Évaluer les résumés de texte générés par les grands modèles de langage avec GPT d’OpenAI

Thème Central
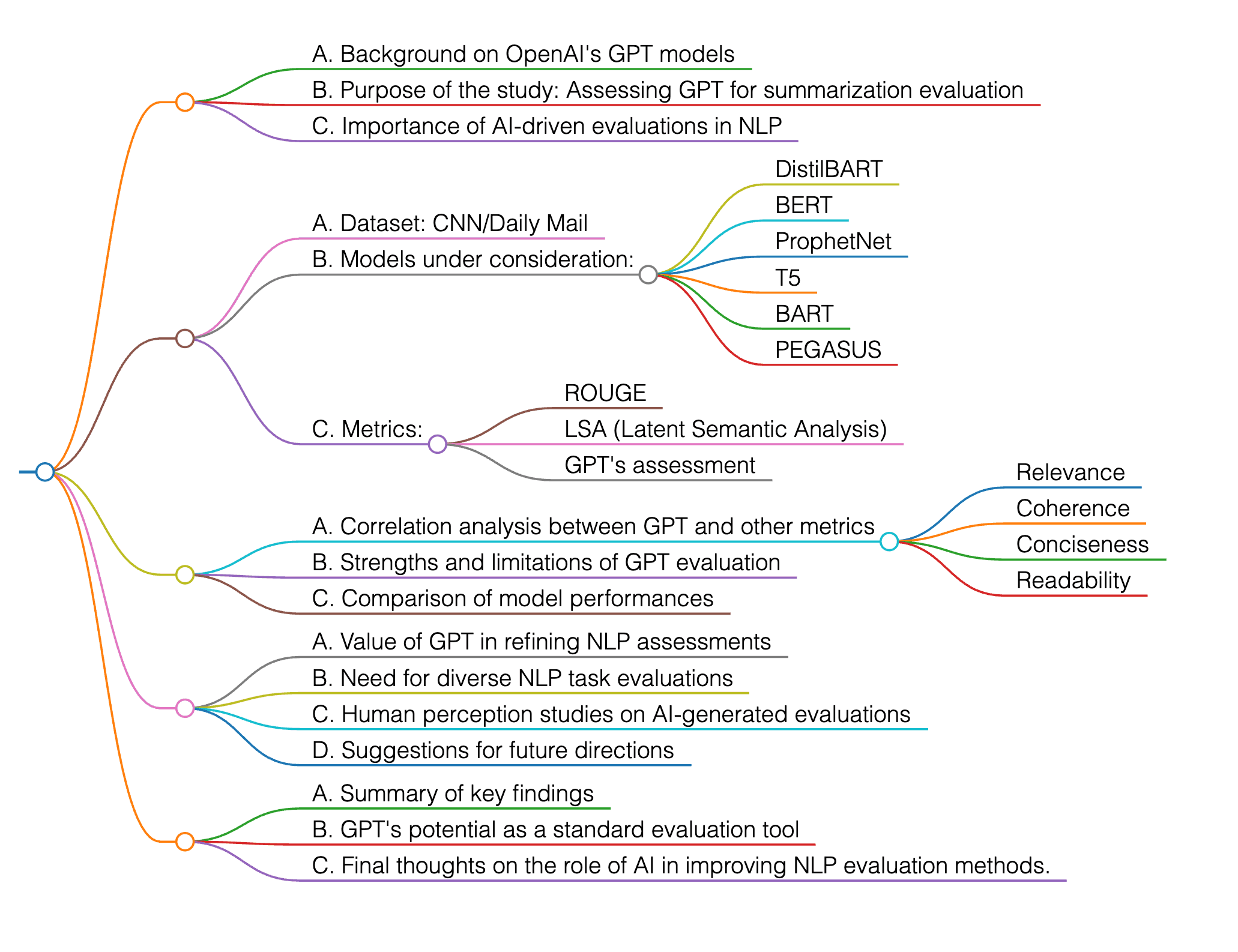
Cette recherche évalue les modèles GPT d’OpenAI en tant qu’évaluateurs de résumés générés par six modèles basés sur les transformers (DistilBART, BERT, ProphetNet, T5, BART et PEGASUS), en utilisant des métriques telles que ROUGE, LSA et l’évaluation propre de GPT. GPT montre de fortes corrélations, notamment en termes de pertinence et de cohérence, suggérant son potentiel comme outil précieux pour l’évaluation des résumés de texte.
L’étude analyse la performance des modèles sur le jeu de données CNN/Daily Mail, en mettant l’accent sur la concision, la pertinence, la cohérence et la lisibilité. Les résultats soulignent l’intérêt d’intégrer des évaluations pilotées par l’IA, comme GPT, pour affiner les évaluations dans les tâches de traitement automatique du langage (TAL), et proposent des pistes pour de futures recherches, notamment l’extension à divers types de tâches NLP et la compréhension de la perception humaine des évaluations générées par l’IA.
Carte Mentale
TL;DR
Quel problème cet article tente-t-il de résoudre ? S'agit-il d'un problème nouveau ?
Cet article vise à évaluer la qualité des résumés de texte en utilisant les modèles GPT d’OpenAI ainsi que des métriques traditionnelles, afin d’améliorer l’évaluation des résumés. L’étude répond au besoin d’un cadre d’évaluation complet combinant des outils pilotés par l’IA et des métriques établies pour offrir une compréhension plus fine de l’efficacité des résumés. L’intégration des modèles GPT avec des métriques conventionnelles fournit des perspectives pour de futures recherches en traitement automatique du langage (TAL), contribuant au développement de méthodes d’évaluation plus robustes dans ce domaine.
Quelle hypothèse scientifique cet article cherche-t-il à valider ?
Cet article vise à valider l’efficacité des modèles GPT d’OpenAI en tant qu’évaluateurs indépendants de résumés de texte générés par différents modèles basés sur les transformers, tels que DistilBART, BERT, ProphetNet, T5, BART et PEGASUS, en utilisant des métriques traditionnelles telles que ROUGE et l’analyse sémantique latente (LSA).
Quelles nouvelles idées, méthodes ou modèles cet article propose-t-il ? Quelles sont leurs caractéristiques et avantages par rapport aux méthodes précédentes ?
L’article propose plusieurs idées et approches innovantes pour la recherche future en traitement automatique du langage (TAL). Une proposition clé consiste à étendre le cadre d’évaluation pour inclure diverses tâches TAL, telles que l’analyse de sentiment ou la reconnaissance d’entités, afin de mieux comprendre les capacités des modèles GPT. De plus, l’étude suggère d’explorer d’autres modèles basés sur les transformers non abordés dans cette recherche, afin d’analyser comment différentes architectures influencent l’efficacité des outils d’évaluation pilotés par l’IA. Une autre proposition importante est d’affiner la méthodologie d’intégration des évaluations basées sur l’IA avec les métriques traditionnelles, en développant éventuellement un modèle hybride combinant les forces des deux approches pour un système d’évaluation plus robuste.
Les caractéristiques et avantages de l’approche proposée dans cet article incluent une évaluation plus nuancée grâce à l’intégration d’outils d’IA comme GPT aux côtés de métriques traditionnelles telles que ROUGE et LSA. Cette combinaison permet une évaluation complète des résumés de texte, mettant en évidence les points forts et les axes d’amélioration en termes de concision, fidélité au contenu, préservation sémantique et lisibilité. Par rapport aux méthodes précédentes, l’étude suggère que GPT tend à attribuer des scores plus élevés, ce qui pourrait refléter sa capacité à prendre en compte un éventail plus large de facteurs lors de l’évaluation, capturant ainsi des nuances que les métriques traditionnelles peuvent négliger. De plus, les évaluations de GPT, notamment en pertinence et cohérence, montrent une forte corrélation avec les métriques classiques, démontrant ainsi l’efficacité de GPT pour évaluer ces aspects des résumés.
Existe-t-il des recherches connexes ? Qui sont les chercheurs remarquables dans ce domaine ? Quelle est la clé de la solution mentionnée dans l’article ?
Oui, des recherches connexes existent dans le domaine de l’évaluation des résumés de texte à l’aide des modèles GPT d’OpenAI. Ces études ont exploré l’efficacité des modèles GPT en tant qu’évaluateurs indépendants de résumés générés par divers modèles basés sur les transformers, tels que DistilBART, BERT, ProphetNet, T5, BART et PEGASUS. Les chercheurs ont intégré des outils pilotés par l’IA avec des métriques établies pour développer des méthodes d’évaluation plus complètes pour les tâches de traitement automatique du langage (TAL). Parmi les chercheurs remarquables dans le domaine du résumé de texte et du TAL figurent Yang Liu et Mirella Lapata, Ashish Vaswani et al., Mike Lewis et al., ainsi que Hasna Chouikhi et Mohammed Alsuhaibani. Ces chercheurs ont apporté des contributions importantes au développement des modèles transformers, des techniques de résumé de texte et de l’évaluation des résumés à l’aide d’outils IA et de métriques traditionnelles. La clé de la solution mentionnée dans l’article réside dans l’intégration d’outils pilotés par l’IA, comme le modèle GPT d’OpenAI, avec des métriques établies pour l’évaluation des résumés de texte. Cette combinaison permet une méthode d’évaluation plus complète et nuancée, améliorant la qualité de l’évaluation des résumés en prenant en compte un éventail plus large de facteurs.
Comment les expériences ont-elles été conçues dans l’article ?
Les expériences ont été conçues pour évaluer les résumés de texte générés par divers modèles basés sur les transformers, notamment DistilBART, BERT, ProphetNet, T5, BART et PEGASUS, en utilisant des métriques traditionnelles telles que ROUGE et l’analyse sémantique latente (LSA). L’étude a adopté une approche d’évaluation basée sur les métriques, utilisant des indicateurs quantitatifs établis comme le taux de compression, ROUGE, LSA et les tests de lisibilité Flesch-Kincaid pour évaluer la qualité des résumés.
De plus, les modèles GPT ont été intégrés non pas comme générateurs de résumés, mais comme évaluateurs, afin d’estimer de manière indépendante la qualité des résumés sans métriques prédéfinies, fournissant ainsi des perspectives complémentaires aux méthodes d’évaluation traditionnelles.
Quel jeu de données a été utilisé pour l’évaluation quantitative ? Le code est-il open source ?
Pour l’évaluation quantitative, l’étude a utilisé plusieurs métriques établies, notamment le taux de compression, ROUGE, l’analyse sémantique latente (LSA) et les tests de lisibilité Flesch-Kincaid. Ces métriques ont été employées pour évaluer la qualité des résumés de texte générés par divers modèles de langage de grande taille (LLMs).
L’ouverture du code dépend du contexte spécifique ou de la source concernée ; il est nécessaire de préciser le code en question pour savoir s’il est accessible en open source.
Les expériences et résultats soutiennent-ils les hypothèses scientifiques à vérifier ? Analyse :
Les expériences et résultats présentés dans l’article apportent un soutien solide aux hypothèses scientifiques à vérifier. L’étude intègre des outils pilotés par l’IA avec des métriques établies, offrant des perspectives précieuses pour la recherche future en traitement automatique du langage (TAL) et améliorant le processus d’évaluation.
Quelles sont les contributions de cet article ?
L’article contribue en évaluant les résumés de texte à l’aide de métriques traditionnelles telles que ROUGE et LSA, en parallèle avec le modèle GPT d’OpenAI. Il met en évidence l’efficacité de GPT pour évaluer la pertinence et la cohérence des résumés, souvent en attribuant des scores plus élevés que les métriques traditionnelles, indiquant une approche d’évaluation plus globale. De plus, l’étude démontre l’intérêt d’intégrer des outils d’IA comme GPT dans le processus d’évaluation, offrant une perspective plus nuancée par rapport aux seules métriques traditionnelles.
Quels travaux peuvent être approfondis ?
Les travaux futurs dans le domaine du résumé de texte pourraient porter sur l’amélioration de la concision des résumés sans compromettre la complétude du contenu, en expérimentant différentes approches de pré-entraînement et de fine-tuning visant à équilibrer brièveté et détails dans la génération de résumés. Par ailleurs, explorer d’autres modèles basés sur les transformers non couverts par les études précédentes pourrait fournir des insights sur la manière dont différentes architectures influencent l’efficacité des outils d’évaluation pilotés par l’IA.
Lire la suite
Le résumé ci-dessus a été généré automatiquement par Powerdrill.
Cliquez sur le lien pour consulter la page du résumé et découvrir d’autres articles recommandés.