Adaptation des connaissances des grands modèles de langage vers les systèmes de recommandation pour des applications industrielles réelles

Thème central
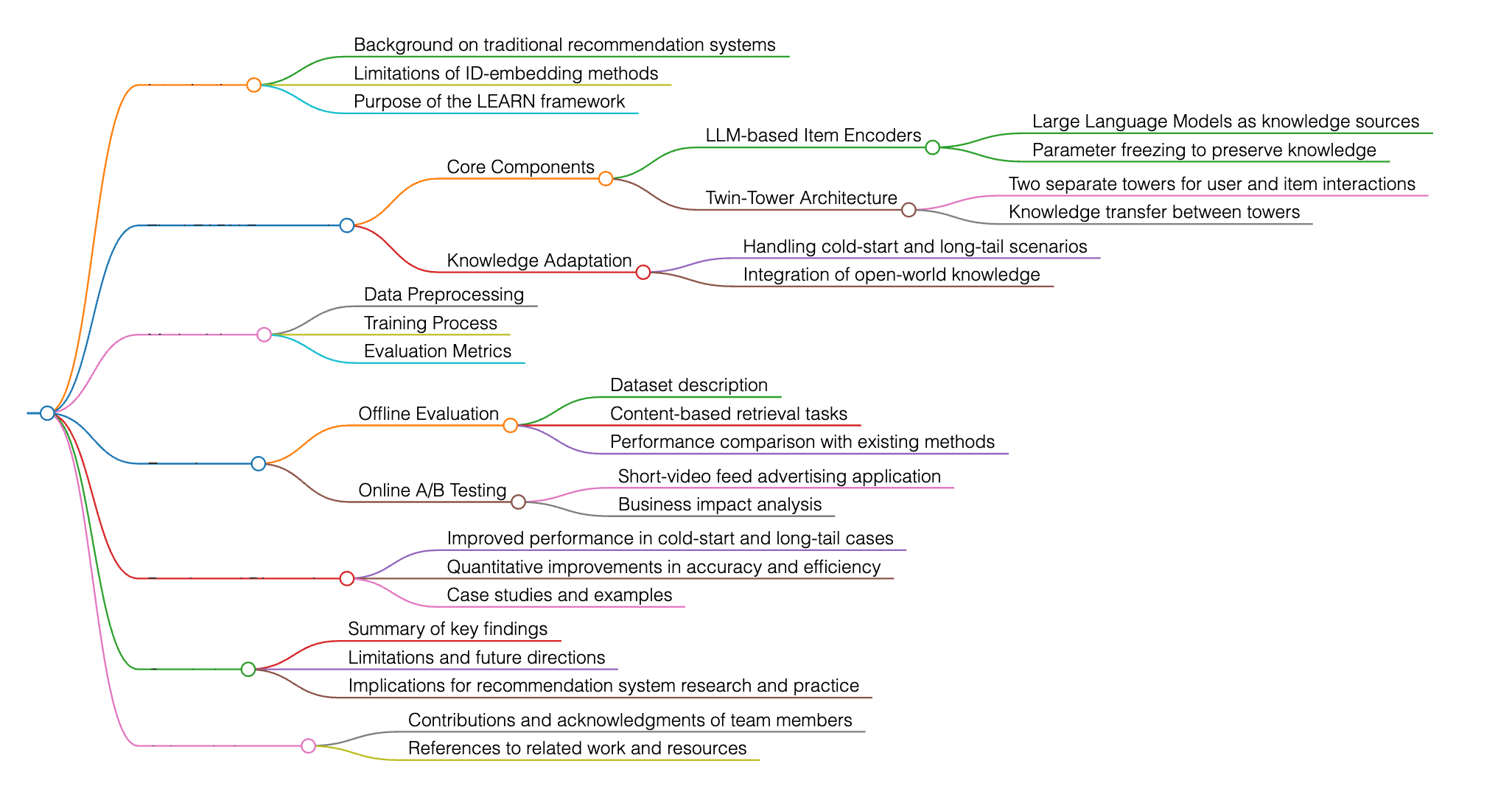
L’article présente le cadre LEARN (Knowledge Adaptation Recommendation pilotée par les LLM), qui enrichit les systèmes de recommandation traditionnels en intégrant des connaissances du monde ouvert issues des grands modèles de langage (LLM). Il répond aux limites des approches basées sur l’ID-embedding et améliore les performances dans les scénarios de cold start et de long tail en utilisant les LLM comme encodeurs d’items, en gelant leurs paramètres afin de préserver les connaissances, et en s’appuyant sur une architecture à double tour (twin-tower). Des expériences hors ligne et en ligne menées sur des jeux de données industriels démontrent l’efficacité de l’approche proposée, avec des résultats supérieurs aux méthodes existantes dans des tâches telles que la recherche basée sur le contenu et la publicité dans les flux de vidéos courtes, se traduisant par de meilleures performances et des bénéfices business mesurables.
Carte mentale
TL;DR
Quel problème l’article cherche-t-il à résoudre ? S’agit-il d’un problème nouveau ?
L’article vise à résoudre les défis liés à l’écart de domaine et au désalignement des objectifs d’entraînement lors de l’adaptation de grands modèles de langage (LLM) préentraînés à des tâches spécifiques telles que les systèmes de recommandation. Il propose l’approche LEARN (Llm-driven knowlEdge Adaptive RecommeNdation) afin de faire converger les connaissances du monde ouvert issues des LLM avec les connaissances collaboratives propres aux systèmes de recommandation.
Pour déterminer s’il s’agit d’un problème nouveau, des éléments de contexte ou des détails supplémentaires sont nécessaires pour formuler une réponse précise.
Quelle hypothèse scientifique cet article cherche-t-il à valider ?
L’article cherche à valider une hypothèse scientifique en s’appuyant sur une analyse expérimentale complète, incluant des tests A/B en ligne.
Quelles nouvelles idées, méthodes ou modèles l’article propose-t-il ? Quelles sont leurs caractéristiques et leurs avantages par rapport aux approches précédentes ?
L’article propose le cadre LEARN (Llm-driven knowlEdge Adaptive RecommeNdation), conçu pour agréger efficacement les connaissances du monde ouvert issues des grands modèles de langage (LLM) au sein des systèmes de recommandation (RS). Il introduit également les modules CEG et PCH, destinés à résoudre le problème de l’oubli catastrophique des connaissances du monde ouvert et à réduire l’écart de domaine entre les connaissances ouvertes et les connaissances collaboratives.
Contrefactuels et semifactuals dans l’argumentation abstraite : fondements formels, complexité et calcul
Cet article explore le raisonnement contrefactuel et semifactual dans le cadre des systèmes d’argumentation abstraite (Abstract Argumentation Frameworks, AF), en mettant l’accent sur leur complexité computationnelle et leur intégration dans des systèmes d’argumentation. L’étude définit ces concepts et souligne l’importance d’améliorer l’explicabilité en les encodant dans des AF faiblement contraints et en utilisant des solveurs ASP. En analysant la complexité de différents problèmes — tels que l’existence, la vérification et l’acceptabilité sous diverses sémantiques —, la recherche montre que ces tâches sont généralement plus complexes que les problèmes traditionnels. La contribution principale réside dans la proposition d’algorithmes et l’exploration d’applications visant à renforcer la prise de décision et le pouvoir persuasif des systèmes basés sur l’argumentation. Pour une analyse approfondie, il est recommandé de se référer aux détails et méthodologies présentés dans l’article.
Le cadre LEARN proposé offre des améliorations de performance significatives par rapport aux méthodes existantes, notamment en termes de revenus ainsi que des métriques Hit Rate (H) et NDCG pour les systèmes de recommandation, comme démontré dans l’étude. Comparé à des méthodes telles que SASRec et HSTU, LEARN obtient des gains notables sur des indicateurs comme H@50, H@200, N@50 et N@200, illustrant son efficacité dans les tâches de recommandation. En outre, LEARN traite explicitement l’écart de domaine entre les connaissances du monde ouvert et les connaissances collaboratives, offrant une approche plus robuste et adaptative pour des applications industrielles réelles.
Existe-t-il des travaux de recherche connexes ? Qui sont les chercheurs notables dans ce domaine ? Quelle est la clé de la solution proposée dans l’article ?
Des recherches relatives à l’adaptation des connaissances issues des grands modèles de langage (LLM) aux systèmes de recommandation pour des applications industrielles réelles ont déjà été menées. Ces travaux se concentrent sur l’exploitation des connaissances du monde ouvert intégrées dans les LLM afin d’améliorer les systèmes de recommandation, en traitant notamment des problématiques telles que l’oubli catastrophique et l’écart de domaine entre les connaissances collaboratives et les connaissances du monde ouvert. Parmi les chercheurs notables dans ce domaine figurent Yabin Zhang, Wenhui Yu, Erhan Zhang, Xu Chen, Lantao Hu, Peng Jiang et Kun Gai. D’autres chercheurs, tels que Qi Zhang, Jingjie Li, Qinglin Jia, Chuyuan Wang, Jieming Zhu, Zhaowei Wang et Xiuqiang He, ont également apporté des contributions importantes à ce champ de recherche. La solution clé proposée dans l’article repose sur l’intégration des connaissances du monde ouvert fournies par les LLM avec les connaissances collaboratives des systèmes de recommandation, afin d’améliorer les performances de recommandation. Cette approche vise à combler l’écart entre le domaine général du monde ouvert et le domaine spécifique des systèmes de recommandation, en exploitant les connaissances des LLM pour apporter une information incrémentale à forte valeur ajoutée.
Comment les expériences présentées dans l’article ont-elles été conçues ?
Les expériences ont été conçues en comparant la méthode proposée à des approches de pointe existantes, orientées vers des usages industriels, en utilisant le jeu de données Amazon Book Reviews 2014 afin de se rapprocher au plus près de scénarios industriels réels. Par ailleurs, une analyse expérimentale plus complète a été menée à travers des tests A/B en ligne, permettant de valider les hypothèses et d’évaluer les améliorations de performance en termes de CVR et de revenus par rapport à la méthode de référence.
Quel jeu de données est utilisé pour l’évaluation quantitative ? Le code est-il open source ?
Le jeu de données utilisé pour l’évaluation quantitative est un ensemble de données hors ligne à grande échelle, collecté à partir d’un scénario industriel réel. Le code est open source, et le chatbot Vicuna, qui atteint environ 90 % de la qualité de ChatGPT selon les évaluations, est disponible publiquement.
Les expériences et les résultats de l’article apportent-ils un bon soutien aux hypothèses scientifiques à vérifier ? Analyse.
Les expériences et les résultats présentés dans l’article apportent un soutien solide aux hypothèses scientifiques à vérifier. Grâce à des tests A/B en ligne et à un déploiement dans des systèmes de recommandation réels, l’étude met en évidence des améliorations substantielles et atteint des performances de niveau état de l’art sur des jeux de données à grande échelle, surpassant les approches précédentes. Les comparaisons avec d’autres méthodes ainsi que les métriques de performance rapportées démontrent clairement l’efficacité et la supériorité de l’approche proposée, validant ainsi les hypothèses scientifiques formulées.
Quelles sont les contributions de cet article ?
L’article introduit l’approche LEARN, qui fait converger les connaissances du monde ouvert issues des grands modèles de langage (LLM) avec les connaissances collaboratives des systèmes de recommandation, afin de répondre aux défis liés à l’écart de domaine et au désalignement des objectifs d’entraînement dans les systèmes de recommandation. Il propose également l’utilisation d’embeddings générés par les LLM pour les recommandations basées sur le contenu, en démontrant l’efficacité de ces représentations pour améliorer les performances de recommandation.
Quels axes de recherche peuvent être approfondis par la suite ?
Les travaux futurs peuvent approfondir l’intégration des grands modèles de langage (LLM) dans les systèmes de recommandation afin d’améliorer leurs performances, en particulier dans les scénarios de cold start et de recommandations pour des utilisateurs de longue traîne. L’exploitation des capacités des LLM préentraînés sur de vastes corpus textuels constitue une piste prometteuse pour renforcer les systèmes de recommandation par l’intégration de connaissances de domaine issues du monde ouvert.
En savoir plus
Le résumé ci-dessus a été généré automatiquement par Powerdrill.
Cliquez sur le lien pour voir la page de résumé et d'autres documents recommandés.