぜこのようなことが起こるのでしょうか。多くの AI ツールは、ファイルのアップロードを永続的な知識ではなく、一時的な文脈として扱います。これらのシステムはその場で情報を処理するのは得意ですが、長期的な保持のための専用インフラを備えていません。
本当に賢いワークフローを構築するには、その場限りのファイルアップロードから、永続的なメモリ層へ移行する必要があります。このガイドでは、標準的な AI チャットボットがなぜファイルで毎回やり直しになるのか、そして MemoryLake—永続的な AI メモリインフラ—を使って、文書、スプレッドシート、調査資料のために再利用可能で検索可能、かつ耐久性のあるメモリワークフローをどのように構築するかを説明します。
クイックアンサー
AI のために PDF、Excel、研究メモリを保存するとはどういう意味ですか?
それは、一時的なファイルアップロードから離れ、文書が継続的に保存・ベクトル化・構造化され、複数のセッションやツールをまたいで AI が継続的に取得できる永続的なメモリインフラを確立することを意味します。
なぜ AI は通常、毎回やり直しになるのですか?
AI モデルは厳しいコンテキストウィンドウの制限の中で動作します。セッションが終了したり、コンテキストウィンドウがいっぱいになったりすると、アップロードしたファイルの一時的なメモリは消去されます。標準的なチャット履歴はテキストを保持しますが、複雑なファイルを将来の確実な取得のために永続的にインデックス化することはできません。
MemoryLake はこれをどのように解決しますか?
MemoryLake は永続的な AI メモリインフラ層として機能します。ファイルを何度も再アップロードする代わりに、1回だけ MemoryLake のプロジェクトにアップロードします。プラットフォームは PDF、Excel ファイル、研究データを自動的に処理し、API または MCP を介してワークフロー、エージェント、チャットボットに直接接続できる耐久性のあるメモリ層へ変換します。これにより、AI が毎回やり直す必要がなくなります。
なぜ AI は PDF、Excel ファイル、研究で毎回やり直すのか
AI の健忘症問題を解決するには、まず多くの AI プラットフォームが現在どのようにファイルとメモリを扱っているのか、その限界を理解する必要があります。
チャット履歴 ≠ 耐久的なメモリ
多くのユーザーは、AI が3つ前のプロンプトで言ったことを覚えているなら「学習している」と考えがちです。しかし、チャット履歴は単なるテキストの直列ログにすぎません。会話スレッドが長くなりすぎると、最初の方の文脈は AI のアクティブメモリから押し出されます。複雑なファイルのための、構造化された検索可能なデータベースではないのです。
その場限りのファイルアップロード ≠ 再利用可能なメモリシステム
標準的なチャットボットのインターフェースに PDF や Excel ファイルをドラッグ&ドロップすると、そのシステムはその特定の会話のために一時的に読み込みます。新しいチャットウィンドウを開いた瞬間、そのファイルは消えます。そのため、調査中心のワークフローは、アップロード、処理待ち、再プロンプトという反復的なループに陥ります。
標準的な RAG ≠ プロジェクトメモリ層
Retrieval-Augmented Generation(RAG)は、大規模データベース内で関連するテキスト断片を見つけるのに非常に優れています。しかし、基本的な RAG の構成は、しばしば分離されていて非常に技術的です。検索性は提供しますが、ファイル、会話の文脈、構造化データが複数のユーザーセッションや AI エージェントをまたいで一体的に共存する、包括的なプロジェクトメモリ層へ自動的に変換されるわけではありません。
より良いメモリワークフローとは
AI に毎回やり直しさせないためには、メモリをインフラとして扱うワークフローが必要です。より良く、永続的なメモリワークフローには次の要素が必要です。
プロジェクト単位のメモリ: 情報はプロジェクトごとにまとめられ、関連する PDF、スプレッドシート、研究コンテキストが1つの専用スペースに存在します。
再利用可能な文脈: ファイルは正確に1回だけアップロード・処理します。その後は、そのプロジェクトに接続された任意の AI ツールが即座に洞察へアクセスできます。
ファイル量の多い知識への対応: システムは、Excel の表形式データや学術 PDF の複雑なレイアウトを含む、複雑な形式を正確に解析できなければなりません。
ツール非依存性: メモリは特定のチャットボットの中に閉じ込められるべきではありません。使っているツール(ChatGPT、Claude、カスタムエージェントなど)に API や MCP 経由で接続できる必要があります。
ステップごと: MemoryLake を使って PDF、Excel、研究メモリを保存する方法
MemoryLake は、ファイル、会話、プロジェクトコンテキストのために特別に設計された永続的なメモリインフラとして位置づけられています。生の知識入力と継続中の AI ワークフローの間のギャップを埋めます。
以下は、MemoryLake を使って永続的なメモリワークフローを確立するためのステップバイステップガイドです。
ステップ1: プロジェクトを作成し、ファイルとデータをアップロードする
同じことを繰り返さないためには、まず専用のメモリコンテナを作成する必要があります。
MemoryLake にログインし、新しいプロジェクトを作成します(例:「Q3 市場調査」)。
添付ボタンをクリックしてローカルファイルをアップロードします。MemoryLake は内容を自動的に分析し、チャンク化し、記録します。
このプラットフォームは、PDF、Word、Excel、Markdown など幅広い文書形式に対応しています。
データが別の場所にある場合は、ファイルセクションに移動して外部データソースを接続することもできます。これにより、すべての調査資料が1つの統合されたプロジェクトメモリに流れ込みます。
ステップ2: Playground でプロジェクトを検索し、チャットする
このメモリを外部ツールに統合する前に、AI がファイルの文脈を正しく理解していることを確認すべきです。
MemoryLake プロジェクト内の組み込み Playground を開きます。
アップロードした複雑なデータについて直接質問します(例:「アップロードした Excel モデルに記載されている財務リスクを要約してください」)。
検索、チャット機能、文脈理解をテストします。
これを行うことで、コアコンセプトを証明しています。つまり、プロジェクトの知識はもはや再アップロードを要求するのではなく、実際に再利用されているのです。
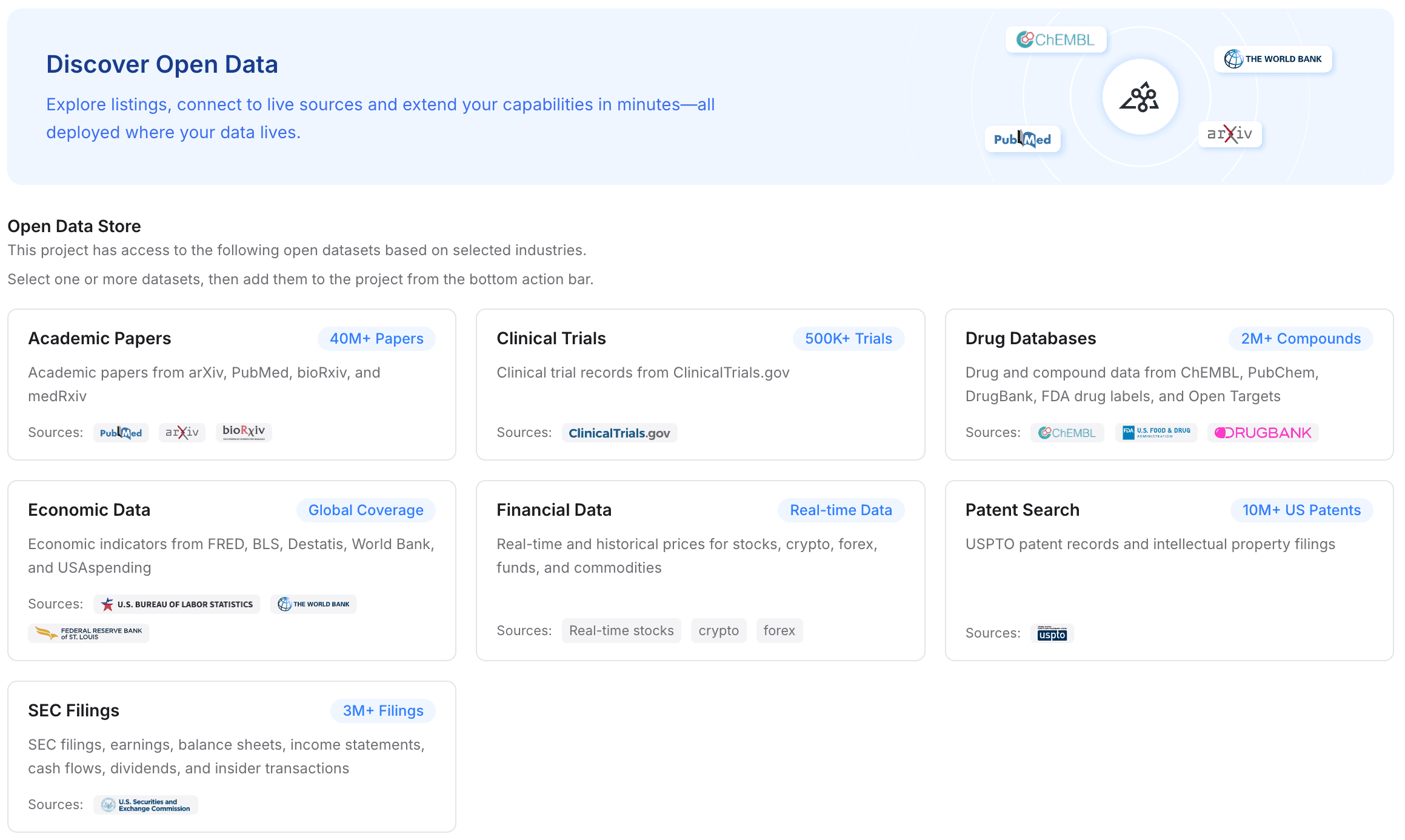
ステップ3: オープンデータを追加してドメイン知識を強化する
強力なメモリ層は、単に個人のファイルを保存するだけではありません。より広い業界知識と組み合わせて文脈化します。MemoryLake を使えば、公開データセットを手動で探してアップロードするのではなく、オープンデータでプロジェクトメモリを強化できます。
プロジェクト内のデータセットセクションに移動します。
1回のクリックで、無料で高品質な業界データセットをプロジェクトのメモリに直接追加できます。
利用可能なデータタイプには、学術論文、臨床試験、医薬品データベース、経済データ、金融データ、特許検索、SEC 提出書類が含まれます。
プライベートな PDF/Excel ファイルとこれらのオープンデータセットを組み合わせることで、AI アシスタントは公開 SEC 提出書類を自分でダウンロードしてアップロードすることなく、深く専門的なドメイン知識を即座に獲得します。
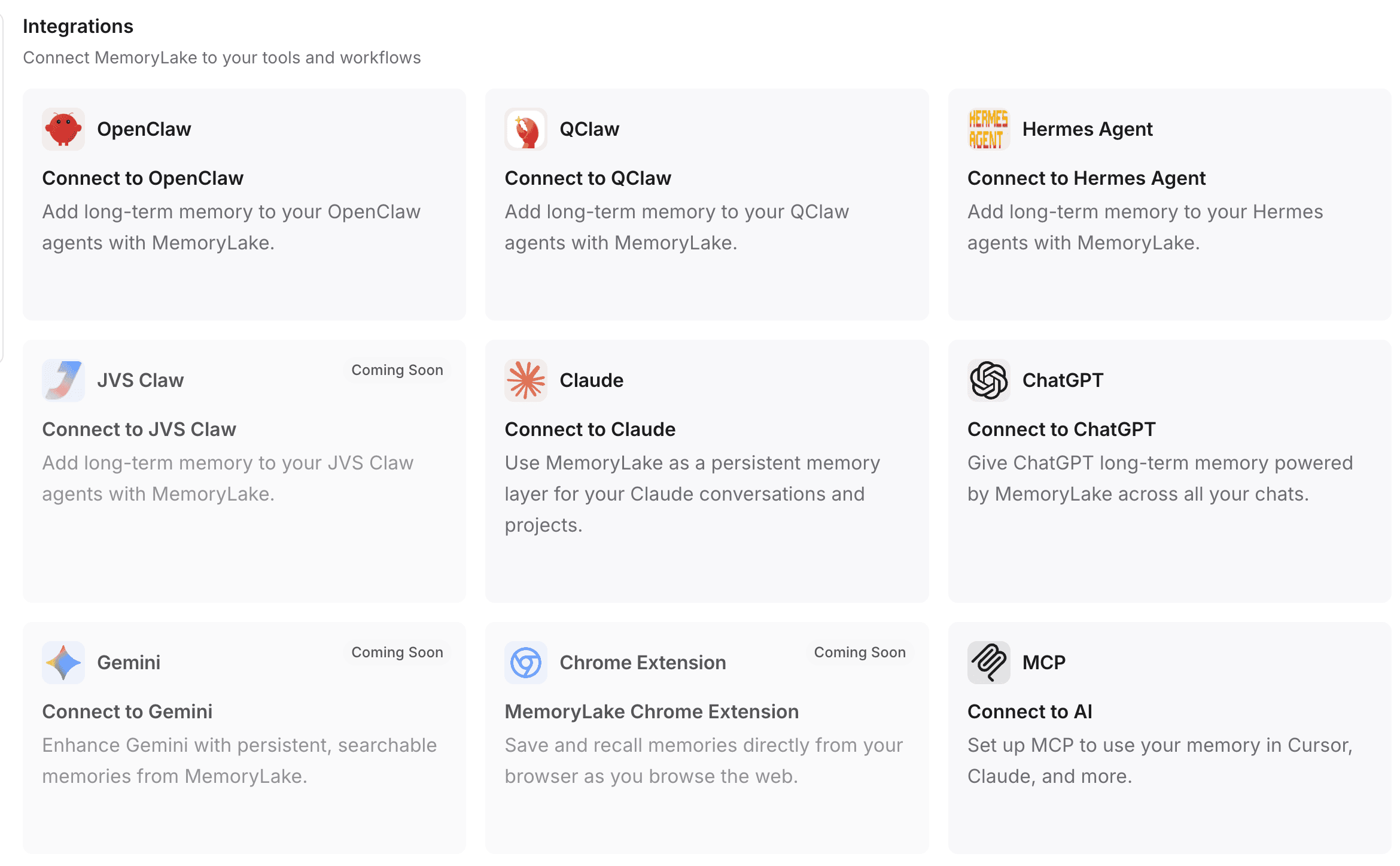
ステップ4: MemoryLake をツールやワークフローに接続する
メモリは、実際に使うツールと接続して初めて有用です。MemoryLake は、日々の AI ワークフローに直接組み込めるよう設計されています。
プロジェクト設定に進み、独自の API キーを選択または作成します。
ワンコマンドインストール: 多くの連携では、プラグインを即座に起動して使えるようにするためのワンコマンドインストールフローをサポートしています。
自動設定(例: OpenClaw): OpenClaw のようなプラットフォームを使っている場合、提供されたセットアップ手順をそのままコピーして OpenClaw のインターフェースに貼り付けるだけです。OpenClaw は必要なプラグインを自動的にインストールし、プロジェクト設定を構成し、ゲートウェイをシームレスに再起動します。
幅広い互換性: この永続的なメモリは、ChatGPT、Claude、OpenClaw、Hermes Agent などの一般的なインターフェースに直接ルーティングできます。
プログラムによるアクセス: 開発者や AI エージェントビルダー向けに、MemoryLake は MCP(Model Context Protocol)と API を通じてバックエンドシステムに深く統合でき、カスタムボットに耐久的な長期メモリ層を提供します。
ファイルから再利用可能な AI メモリを構築するベストプラクティス
ファイル単位ではなく、プロジェクト単位で整理する: すべての文書を1つの巨大なグローバルメモリプールに放り込まないでください。文脈を明確に分け(例:「競合分析」対「人事ポリシー」)、高品質な検索を確保します。
メモリを単なるクラウドストレージではなく、再利用可能な文脈として扱う: 目的は PDF をバックアップすることだけではありません。会話可能にすることです。アップロードするファイルが、これから尋ねる質問に関連していることを確認してください。
個人ファイルとドメインデータセットは慎重に組み合わせる: SEC 提出書類や学術論文のようなオープンデータを使って社内の Excel ファイルを補完し、対象テーマの全体像を AI に与えます。
最初からワークフロー統合を意識する: サイロの中でメモリを作らないでください。初日から、このメモリをどこで利用可能にするのかを計画しましょう。Claude でも ChatGPT でも、あるいはカスタムの社内エージェントでも構いません。
長期メモリと一時的な文脈を見極める: 文書が短い書式修正のためだけに必要なら、標準的なチャットアップロードで十分です。数か月にわたって参照する基礎的な研究論文なら、MemoryLake に入れるべきです。
避けるべきよくある間違い
チャット履歴だけに頼る: ChatGPT のスレッドを6か月開いたままにすることが、研究を保存する実用的な方法だと考えること。(最終的には壊れるか、遅くなるか、忘れます)。
同じファイルを繰り返しアップロードする: 毎週月曜の朝に同じ PDF をドラッグ&ドロップして、トークン、計算リソース、自分の時間を無駄にすること。
RAG と耐久的なメモリを混同する: 基本的な Python の RAG スクリプトを作れば、永続的で複数エージェントのプロジェクトメモリというユーザー体験の問題が解決すると考えること。
スプレッドシートや PDF をただのテキストの塊として扱う: Excel ファイルには行、列、関係性があります。標準的なチャットボットはアップロード時にこのデータをしばしば崩してしまいます。専用のメモリ層なら、表形式データや構造化データを正確に解析します。
メモリを実際のツールに運用化しない: 優れたデータベースを作ったのに、チームが実際に使うツールへ API や MCP を通じて接続しないこと。
このワークフローを使うべき人
この永続的なメモリワークフローは、次のような人に強く推奨されます。
研究者・学者: 数か月にわたるプロジェクトで、数十本の密度の高い学術論文を検索する必要がある人。
財務アナリスト: 複雑な Excel モデルや過去の SEC 提出書類を、文脈を失わずに AI に記憶させたい人。
AI エージェントビルダー: 信頼性が高く、耐久性のある文脈を必要とする、長時間稼働する自律型アシスタントを開発している人。
知識集約型チーム: 法務、医療、コンサルティングなど、大量の相互接続されたファイルを日々扱うチーム。
開発者: 複雑な RAG パイプラインをゼロから構築するのではなく、API/MCP 経由で接続できる既製のメモリインフラを求める人。
結論
コンテキストウィンドウの制限、トークン制約、AI の健忘症と常に戦っているなら、解決策はより良いプロンプトを書くことではありません。解決策は、AI がファイルを扱う方法を変えることです。
複雑な PDF、Excel スプレッドシート、深い調査資料を、基本的なチャット履歴やその場限りのアップロードで AI が覚えていられると期待しても、結局は毎回やり直しになります。本当に賢く、長く動くワークフローを構築するには、永続的なメモリ層を実装する必要があります。
MemoryLake を活用すれば、一時的なファイルアップロードを、耐久的で再利用可能なプロジェクトメモリへ変換できます。学術論文や SEC 提出書類のようなオープンデータセットで社内文書を強化する場合でも、Claude、ChatGPT、OpenClaw のようなツールにこのメモリをシームレスに接続する場合でも、MemoryLake は AI が知識を保持できるようにします。毎回やり直すのはやめて、長く続くメモリを備えた AI ワークフローの構築を始めましょう。
よくある質問
セッションをまたいで AI に PDF ファイルを覚えさせるにはどうすればよいですか?
AI に PDF をセッションをまたいで覚えさせるには、標準的なチャットインターフェースから離れ、MemoryLake のような永続的なメモリ層を使う必要があります。PDF を専用プロジェクトにアップロードすると、ファイルは処理されて永続的に保存され、接続された任意の AI ツールが将来のセッションで再アップロードなしに文脈を取得できるようになります。
Excel スプレッドシートを再アップロードせずに AI に覚えさせることはできますか?
はい、ただし標準的なチャット履歴ではありません。AI メモリインフラを利用することで、Excel ファイルは構造化されたプロジェクトメモリとして解析・保存されます。これにより、AI は将来いつでも特定のセル、傾向、表形式データを参照できます。
研究メモリワークフローには RAG だけで十分ですか?
RAG(Retrieval-Augmented Generation)は文書を検索する技術的能力を提供しますが、基本的な RAG だけではシームレスな研究ワークフローには不十分なことが多いです。ユーザーには、文書解析、会話文脈、オープンデータセット統合、そして実際のチャットインターフェースへの簡単な API/MCP 接続を組み合わせた完全なプロジェクトメモリ層が必要です。
AI のために研究メモリを保存する最善の方法は何ですか?
最善の方法は、データをプロジェクトごとに整理し、マルチモーダルなファイル形式(PDF、Markdown、Excel)をサポートし、公開データセット(臨床試験や学術論文など)で個人の研究を強化できる永続的なメモリインフラを使うことです。
MemoryLake は OpenClaw や Claude のようなツールとどのように連携しますか?
MemoryLake はこれらのツールの外部「脳」として機能します。API キーを設定するか、OpenClaw のようなツールにセットアップ手順を直接貼り付けることで(OpenClaw はプラグインの自動インストール、設定、ゲートウェイ再起動を行えます)、LLM が耐久的なプロジェクトメモリに直接アクセスできるようになります。
MemoryLake は API や MCP 経由で接続できますか?
はい。MemoryLake は従来の API と Model Context Protocol(MCP)の両方を通じたプログラム統合をサポートしており、カスタム AI エージェントやエンタープライズアプリケーションを構築する開発者にとって非常に柔軟です。
なぜ AI は文書で毎回やり直すのですか?
標準的な AI モデルには、局所的な長期記憶がありません。代わりに一時的なコンテキストウィンドウに依存しています。チャットが終了するかトークン上限に達すると、アップロードされた文書は新しい入力のための空きを作るためにアクティブメモリから消去されます。