Exploiter GPT pour Améliorer la Résumé de Texte : Stratégies pour Réduire les Hallucinations

Thème Central
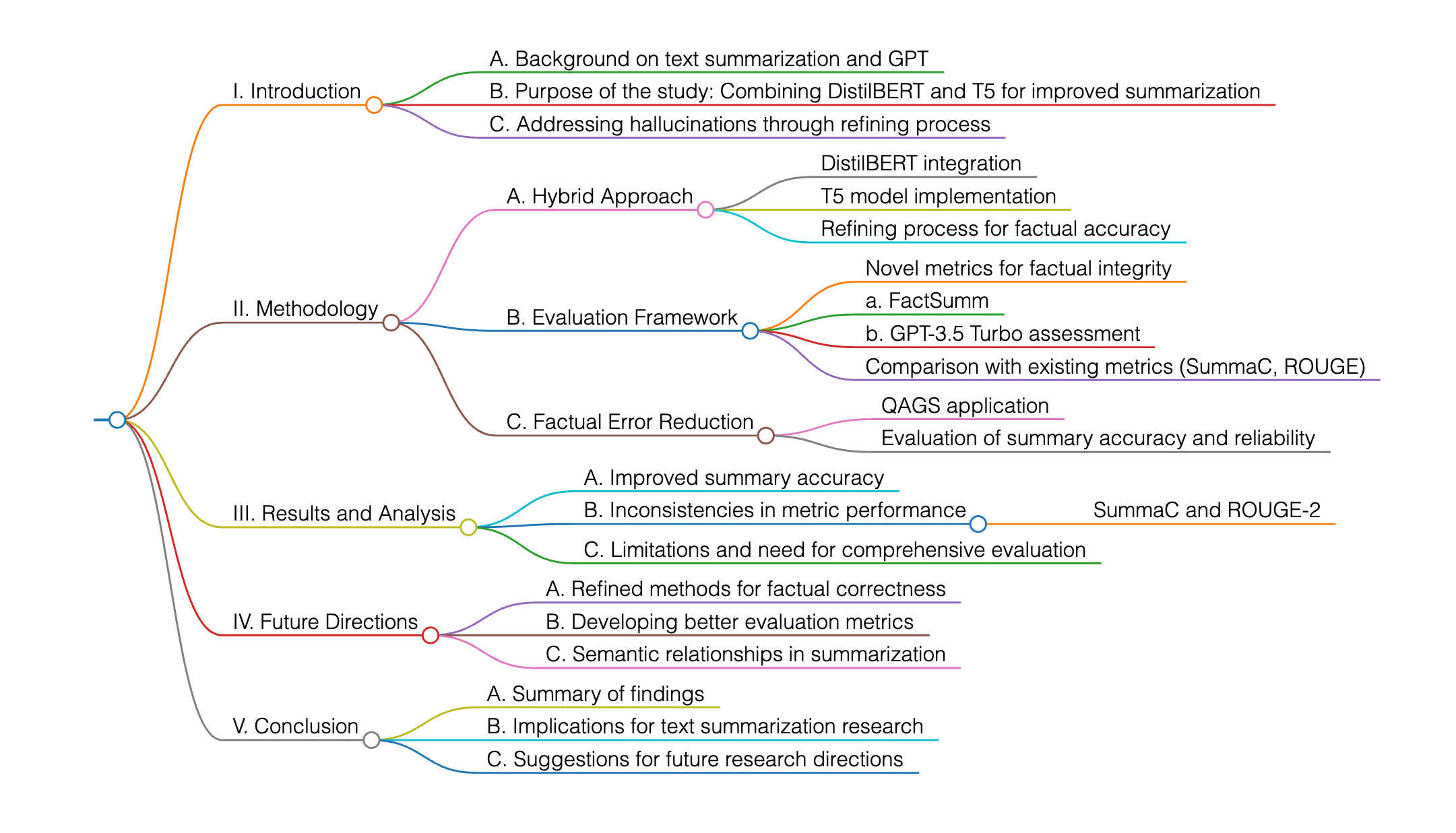
Cette recherche explore l'utilisation de GPT pour améliorer la résumé de texte en combinant DistilBERT et T5, tout en traitant les hallucinations via un processus de raffinement. L'étude adopte une approche hybride, évalue l'intégrité factuelle à l'aide de métriques innovantes et démontre des améliorations significatives en termes de précision et de fiabilité des résumés. L'accent est mis sur la réduction des erreurs factuelles dans les résumés abstractifs, en utilisant des méthodes telles que QAGS, SummaC et ROUGE, avec GPT-3.5 Turbo pour l'évaluation de l'exactitude factuelle.
Si certaines métriques montrent une progression, comme FactSumm et GPT-3.5, d'autres, telles que SummaC et ROUGE-2, restent incohérentes. La recherche souligne la nécessité de cadres d’évaluation plus complets, prenant en compte à la fois les relations sémantiques et la véracité des faits. Les travaux futurs viseront à affiner ces méthodes et à développer des métriques plus fiables.
Carte Mentale
TL;DR
Quel problème cet article cherche-t-il à résoudre ? S'agit-il d'un problème nouveau ?
L'article vise à traiter le problème des hallucinations dans les résumés de texte en améliorant la cohérence factuelle et en réduisant le contenu halluciné. Ce problème n'est pas nouveau, mais l'étude propose une approche innovante en utilisant une évaluation basée sur GPT, permettant d'examiner plus en profondeur la correction sémantique et factuelle, offrant ainsi une solution plus efficace aux hallucinations dans les résumés.
Quelle hypothèse scientifique cet article cherche-t-il à valider ?
L'article cherche à valider l'hypothèse selon laquelle les résumés raffinés obtiennent un score moyen plus élevé que les résumés non raffinés, comme le montrent le rejet de l'hypothèse nulle pour des métriques telles que FactSumm, QAGS, GPT-3.5, ROUGE-1 et ROUGE-L.
Quelles nouvelles idées, méthodes ou modèles cet article propose-t-il ? Quelles sont leurs caractéristiques et avantages par rapport aux méthodes précédentes ?
L'article propose une méthode de raffinement innovante basée sur GPT visant à réduire les hallucinations dans les résumés de texte. Cette approche combine les avantages des résumés extractifs et abstractifs, tout en utilisant les Generative Pre-trained Transformers (GPT) pour améliorer la qualité des résumés. L'étude met l'accent sur l'utilisation de techniques avancées d'apprentissage automatique, telles que le reinforcement learning, afin de minimiser les erreurs et les hallucinations dans les résumés abstractifs.
En parallèle, le papier explore le raisonnement contrefactuel et semi-contrefactuel dans argumentation frameworks abstraits (AFs), en se concentrant sur leur complexité computationnelle et leur intégration dans les systèmes d'argumentation. L'étude définit ces concepts et cherche à améliorer l'explicabilité en les encodant dans des AFs à contraintes faibles et en utilisant des ASP solvers. En examinant la complexité de divers problèmes tels que l'existence, la vérification et l'acceptation sous différentes sémantiques, la recherche montre que ces tâches sont généralement plus complexes que celles traditionnelles. La contribution principale réside dans la proposition d'algorithmes et la discussion d'applications capables d'améliorer la prise de décision et la persuasion des systèmes basés sur l'argumentation.
1. Exploiter GPT pour Améliorer la Résumé de Texte : Une Stratégie pour Réduire les Hallucinations
Cette recherche explore l'utilisation de GPT pour améliorer la résumé de texte en combinant DistilBERT et T5, avec un accent sur la réduction des hallucinations via un processus de raffinement. L'étude adopte une approche hybride et introduit de nouvelles métriques pour évaluer l'intégrité factuelle, montrant des améliorations significatives en termes de précision et de fiabilité des résumés.
L'accent est mis sur la réduction des erreurs factuelles dans les résumés abstractifs, en utilisant des méthodes telles que QAGS, SummaC et ROUGE, avec l'aide de GPT-3.5 Turbo pour l'évaluation de l'exactitude factuelle. Certaines métriques, comme FactSumm et GPT-3.5, montrent des progrès, tandis que d'autres, comme SummaC et ROUGE-2, restent incohérentes.
L'étude souligne la nécessité de cadres d’évaluation plus complets, prenant en compte les relations sémantiques et la véracité des faits. Les travaux futurs viseront à affiner les méthodologies et à développer des métriques améliorées. Pour une analyse détaillée, il est conseillé de se référer aux méthodologies et résultats spécifiques présentés dans l'article.
2. NL2Plan : Planification Robuste Guidée par LLM à partir de Descriptions Textuelles Minimales
NL2Plan introduit un système indépendant du domaine qui combine des LLMs et la planification classique pour générer des représentations PDDL à partir de descriptions en langage naturel. Ce système dépasse Zero-Shot CoT en résolvant un plus grand nombre de tâches, offrant de l'explicabilité et facilitant la création de PDDL.
Le processus multi-étapes de NL2Plan inclut l'extraction des types, la construction de hiérarchies et la création d'actions, avec la possibilité d'intégrer un feedback humain. L'évaluation à travers divers domaines a mis en évidence à la fois des forces et des limites, tandis que les travaux futurs se concentreront sur l'amélioration de l'efficacité et l'intégration avec d'autres outils. Pour une compréhension complète, il est recommandé d'examiner les méthodologies et résultats détaillés dans l'article.
3. Évaluation des Résumés Textuels Générés par les Grands Modèles de Langage avec GPT d'OpenAI
Cette étude évalue l’efficacité des modèles GPT d'OpenAI dans l'évaluation des résumés produits par six modèles basés sur des transformeurs (DistilBART, BERT, ProphetNet, T5, BART et PEGASUS) à l'aide de métriques telles que ROUGE, LSA et l'évaluation propre de GPT.
La recherche démontre de fortes corrélations, notamment en termes de pertinence et de cohérence, soulignant le potentiel de GPT comme outil précieux pour évaluer les résumés textuels. L'évaluation des performances sur le jeu de données CNN/Daily Mail, en se concentrant sur la concision, la pertinence, la cohérence et la lisibilité, souligne l’importance d’intégrer des évaluations pilotées par IA comme GPT pour améliorer les évaluations dans les tâches de traitement du langage naturel (NLP).
L'étude suggère également des pistes de recherche futures, incluant l'expansion à divers tasks NLP et la compréhension de la perception humaine des évaluations générées par l'IA. Pour une analyse détaillée, il est conseillé de se référer aux méthodologies et résultats spécifiques décrits dans l'article.
4. DeepSeek-V2 : Un Modèle de Langage Mixture-of-Experts Puissant, Économique et Efficace
DeepSeek-V2 se présente comme un modèle de langage Mixture-of-Experts (MoE) rentable, avec 236 milliards de paramètres, utilisant MLA pour une attention efficace et DeepSeekMoE pour l'entraînement. Surperformant des modèles open-source tels que LLaMA et Qwen avec moins de paramètres actifs, DeepSeek-V2 offre une efficacité et des performances accrues.
Parmi les caractéristiques notables figurent :
un coût d'entraînement inférieur de 42,5 %,
un cache KV réduit de 93,3 %,
un débit de génération 5,76 fois plus élevé.
Pré-entraîné sur un corpus de 8,1T, DeepSeek-V2 excelle sur divers benchmarks, ce qui en fait une option intéressante pour une utilisation pratique. Pour une analyse plus complète, il est recommandé de se référer aux méthodologies et résultats spécifiques présentés dans l'article.
5. Amélioration de la Scalabilité de la Metric Differential Privacy via Partitionnement de Jeux de Données Secrets et Décomposition de Benders
Cet article propose une approche scalable pour la Metric Differential Privacy (mDP) utilisant la décomposition de Benders, qui consiste à partitionner des jeux de données secrets et à reformuler le problème de programmation linéaire. En gérant les perturbations entre et au sein des sous-ensembles, cette méthode améliore l’efficacité, réduisant la complexité et augmentant la scalabilité.
Les expériences menées sur divers ensembles de données montrent une amélioration 9 fois supérieure par rapport aux méthodes précédentes, la rendant adaptée aux grands jeux de données. L’étude compare différents algorithmes de partitionnement (k-m-DV, k-m-rec, k-m-adj, BSC) et leur impact sur le temps de calcul, le k-m-DV surpassant souvent les autres grâce à un équilibrage optimal des sous-problèmes.
De plus, la recherche explore la confidentialité de localisation, l'analyse textuelle et les mécanismes de privacy basés sur les graphes, suggérant des pistes d’amélioration pour les travaux futurs. Pour un examen détaillé, il est conseillé de se référer aux méthodologies et résultats spécifiques de l’article.
6. Enrichissement des Embeddings BERT pour la Classification des Publications Scientifiques
Cette étude se concentre sur la catégorisation automatique des publications scientifiques dans le cadre de la tâche partagée NSLP 2024 FoRC Shared Task I, en utilisant des modèles pré-entraînés tels que BERT, SciBERT, SciNCL et SPECTER2. Les chercheurs enrichissent l’ensemble de données avec des articles en anglais provenant de ORKG et arXiv pour traiter le déséquilibre des classes.
Grâce au fine-tuning et à l’augmentation de données à partir de bases bibliographiques, la performance de classification est améliorée, SPECTER2 atteignant la meilleure précision. L’enrichissement avec des métadonnées provenant de S2AG, OpenAlex et Crossref améliore encore les performances, atteignant un F1-score pondéré de 0,7415.
L’étude explore également le transfer learning, des modèles personnalisés tels que TwinBERT, et l’influence des métadonnées sur la classification, démontrant le potentiel des systèmes automatisés pour gérer le volume croissant de la littérature scientifique. Pour une compréhension complète, il est recommandé d’examiner les méthodologies et résultats détaillés de l’article.
7. Amélioration de l'Efficacité et de la Précision des Revues d'Actifs en Finance Structurée : Application d'un Cadre Multi-Agents
Cette recherche explore l'intégration de l'intelligence artificielle, en particulier des grands modèles de langage (LLMs), pour améliorer l’efficacité et la précision des revues d’actifs en finance structurée. L'étude souligne le potentiel d’intégrer l’IA dans les processus de due diligence, avec des modèles propriétaires comme GPT-4 offrant des performances supérieures et des alternatives open-source telles que LLAMA3 offrant un bon rapport coût-efficacité. Les systèmes à double agent sont mis en avant pour améliorer la précision, bien que cela entraîne des coûts plus élevés. L’étude se concentre sur l’automatisation de la vérification des informations, l’analyse des documents financiers et la gestion des risques, avec un accent particulier sur l’auto-ABS et la disponibilité du code pour des recherches et implémentations futures. L’article compare également différents modèles d’IA, discute des défis et insiste sur la nécessité de travaux futurs portant sur la scalabilité, l’optimisation des coûts et la conformité réglementaire. Pour une analyse détaillée, il est conseillé de se référer aux méthodologies et résultats spécifiques de l’article.
8. Réévaluation des Attaques Adversariales au Niveau des Caractères
L’article présente Charmer, une attaque adversariale au niveau des caractères conçue pour les modèles NLP, surpassant les méthodes précédentes grâce à des taux de succès plus élevés et de meilleures mesures de similarité. Charmer montre son efficacité, notamment grâce à une sélection avide de sous-ensembles de positions, et s’avère performant sur des modèles petits comme grands. Cette méthode surpasse d’autres techniques, y compris les défenses contre les attaques basées sur les tokens et la reconnaissance robuste de mots. L’étude met en évidence les défis des attaques NLP, les limitations des méthodes basées sur le gradient pour les attaques au niveau des caractères, et la nécessité de défenses robustes contre les exemples adversariaux. Pour une compréhension complète, il est recommandé de consulter les méthodologies et résultats détaillés de l’article.
9. Une Quatrième Vague de Données Ouvertes ? Exploration du Spectre des Scénarios pour les Données Ouvertes et l’IA Générative
L’article de Chafetz, Saxena et Verhulst explore l’impact potentiel de l’IA générative sur les données ouvertes, en discutant de cinq scénarios : pré-entraînement, adaptation, inférence, augmentation de données et exploration ouverte. L’étude met en lumière les opportunités et défis, tels que la qualité des données, la provenance et les considérations éthiques, plaidant pour une meilleure gouvernance et transparence des données. À travers des études de cas et des Action Labs, les auteurs examinent l’intersection entre données ouvertes et IA, soulignant la nécessité de standardisation, d’interopérabilité et d’une utilisation responsable. L’article vise à guider l’évolution des données ouvertes face aux capacités croissantes de l’IA. Pour une analyse détaillée, il est conseillé de se référer aux méthodologies et résultats spécifiques de l’article.
La méthode de raffinement basée sur GPT présentée dans l’article offre une approche unique pour réduire les hallucinations dans la résumé de texte en exploitant des modèles de langage avancés tels que GPT. Cette approche combine les forces des techniques de résumés extractifs et abstractifs avec les capacités de GPT pour améliorer la qualité et la cohérence factuelle des résumés. De plus, l’étude se concentre sur l’utilisation de techniques de reinforcement learning pour minimiser les erreurs et les hallucinations dans les résumés abstractifs, démontrant ainsi des avancées notables en termes de précision et fiabilité.
Existe-t-il des recherches connexes ? Quels sont les chercheurs notables dans ce domaine ? Quel est le point clé de la solution mentionnée dans l’article ?
Oui, il existe des recherches liées au domaine de la résumé de texte et de la réduction des hallucinations. Plusieurs études se sont concentrées sur l’amélioration de la qualité des résumés en réduisant les hallucinations, visant à renforcer la précision et l’intégrité factuelle des résumés générés grâce à des techniques avancées de machine learning et à des métriques d’évaluation raffinées.
Parmi les chercheurs notables dans le domaine du GPT-Enhanced Summarization : Réduction des Hallucinations, on peut citer :
Wang et al. (2020)
Lin (2004)
Lehmann et Romano (2005)
Heo (2021)
Laban et al. (2022)
Ces chercheurs ont contribué au développement et à l’évaluation de méthodes visant à réduire les hallucinations dans les résumés de texte à travers différentes approches et métriques.
Le point clé de la solution mentionnée dans l’article réside dans l’utilisation de GPT-3.5 Turbo pour évaluer les résumés raffinés. Les capacités avancées de compréhension du langage de GPT lui permettent d’évaluer efficacement la cohérence factuelle et d’identifier les hallucinations, le rendant particulièrement adapté à l’évaluation des résumés.
Comment les expériences ont-elles été conçues ?
Les expériences présentées dans l’article ont été conçues pour évaluer les résumés raffinés à l’aide de GPT-3.5 Turbo, afin de mesurer la cohérence factuelle et d’identifier les hallucinations. La méthodologie reposait sur un test d’hypothèse :
Hypothèse nulle : le score moyen des résumés raffinés n’est pas supérieur à celui des résumés non raffinés.
Hypothèse alternative : les résumés raffinés obtiennent un score moyen plus élevé.
Les métriques d’évaluation comprenaient FactSumm, QAGS, GPT-3.5, ROUGE-1 et ROUGE-L, et l’analyse statistique a montré des améliorations significatives après le raffinement, conduisant au rejet de l’hypothèse nulle pour plusieurs métriques.
Quel ensemble de données a été utilisé pour l’évaluation quantitative ? Le code est-il open source ?
L’ensemble de données utilisé pour l’évaluation quantitative comprend les métriques FactSumm, QAGS, GPT-3.5, ROUGE-1 et ROUGE-L. Concernant le code, aucune information sur sa disponibilité en open source n’a été fournie dans les contextes disponibles. Pour obtenir des détails sur le statut open source du code, il serait nécessaire de fournir des informations ou contextes supplémentaires.
Quelles sont les contributions de cet article ?
L’article apporte une contribution majeure en introduisant un processus d’évaluation basé sur GPT qui améliore la cohérence factuelle et réduit les hallucinations dans les résumés de texte. Cette approche garantit que les résumés ne se contentent pas de partager des similarités lexicales avec les textes sources, mais respectent également avec précision les faits, répondant ainsi de manière plus efficace à la problématique clé des hallucinations.
Quels travaux peuvent être approfondis ?
Des recherches futures peuvent viser à améliorer l’efficacité des techniques de résumé abstractif en minimisant les erreurs et les hallucinations dans les résumés générés. Cela peut inclure l’exploration de stratégies avancées de machine learning, comme le reinforcement learning, pour pénaliser la génération de contenu absent du texte source. De plus, le raffinement du processus de résumé afin d’atteindre des niveaux supérieurs de précision factuelle et de réduire les hallucinations constitue un domaine clé pour des travaux continus en résumé de texte.
Lire la Suite
Le résumé ci-dessus a été automatiquement généré par Powerdrill.
Click the lien pour voir la page de résumé et d'autres papiers recommandés.