OpenClawからHermes Agentへ、ワークフローやメモリを失わずに移行する方法

はじめに
OpenClaw から OpenClaw のような新しい環境へ Hermes Agent に移行することは、AI 機能を強化したいチームにとって、しばしばわくわくする一歩です。しかし、切り替えを決めた途端、すぐに苛立たしい壁にぶつかります。新しいエージェントは完全に空っぽだからです。
コンテキストを失わずに AI ツールを切り替えることは、現代のAIワークフローにおける最大の課題の一つです。AI エージェントの賢さは、単に基盤となるモデルだけから生まれるわけではありません。アップロードした文書、学習した好み、そして何百回ものやり取りを通じて積み上げてきた固有の文脈から生まれます。
OpenClaw から Hermes Agent へ、プロジェクトを最初からやり直さずに移行したいなら、AIワークフローの継続性を確保する戦略が必要です。このガイドでは、標準的な移行方法がなぜ失敗するのか、移行時に実際には何が失われるのか、そして作業をそのまま維持するためにポータブルなメモリ層をどう使うのかを説明します。
すぐに答え: OpenClaw から Hermes Agent へ移行する方法
ワークフローや記憶を失わずに OpenClaw から Hermes Agent へ移行するには、手動のコピーペーストや単純なチャット履歴のエクスポートに頼るのは避けるべきです。その代わりに、ポータブルなAIメモリ層を使って、データを特定のエージェントから切り離すのが最も効果的です。
ワークフローの継続性を確保するための最適な手順は次のとおりです:
中核となるコンテキストを抽出する: OpenClaw から、よく使う文書、進行中の調査、構造化されたメモを集めます。
永続的なメモリ層に集約する: これらのファイル(PDF、Word、Excel)を、MemoryLake のようなツール非依存のメモリ基盤にアップロードします。
関連するデータセットで強化する: 文脈の不足を補うために、業界特化のオープンデータ(例: 学術論文や財務提出書類)を追加します。
メモリを Hermes Agent に接続する: API キー、プラグイン、または Model Context Protocol (MCP) を使って、この永続メモリを Hermes Agent に直接ルーティングし、過去のワークフローへ即座にアクセスできるようにします。
AIエージェントの移行が見た目以上に難しい理由
ツールの切り替えは通常、Point A から Point B へデータを移すことを意味します。しかし、AI エージェントはデータを従来のデータベースのようには扱いません。多くの AI プラットフォームでは、メモリとコンテキストは特定のチャットセッションや独自のワークスペース内に強くサイロ化されています。
Hermes Agent へ移行するとき、移しているのはファイルだけではありません。移そうとしているのは理解そのものです。ワークフローが、AI が法的案件の背景やコードベースの設計判断、週次レポートの書式ルールを把握していることに依存しているなら、新しいツールへの移行は通常、その理解をゼロに戻すことを意味します。「ツールを切り替えること」と「継続性を維持すること」は、まったく別の技術課題です。
一般的な OpenClaw → Hermes Agent 移行で失われるもの
ユーザーが直接移行を試みると、置き去りにしていく目に見えない作業の膨大さを見落としがちです。適切な移行戦略がなければ、次のものを失う可能性が高いです:
アップロードした文書とファイル: OpenClaw に与えて回答の根拠とした PDF、CSV、社内文書のすべて。
以前のコンテキストとニュアンス: エージェントがあなたのプロジェクト目標について蓄積した、微妙な指示や背景知識。
ワークフローメモリ: あなた特有のリクエストを処理するときに、エージェントが学習した一連の手順。
構造化された知識: 以前のセッションで生成された結論、要約、統合メモ。
タスク履歴: すでに試したこと、失敗したこと、次の手順が何かという一連の流れ。
一般的な移行方法が行き詰まる理由
多くのユーザーは、AI 移行を力ずくで乗り切ろうとします。ここでは、一般的な手動方法がワークフローの維持に失敗する理由を説明します:
1. 手動のコピーペーストとプロンプト詰め込み
OpenClaw から最高のプロンプトや過去の会話をコピーして Hermes Agent に貼り付けるのは、スケーラブルなワークフローではありません。プロンプト詰め込み——毎回の新しいプロンプトに延々と背景文を詰め込むこと——はトークン上限を圧迫し、コストを増やし、しばしば新しいエージェントを混乱させます。
2. バラバラなメモのエクスポート
チャットログをテキストファイルや JSON としてエクスポートすると、自分のデータを所有している気分になるかもしれませんが、Hermes Agent の助けにはなりません。過去の会話を生のテキストで吐き出しただけでは、新しいエージェントがリアルタイムで解析し、効果的に使うのは非常に困難です。
3. ファイルを一つずつ再アップロードする
OpenClaw に何十もの参考文書があったなら、それらを Hermes Agent に手動で再アップロードするのは面倒です。さらに、将来またエージェントを切り替えるなら、まったく同じ作業を繰り返さなければなりません。
解決策: ポータブルな AI メモリ層へ移行する
AI ツールで何度も最初からやり直すのをやめるには、発想を変える必要があります。メモリを新しいエージェントに移そうとするのではなく、メモリそのものをエージェントの外へ移すべきです。
そこで登場するのが、ポータブルな AI メモリ層という概念です。MemoryLake のようなツールは、AI システム向けの永続的なメモリ基盤として機能するよう設計されています。単なるチャット履歴の記録ツールや基本的なファイルアップローダーではありません。公開ドキュメントでは、ツール、モデル、エージェントをまたいで使える「第二の脳」あるいは「メモリパスポート」と位置づけられています。
永続メモリ層を使うことで、文書、コンテキスト、過去の作業は中央集約された管理されたハブに置かれます。OpenClaw、Hermes Agent、Claude、ChatGPT のいずれを使っていても、エージェントはこのメモリ層に接続するだけで、必要なものを正確に取得できます。
ステップごと: MemoryLake を使ってワークフローとメモリを保持する
Hermes Agent への移行を計画しているなら、ワークフローの継続性を確保し、データ損失を防ぐために MemoryLake を使う実践的なステップバイステップガイドを紹介します。
ステップ1: プロジェクトを作成し、過去のデータをアップロードする
最初のステップは、OpenClaw のサイロからコンテキストを救い出すことです。MemoryLake では、この特定のワークフローの永続的な拠点となる専用プロジェクトを作成します。
操作: MemoryLake の添付ボタンをクリックして、以前 OpenClaw で使っていた元文書をアップロードします。
詳細: PDF、Word、Excel、Markdown などの形式に対応しています。MemoryLake はこのコンテンツを自動的に解析し、AI が取得しやすい形に構造化します。
外部ソース: OpenClaw のワークフローがライブデータに依存していた場合は、ファイルセクションを使って外部データソースを直接接続できます。
重要な理由: ファイルを Hermes Agent にアップロードして再び閉じ込められるよりも、再利用可能な層にアップロードすることになるからです。
ステップ2: Playground でコンテキストをテストする
ワークフローを Hermes Agent に完全移行する前に、メモリが損なわれておらず、正確に取り出せることを確認したいはずです。
操作: MemoryLake Playground を開き、プロジェクトへの問い合わせを始めます。
詳細: 以前 OpenClaw に尋ねていたのと同じ複雑な質問をしてみてください。
重要な理由: これにより、文書コンテキストと過去の知識が正しく解析され、次のエージェントに提供できる状態になっていることが確認できます。
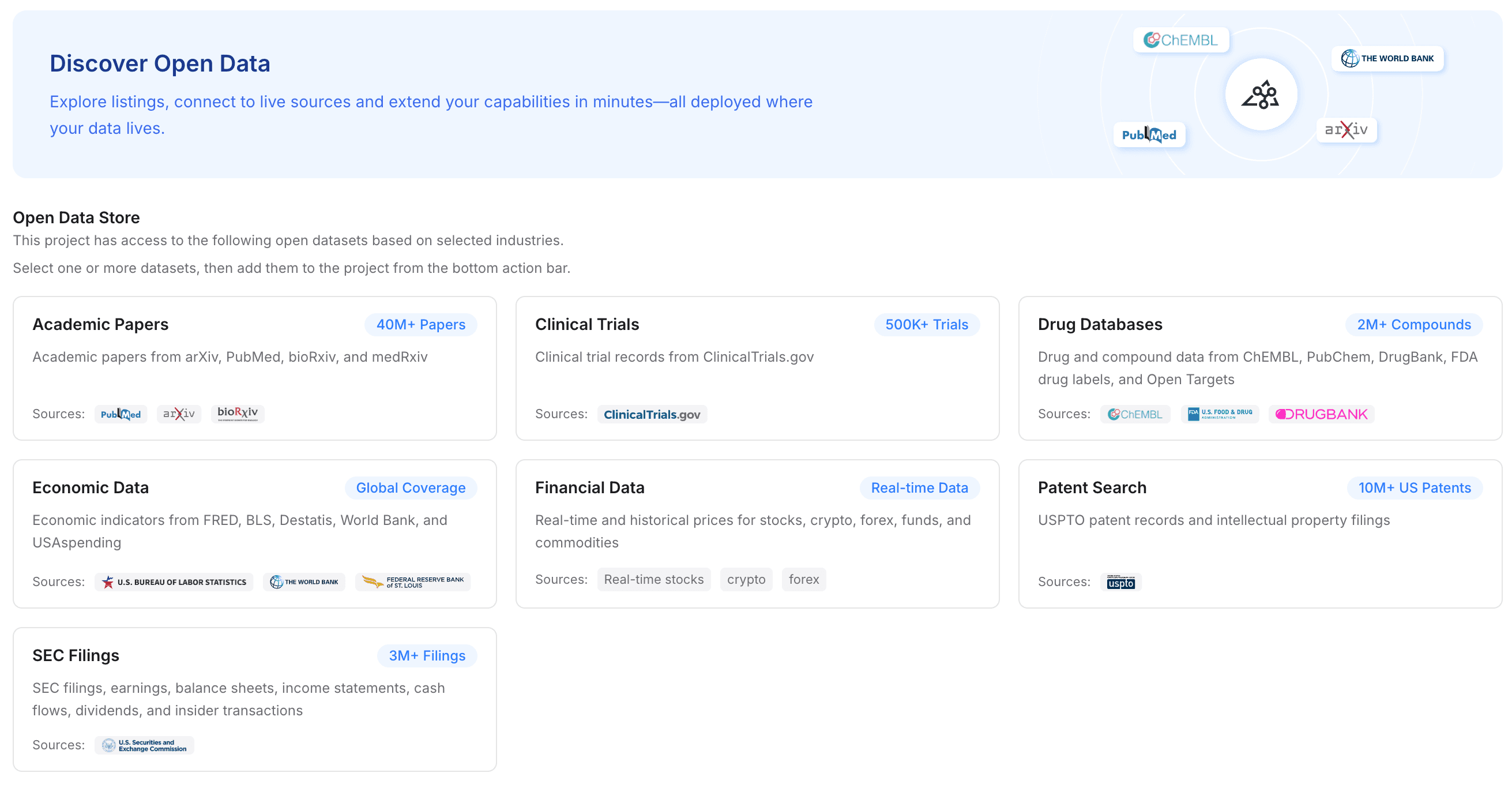
ステップ3: オープンデータでプロジェクトを強化する
移行は、エージェントの能力を高める絶好の機会です。MemoryLake では、プライベートにアップロードした内容に、より広範な業界知識を補えます。
操作: オープンデータのオプションに移動し、関連する業界データセットをプロジェクトに追加します。
詳細: 分野に応じて、学術論文、臨床試験、医薬品データベース、経済データ、財務データ、特許検索、SEC 提出書類へのアクセスをメモリ層に付与できます。
重要な理由: これによって Hermes Agent の基礎的な知能が即座に向上します。古い OpenClaw のファイルだけに頼るのではなく、Hermes Agent は権威ある公開データで強化された、文書を理解するメモリを持つようになります。
ステップ4: MemoryLake をツールとワークフローに接続する
これが移行を完了させる重要なステップです。ここでこの永続メモリを Hermes Agent に接続し、必要であれば OpenClaw の環境を正式に終了させます。
操作: MemoryLake 内で API キーを生成します。
スムーズな統合の詳細: MemoryLake はワンクリックインストールと自動設定に対応しています。たとえば、公開ドキュメントでは、セットアップガイドをコピーして OpenClaw に貼り付けるだけで、システムが自動的にプラグインをインストールし、設定を完了し、ゲートウェイを再起動できると強調されています。
Hermes Agent への接続: 単一のコマンドラインでプラグインをインストールするか、Model Context Protocol (MCP) または API 連携を使って Hermes Agent に直接統合できます。MemoryLake は、OpenClaw、Hermes Agent、ChatGPT、Claude とシームレスに統合できるよう設計されています。
重要な理由: 新しい Hermes Agent は、これまでの知識をすべて即座に取り込んだ状態になります。ワークフローは、まさに中断したところから続きます。
避けるべき一般的な移行ミス
メモリを後回しにする: Hermes Agent へ完全に移行してから、重要なコンテキストが欠けていることに気づくこと。完全に切り替える前に、必ずデータを抽出して集約してください。
チャットログとメモリを混同する: OpenClaw のチャット履歴を50ページの PDF にして Hermes Agent に読み込ませると、コンテキストウィンドウが肥大化します。必要なのは生の記録ではなく、文書を理解するメモリシステムです。
ローカルファイルに頼る: 参考 PDF をローカルのデスクトップフォルダに置いておくと、Hermes Agent のチャット画面に何度もドラッグ&ドロップする羽目になります。永続的な API ベースの層のほうがはるかに効率的です。
この移行アプローチに最適なユースケース
ツール間のギャップを埋めるために永続的な AI メモリ層を使うことは、次のようなケースで特に推奨されます:
文書中心のワークフロー: 内容の濃い PDF、法的契約書、財務報告書に大きく依存するワークフロー。
研究チーム: 数週間かけて文献レビューを積み上げるチームで、新しい基盤モデルを試す際にその文脈を失う余裕がない場合。
マルチエージェント利用者: コーディングには Hermes Agent、初期ドラフトには OpenClaw、編集には Claude を使い、しかもすべてが同じメモリパスポートを共有している必要があるユーザー。
創業者や経営幹部: 最高の性能を求めて AI ツールを頻繁に切り替えるものの、業務上の文脈は安定していてほしいリーダー。
結論
OpenClaw から Hermes Agent への移行が、何週間ものコンテキストを失ったり、調査を最初からやり直したり、終わりのない PDF フォルダを再アップロードしたりすることを意味する必要はありません。移行時に感じる摩擦は、新しいエージェントの問題ではなく、現在の AI メモリがサイロ化されていることの問題です。
データがツールから独立して存在するモデルに移行すれば、生産性の損失という代償を払うことなく、好きなときに AI アシスタントをアップグレードできる自由が手に入ります。
ワークフローが文書、プロジェクトの文脈、再利用可能な知見に強く依存しているなら、MemoryLake は検討に値します。ツールを前に進めながら切り替える方法を提供してくれます。モデルやエージェントを頻繁に切り替えるチームにとって、MemoryLake のようなポータブルなメモリ層を使うことは、ワークフローの継続性を保ち、新しい AI システムが旧システムの続きから正確に再開できるようにするための有力な選択肢です。
よくある質問
コンテキストを失わずにある AI エージェントから別のエージェントへ移行するには?
コンテキストを失わずに移行するには、手動でのプロンプトコピーに厳密に頼るのは避けてください。その代わり、基盤となる文書と指示を抽出してポータブルな AI メモリ層にアップロードし、そのメモリ層を API か MCP 連携で新しいエージェントに接続します。
AI ツールを切り替えると、通常何が失われますか?
AI ツールを切り替えると、ユーザーは通常、アップロードした参考文書、進行中のタスク履歴、AI が好みについて学習した構造化知識、複数セッションを通じて形成された特定のワークフローの習慣を失います。
AI アシスタント間の移行でチャット履歴だけで十分ですか?
いいえ。生のチャット履歴は、新しい AI アシスタントが効果的に解析するのが難しいです。長いチャットログを貼り付けるとトークン上限をすぐに消費し、AI の性能を落としがちです。必要なのは、単純なテキストログではなく、構造化されて検索可能なメモリです。
ツールをまたいで文書とワークフローメモリを保持するには?
ツール非依存のメモリ基盤を使えば、文書をツール間で保持できます。PDF、Excel ファイル、コンテキストを特定のエージェントの専用ストレージではなく中央集約された層に保存すれば、新しく採用するどのツールも同じデータソースを参照できます。
MemoryLake とは何で、移行にどう役立ちますか?
MemoryLake は AI システム向けの永続メモリ層です。再利用可能な「第二の脳」として機能することで移行を助けます。セットアップの流れに従えば、文書とコンテキストを MemoryLake に保存し、その後 Hermes Agent や OpenClaw のようなプラットフォームに直接接続して、ツールをまたいだシームレスな継続性を確保できます。
AI ワークフローを一から作り直すのを避けるには?
ワークフローを作り直さずに済ませるには、データを AI の実行環境から切り離してください。プロンプト、ルール、参照ファイルを保持する永続的なナレッジベースを構築し、そのデータを今使っている AI エージェントへ流し込むようにします。