Présentation de DB-GPT

Thème Central
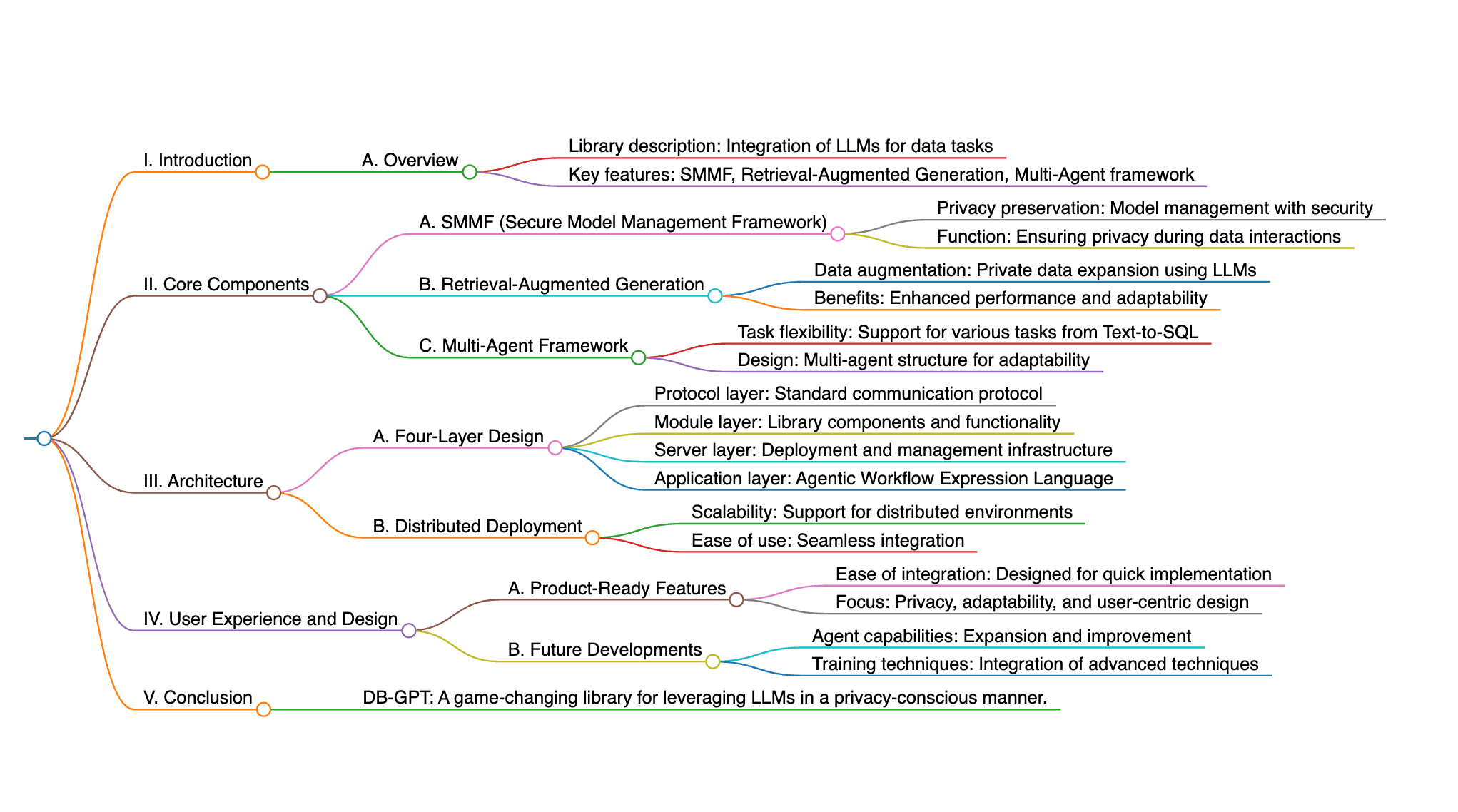
DB-GPT est une bibliothèque Python open-source qui révolutionne l'interaction avec les données en intégrant de grands modèles linguistiques dans des tâches, garantissant la confidentialité avec le SMMF et soutenant des tâches allant de Text-to-SQL à des analyses complexes. Les composants clés comprennent le SMMF pour la gestion des modèles, la génération augmentée par la récupération pour l'augmentation de données privées, et un cadre multi-agents pour la flexibilité des tâches. La bibliothèque se compose d'une architecture à quatre couches (Protocole, Module, Serveur, Application) avec un langage d'expression de flux de travail agentique, et prend en charge le déploiement dans des environnements distribués. DB-GPT améliore les LLM, offre des fonctionnalités prêtes à l'emploi, et est conçu pour une intégration facile, avec un accent sur la confidentialité, l'adaptabilité et l'expérience utilisateur. Les développements futurs élargiront les capacités des agents et intégreront davantage de techniques de formation.
Carte Mentale
TL;DR
Q1. Quel problème l’article cherche-t-il à résoudre ? S’agit-il d’un problème nouveau ?
L’article vise à résoudre le défi d’améliorer les tâches d’interaction avec les données grâce aux modèles de langage étendu (LLM), afin de fournir aux utilisateurs une compréhension fiable et des insights précis sur leurs données. Il ne s’agit pas d’un problème entièrement nouveau, car l’intégration des LLM dans les tâches d’interaction avec les données fait déjà l’objet de recherches et de développements continus.
Q2. Quelle hypothèse scientifique cet article cherche-t-il à valider ?
L’article cherche à valider l’hypothèse selon laquelle l’intégration des modèles de langage étendu (LLM) dans les tâches d’interaction avec les données peut améliorer l’expérience utilisateur et l’accessibilité, en fournissant des réponses contextuelles propulsées par les LLM, ce qui en fait un outil indispensable pour des utilisateurs allant du novice à l’expert.
Q3. Quelles nouvelles idées, méthodes ou modèles l’article propose-t-il ? Quelles sont leurs caractéristiques et avantages par rapport aux méthodes précédentes ?
L’article présente DB-GPT, une bibliothèque Python qui intègre les modèles de langage étendu (LLM) aux tâches traditionnelles d’interaction avec les données afin d’améliorer l’expérience utilisateur et l’accessibilité.
Il introduit un cadre Multi-Agents inspiré de MetaGPT et AutoGen pour traiter des tâches complexes telles que l’analyse générative de données. Ce cadre utilise plusieurs agents aux compétences spécialisées pour relever des défis multifacettes, comme la construction de rapports de vente détaillés à partir de différentes dimensions. De plus, le cadre Multi-Agents de DB-GPT conserve l’historique des communications entre agents, ce qui renforce la fiabilité du contenu généré.
L’article souligne également l’importance d’incorporer des processus de raisonnement et de décision automatisés propulsés par LLM dans les tâches d’interaction avec les données, et met en avant la nécessité de cadres Multi-Agents indépendants de la tâche pour traiter efficacement une variété de scénarios.
Un autre point majeur est l’accent mis sur les configurations sensibles à la confidentialité, assurant que les interactions avec les données restent sécurisées, un aspect peu exploré dans les travaux précédents.
Les caractéristiques et avantages principaux de DB-GPT par rapport aux méthodes antérieures incluent :
Réponses contextuelles propulsées par les LLM, améliorant l’expérience utilisateur et l’accessibilité,
Cadre Multi-Agents utilisant les compétences spécialisées de chaque agent pour relever des défis complexes en analyse générative de données,
Archivage complet de l’historique des communications entre agents, augmentant la fiabilité du contenu généré,
Mesures de confidentialité pour protéger les informations privées,
Cadres indépendants de la tâche, capables de s’adapter à une large gamme de tâches d’interaction avec les données.
Ces caractéristiques font de DB-GPT un outil polyvalent et sécurisé pour améliorer les tâches d’interaction avec les données grâce à l’intégration des LLM et des cadres Multi-Agents.
Q4. Quelles recherches connexes existent ? Comment peuvent-elles être catégorisées ? Qui sont les chercheurs remarquables dans ce domaine ? Quelle est la clé de la solution mentionnée dans l’article ?
Les recherches liées aux tâches d’interaction avec les données utilisant les modèles de langage étendu (LLM) ont été largement explorées. On peut les classer en plusieurs domaines :
Amélioration des tâches d’interaction avec les données grâce aux LLM,
Intégration du raisonnement automatisé et des processus décisionnels dans les interactions avec les données,
Gestion des problématiques de confidentialité dans les interactions avec les données propulsées par LLM.
Parmi les chercheurs notables dans ce domaine, on peut citer Siqiao Xue, Danrui Qi, Caigao Jiang, ainsi que d’autres contributeurs issus d’organisations telles que Ant Group, Alibaba Group et JD Group.
La clé de la solution proposée dans l’article repose sur le développement de DB-GPT, une bibliothèque Python open-source qui supporte l’interaction avec les données via des Multi-Agents disposés de manière flexible et une architecture à quatre couches, permettant de traiter des tâches complexes tout en préservant la confidentialité des données.
Q5. Comment les expériences ont-elles été conçues dans l’article ?
Les expériences ont été conçues pour démontrer les capacités de DB-GPT, une bibliothèque Python intégrant des LLM dans les tâches traditionnelles d’interaction avec les données. La configuration expérimentale impliquait l’utilisation d’un ordinateur portable connecté à Internet pour accéder à DB-GPT via le service GPT d’OpenAI, avec la possibilité d’utiliser des modèles locaux comme Qwen et GLM. Les expériences ont montré la capacité de DB-GPT à réaliser des analyses génératives de données en initiant des tâches via des instructions en langage naturel, en utilisant un cadre Multi-Agents pour générer des stratégies et des agents spécialisés pour des tâches telles que la création de graphiques analytiques et leur agrégation pour l’interaction utilisateur.
Q6. Quel jeu de données a été utilisé pour l’évaluation quantitative ? Le code est-il open-source ?
Le jeu de données utilisé pour l’évaluation quantitative du système DB-GPT n’est pas explicitement mentionné dans les informations fournies. En revanche, le code de DB-GPT est open-source et disponible sur GitHub avec plus de 10,7k étoiles, permettant aux utilisateurs d’y accéder et de l’utiliser pour leurs propres besoins.
Q7. Les expériences et résultats de l’article apportent-ils un bon soutien aux hypothèses scientifiques à vérifier ? Analyse approfondie.
Les expériences et résultats présentés dans l’article fournissent un soutien substantiel aux hypothèses scientifiques à valider. L’article illustre une approche de Retrieval-Augmented Generation (RAG) pour les tâches NLP intensives en connaissances, démontrant l’efficacité de la méthode proposée. En exploitant cette approche, le système améliore la génération de réponses en intégrant les résultats de la recherche de connaissances pendant le processus d’inférence. Cette méthode optimise significativement le processus de génération de réponses en incorporant des informations pertinentes extraites de la base de connaissances. Les résultats suggèrent que le système intègre efficacement les stratégies de récupération et l’apprentissage contextuel interactif pour renforcer les réponses produites par le modèle de langage. Dans l’ensemble, les expériences et résultats apportent des preuves solides démontrant l’efficacité de l’approche proposée pour traiter les tâches NLP intensives en connaissances.
Q8. Quelles sont les contributions de cet article ?
L’article présente DB-GPT, une bibliothèque Python qui intègre les modèles de langage étendu (LLM) aux tâches d’interaction avec les données, améliorant ainsi l’expérience utilisateur et l’accessibilité. DB-GPT fournit des réponses contextuelles propulsées par les LLM, permettant aux utilisateurs de décrire leurs tâches en langage naturel et d’obtenir des résultats pertinents. De plus, DB-GPT peut gérer des tâches complexes, telles que l’analyse générative de données, grâce à un cadre Multi-Agents et au Agentic Workflow Expression Language (AWEL). La conception du système supporte le déploiement en environnements locaux, distribués et cloud, tout en assurant la confidentialité et la sécurité des données grâce au Service-oriented Multi-model Management Framework (SMMF).
Q9. Quels travaux pourraient être approfondis ?
Des recherches futures pourraient viser à renforcer les capacités des LLM dans les tâches d’interaction avec les données, en se concentrant particulièrement sur l’amélioration de la compréhension et des insights fournis aux utilisateurs. Il serait également bénéfique d’explorer le développement de cadres Multi-Agents plus indépendants de la tâche, afin d’élargir la gamme de tâches qu’ils peuvent traiter efficacement. Enfin, investiguer et améliorer les configurations sensibles à la confidentialité pour les interactions de données propulsées par LLM, afin de garantir la sécurité des données utilisateurs, constitue un domaine de recherche à approfondir.