Optimisation discrète pour améliorer le nettoyage des données

Thème Central
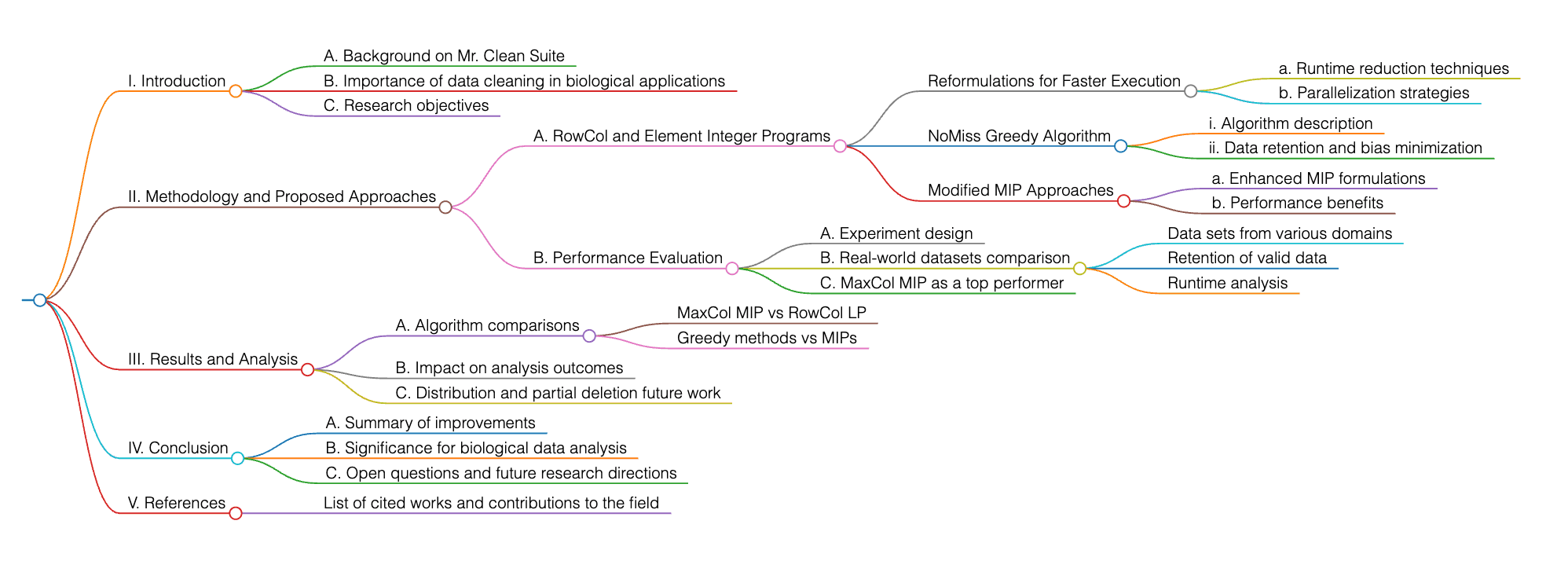
Cet article présente des améliorations des méthodes de nettoyage des données pour les éléments manquants, en se concentrant sur la suite Mr. Clean, en particulier les programmes entiers RowCol et Element Integer Programs. Les auteurs proposent des reformulations visant à réduire le temps d’exécution et à permettre la parallélisation, ce qui améliore les performances par rapport aux techniques traditionnelles. L’algorithme NoMiss Greedy et les approches MIP modifiées montrent une rétention significative des données tout en minimisant les biais.
Les expériences menées sur des ensembles de données réelles issus de différents domaines montrent que ces algorithmes surpassent les méthodes existantes, notamment pour préserver les données valides et gérer efficacement les temps de calcul. L’étude compare également différents algorithmes, tels que MaxCol MIP, RowCol LP et les méthodes gloutonnes, avec MaxCol MIP comme meilleur performer pour γ = 0,0.
Les travaux futurs incluent des versions distribuées et l’exploration de l’impact de la suppression partielle sur les résultats analytiques. Cette recherche contribue à une meilleure compréhension et à une gestion efficace des données manquantes dans diverses applications biologiques.
Carte Mentale
TL;DR
Quel problème l’article cherche-t-il à résoudre ? Est-ce un problème nouveau ?
L’article vise à résoudre le défi de la gestion des données manquantes dans le cadre du nettoyage des données. Il ne s’agit pas d’un problème nouveau dans les pipelines d’analyse de données, puisque la gestion des données manquantes est une étape cruciale pour garantir la précision et la fiabilité des résultats analytiques.
Quelle hypothèse scientifique cet article cherche-t-il à valider ?
L’étude cherche à valider l’hypothèse selon laquelle l’Element IP, un modèle mathématique développé pour maximiser la conservation des éléments valides dans les matrices de données grâce à l’introduction de variables de décision supplémentaires, permet de préserver le plus grand nombre d’éléments valides lorsqu’il est résolu à l’optimalité, sous des paramètres spécifiques.
Quelles nouvelles idées, méthodes ou modèles l’article propose-t-il ? Quelles sont leurs caractéristiques et avantages par rapport aux méthodes précédentes ?
L’article introduit un nouvel algorithme glouton conçu pour un cas particulier où γ = 0, améliorant ainsi la gestion des données manquantes dans les pipelines d’analyse. De plus, il présente l’algorithme NoMiss Greedy pour compléter les algorithmes existants de nettoyage des données, avec pour objectif d’améliorer la rétention des données et l’efficacité du traitement.
Le nouvel algorithme glouton combiné présenté dans l’article montre un équilibre optimal entre temps de calcul et conservation des éléments sur l’ensemble des expériences, se révélant le plus efficace parmi les algorithmes de suppression existants. Cet algorithme a permis de résoudre tous les problèmes et de conserver le plus grand nombre d’éléments dans la majorité des scénarios, démontrant ainsi son efficacité et sa performance dans la gestion des données manquantes. Comparé à ses homologues de Mr. Clean, l’algorithme NoMiss Greedy a montré une rétention des données améliorée et une vitesse de traitement supérieure, soulignant ses avantages par rapport aux méthodes traditionnelles.
Existe-t-il des recherches connexes ? Quels sont les chercheurs notables dans ce domaine ? Quelle est la clé de la solution mentionnée dans l’article ?
Oui, il existe un corpus important de recherches portant sur les méthodes de gestion des données manquantes dans divers domaines tels que l’épidémiologie, la génétique et l’analyse de données. Les chercheurs ont exploré différentes approches pour l’imputation des données manquantes, notamment pour le clustering et la classification de l’expression génique. Des études ont également comparé l’impact des techniques d’imputation sur ces méthodes de clustering et de classification. Parmi les chercheurs notables dans ce domaine, on peut citer Daniel A. Newman, Joost R. van Ginkel, Sharlee Climer, Alan R. Templeton, Weixiong Zhang, Kenneth Smith et Kevin Dunn. La clé de la solution mentionnée dans l’article réside dans l’utilisation du nouvel algorithme NoMiss Greedy, qui complète les IP Mr. Clean pour un scénario spécifique avec γ = 0,0. Cet algorithme est conçu pour gérer les données manquantes de manière efficace et performante dans le cadre de l’étude.
Comment les expériences de l’article ont-elles été conçues ?
Les expériences ont été conçues pour comparer différentes méthodes de gestion des données manquantes dans le contexte de l’analyse par score de propension. L’étude a impliqué divers algorithmes tels que RowCol IP, les algorithmes gloutons, DataRetainer et l’algorithme glouton Mr. Clean, entre autres, afin d’analyser leur performance en termes de rétention des éléments et de résolution des problèmes posés. L’objectif des expériences était d’évaluer l’efficacité de ces méthodes pour conserver le maximum d’éléments tout en traitant les données manquantes de manière efficiente.
Quel jeu de données a été utilisé pour l’évaluation quantitative ? Le code est-il open source ?
Le jeu de données utilisé pour l’évaluation quantitative se compose de 50 ensembles de données où le nombre de lignes est inférieur au nombre de colonnes, ce qui améliore l’efficacité des algorithmes. Le code utilisé dans l’évaluation n’est pas explicitement mentionné comme étant open source dans les informations fournies.
Les expériences et résultats soutiennent-ils les hypothèses scientifiques à vérifier ? Analyse :
Les expériences et résultats présentés dans l’article apportent un soutien substantiel aux hypothèses scientifiques à vérifier. L’étude démontre l’efficacité de différents algorithmes pour la gestion des données manquantes, en illustrant leurs performances sur différents ensembles de données et scénarios. Ces résultats offrent des insights précieux sur l’efficacité et la fiabilité de ces méthodes pour les tâches d’imputation de données, contribuant significativement à la validation des hypothèses scientifiques liées au traitement des données manquantes.
Quelles sont les contributions de cet article ?
L’article contribue en introduisant un nouvel algorithme glouton conçu pour un cas particulier où γ = 0, ce qui simplifie les formulations de programmation linéaire pour les tâches de nettoyage des données. De plus, il propose une méthode pour réduire le nombre de contraintes dans le MaxCol IP, améliorant ainsi ses performances sur les ensembles de données petits et moyens.
Quels travaux peuvent être approfondis ?
Les travaux futurs peuvent se concentrer sur le nettoyage des données en explorant des techniques avancées de suppression et d’imputation pour gérer plus efficacement les données manquantes. La recherche pourrait également viser à améliorer les algorithmes existants, comme la suite Mr. Clean, pour optimiser la rétention des données et l’efficacité du traitement. Des investigations supplémentaires pourraient comparer différents algorithmes de suppression et leurs performances dans divers scénarios afin d’optimiser les processus de nettoyage des données.
En savoir plus
Le résumé ci-dessus a été généré automatiquement par Powerdrill.
Cliquez sur le lien pour consulter la page du résumé et d’autres articles recommandés.