Vers une meilleure adéquation entre texte et image grâce à la modulation de l’attention

Thème central
Cet article aborde les défis de la génération texte-image avec les modèles de diffusion, en particulier la fuite d’entités et le désalignement des attributs, en introduisant un mécanisme de modulation de l’attention sans entraînement. Cette méthode inclut le contrôle de la « température » de l’auto-attention, le masquage de l’attention croisée centré sur les objets, et la réévaluation dynamique par phases. L’approche améliore l’alignement sans nécessiter de données annotées étendues, conduisant à une meilleure correspondance texte-image et à des images générées de qualité supérieure, même avec des prompts complexes. Les expériences démontrent des performances de pointe, montrant une gestion optimale des entités et attributs multiples, tout en réduisant le coût computationnel par rapport aux modèles existants.
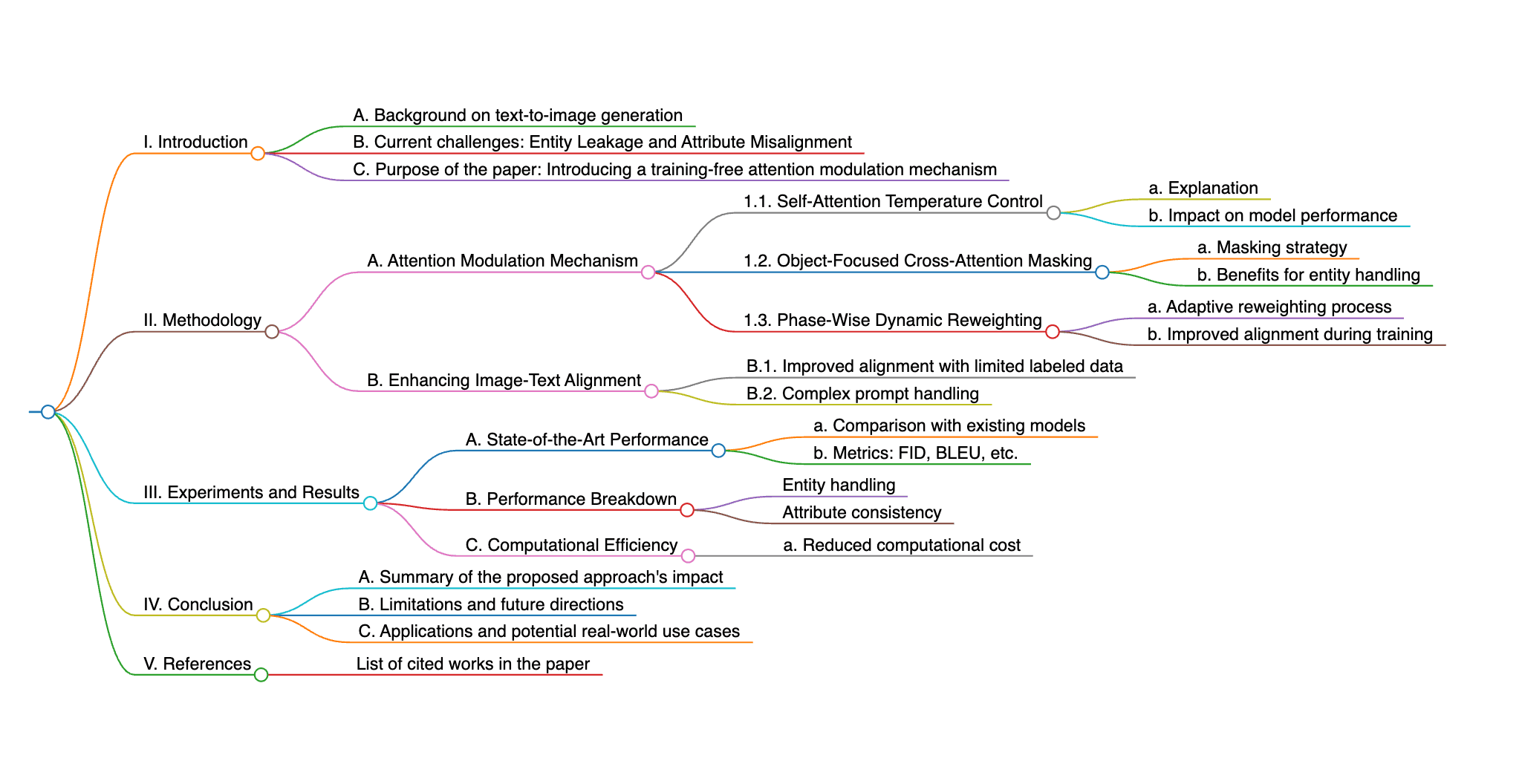
Carte mentale
TL;DR
Q1. Quel problème cet article cherche-t-il à résoudre ? S’agit-il d’un problème nouveau ?
Cet article vise à résoudre les problèmes de fuite d’entités et de désalignement des attributs dans les tâches de synthèse texte-image. Ces problèmes ne sont pas entièrement nouveaux, mais restent des défis persistants dans le domaine.
Q2. Quelle hypothèse scientifique cet article cherche-t-il à valider ?
L’article cherche à valider l’hypothèse selon laquelle un mécanisme de contrôle de l’attention par phases, sans entraînement, peut traiter efficacement les problèmes de fuite d’entités et de désalignement des attributs dans les tâches de génération texte-image.
Q3. Quelles nouvelles idées, méthodes ou modèles cet article propose-t-il ? Quelles sont leurs caractéristiques et avantages par rapport aux méthodes précédentes ?
L’article propose un mécanisme de focalisation sur les attributs via un paradigme de contrôle de l’attention par phases, sans entraînement, pour relever les défis des tâches de génération texte-image. Ce mécanisme comprend plusieurs composants clés : un contrôle de la « température » dans les modules d’auto-attention pour atténuer la fuite d’entités, un schéma de masquage centré sur les objets dans les modules d’attention croisée pour distinguer efficacement l’information sémantique entre les entités, et un contrôle dynamique par phases des poids pour améliorer l’alignement texte-image.
De plus, l’article introduit une approche novatrice combinant le contrôle de la température en auto-attention, le masquage centré sur les objets en attention croisée et la stratégie de réévaluation dynamique par phases, afin de réduire la fuite d’entités et le désalignement des attributs. Ces méthodes renforcent la capacité du modèle à se concentrer sur des composants sémantiques spécifiques, diminuent le désalignement des attributs et améliorent globalement l’alignement texte-image avec un coût computationnel minimal.
Les caractéristiques et avantages clés par rapport aux méthodes précédentes incluent :
La combinaison synergique des mécanismes de contrôle de la température, de masquage centré sur les objets et de réévaluation dynamique par phases, qui améliore l’attention sur les composants sémantiques spécifiques et réduit le désalignement des attributs.
L’intégration d’une méthode de réévaluation dynamique attribuant différents poids aux masques selon des courbes de tendance distinctes, renforçant encore le contrôle de l’attention du modèle.
Une distinction efficace entre entités et arrière-plans des images, ce qui améliore la qualité globale des images générées.
Par rapport aux méthodes précédentes, l’approche proposée montre des performances supérieures dans les scénarios avec des prompts complexes contenant plusieurs entités et attributs. Le modèle surpasse spécifiquement Structured Diffusion dans les cas de multiples paires objet-attribut, en garantissant une meilleure affiliation de l’information sémantique et en réduisant le désalignement des attributs, grâce au masquage centré sur les objets et au contrôle dynamique par phases des poids.
Dans l’ensemble, les méthodes proposées offrent une solution complète pour traiter les problèmes de fuite d’entités et de désalignement des attributs dans la génération texte-image. En intégrant des mécanismes innovants de contrôle de l’attention et des stratégies de réévaluation dynamique, le modèle obtient un meilleur alignement texte-image et génère des images de haute qualité avec une fidélité et une précision accrues.
Q4. Existe-t-il des recherches connexes ? Qui sont les chercheurs remarquables dans ce domaine ? Quelle est la clé de la solution mentionnée dans l’article ?
Dans le domaine de la génération texte-image, plusieurs travaux de recherche sont pertinents. Parmi les chercheurs remarquables, on peut citer Xu et al., qui ont introduit ImageReward pour évaluer les préférences humaines dans la génération texte-image. Feng et al. ont proposé Structured Diffusion, se concentrant sur la génération T2I compositionnelle. Un autre travail significatif est celui de Yihang Wu et al., qui a développé un mécanisme de focalisation sur les attributs pour améliorer l’alignement texte-image.
La clé de la solution proposée dans l’article repose sur un mécanisme de contrôle de l’attention par phases, sans entraînement. Ce mécanisme intègre le contrôle de la température dans le module d’auto-attention pour atténuer les problèmes de fuite d’entités, ainsi qu’un schéma de masquage centré sur les objets et un contrôle dynamique par phases des poids dans le module d’attention croisée afin d’améliorer la distinction de l’information sémantique entre les entités.
Q5. Comment les expériences ont-elles été conçues dans l’article ?
Les expériences ont été conçues pour évaluer les performances du modèle proposé dans différents scénarios d’alignement, en mettant l’accent sur l’alignement texte-image avec un coût computationnel minimal. Elles visaient à traiter les problèmes de fuite d’entités et de désalignement des attributs dans les tâches de génération texte-image, en intégrant un mécanisme de contrôle dynamique par phases des poids et un schéma de masquage centré sur les objets dans les modules d’attention croisée. Les résultats ont montré que le modèle améliore l’alignement texte-image en discernant plus efficacement l’affiliation de l’information sémantique entre les entités.
Q6. Quel jeu de données a été utilisé pour l’évaluation quantitative ? Le code est-il open source ?
Le jeu de données utilisé pour l’évaluation quantitative comprend l’ensemble de validation COCO, et les critères d’évaluation incluent FID, CLIP Score et ImageReward Score. Concernant le code, aucune information sur sa disponibilité open source n’est fournie dans les contextes disponibles. Pour plus de détails sur le code et sa disponibilité, il est recommandé de se référer à la publication ou au projet spécifique lié à cette recherche.
Q7. Les expériences et résultats présentés dans l’article soutiennent-ils les hypothèses scientifiques à vérifier ?
Les expériences et résultats présentés dans l’article apportent un soutien solide aux hypothèses scientifiques à vérifier. Le paradigme de contrôle de l’attention par phases, sans entraînement, proposé, traite efficacement les problèmes de fuite d’entités et de désalignement des attributs dans les tâches de génération texte-image. Grâce à l’implémentation du contrôle de la température en auto-attention, du masquage centré sur les objets et des stratégies de réévaluation dynamique par phases, le modèle démontre un meilleur alignement texte-image avec un coût computationnel minimal. Les études d’ablation menées sur les composants clés de la méthode confirment l’efficacité du contrôle de l’auto-attention et du masque centré sur les objets pour améliorer des métriques telles que FID et CLIP Score. Les résultats montrent que l’intégration de ces composants assure des performances plus robustes que l’utilisation de stratégies individuelles.
Q8. Quelles sont les contributions de cet article ?
L’article propose un paradigme de contrôle de l’attention par phases, sans entraînement, pour traiter les problèmes de fuite d’entités et de désalignement des attributs dans les tâches de génération texte-image. Les contributions incluent :
La mise en œuvre d’un mécanisme de contrôle de la température en auto-attention pour atténuer la fuite d’entités.
L’introduction d’un schéma de masquage centré sur les objets et d’un mécanisme de contrôle dynamique par phases des poids dans les modules d’attention croisée, afin d’améliorer l’affiliation de l’information sémantique entre les entités.
La proposition d’une stratégie de réévaluation dynamique par phases pour améliorer l’alignement des attributs, en variant l’accent mis sur les différents composants sémantiques du prompt pendant le processus de génération.
Q9. Quels travaux pourraient être poursuivis plus en profondeur ?
Les travaux futurs pourraient se concentrer sur le raffinement du mécanisme de masquage centré sur les objets pour améliorer le contrôle de l’attention dans les tâches de génération texte-image. De plus, l’exploration de mécanismes de réévaluation dynamique permettant de prioriser différents composants du prompt à différentes étapes pourrait constituer une piste d’investigation plus approfondie.
Le contenu est produit par Powerdrill, cliquez sur le lien pour consulter la page de résumé.
Pour un lien vers le document complet, cliquez ici.
Connectez-vous à powerdrill.ai pour découvrir la génération de texte à image.