Revue de littérature et cadre d’évaluation humaine des modèles de langage génératifs dans le secteur de la santé

Thème Central
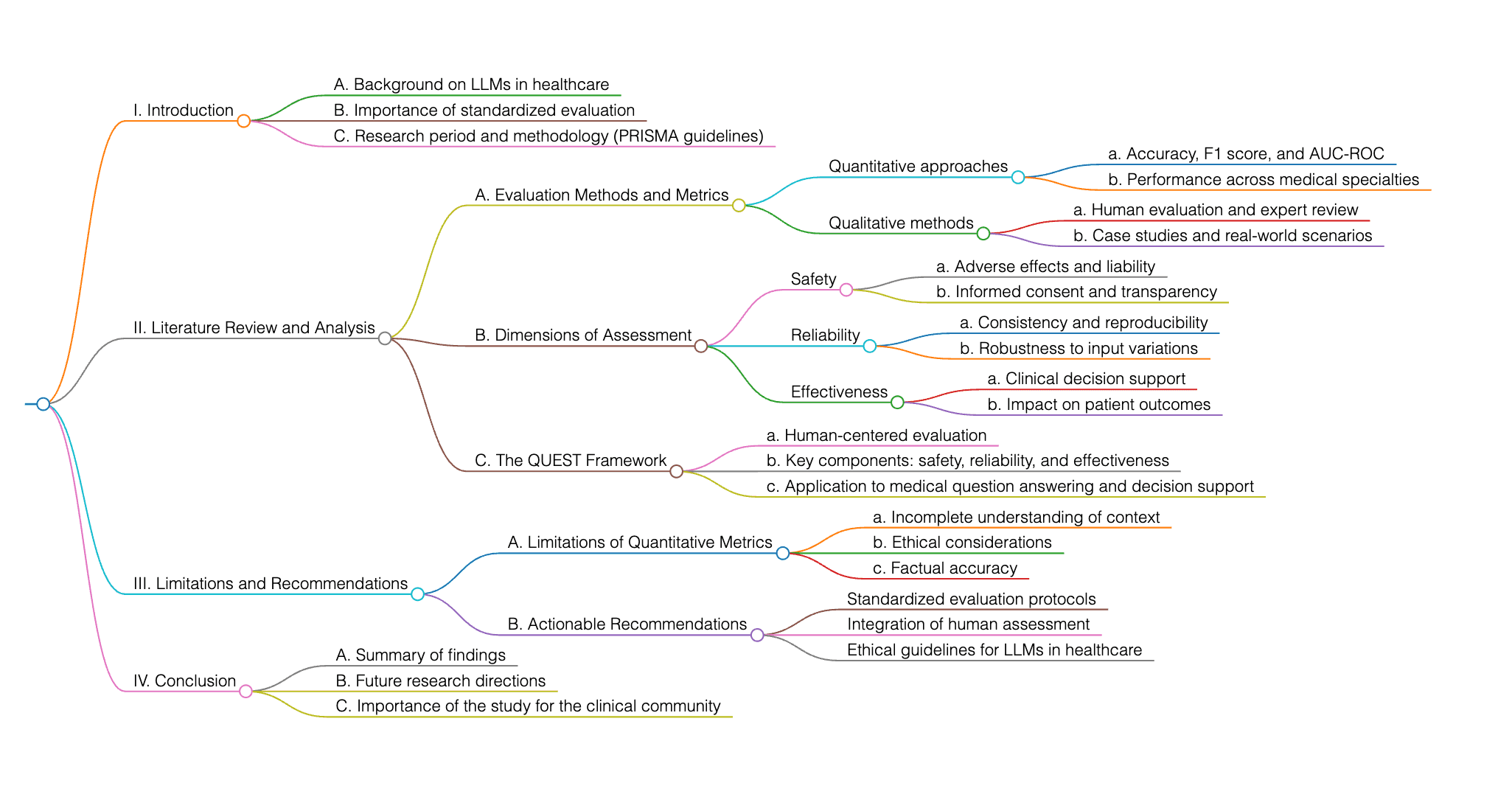
Cette étude examine l’évaluation des grands modèles de langage (LLM) dans le secteur de la santé, en mettant l’accent sur les approches standardisées en raison de la complexité de l’évaluation du contenu médical généré par l’IA. Les chercheurs ont mené une revue complète de 2018 à 2024, en suivant les directives PRISMA, afin d’analyser les méthodes, les métriques et les dimensions d’évaluation dans différentes spécialités médicales. Le cadre proposé, QUEST, met en lumière la nécessité d’une évaluation humaine pour garantir la sécurité, la fiabilité et l’efficacité des modèles, notamment dans des domaines tels que la réponse aux questions médicales et le soutien à la décision. L’objectif de l’étude est de fournir un cadre d’évaluation standardisé, de combler les lacunes de la recherche actuelle et de proposer des recommandations concrètes pour la communauté clinique afin d’améliorer la fiabilité des LLMs dans les applications de santé. Elle aborde également les limites des métriques quantitatives et l’importance de l’évaluation humaine pour garantir l’exactitude des faits et les considérations éthiques.ine pour garantir l'exactitude factuelle et les considérations éthiques.
Carte Mentale
TL;DR
Quel problème le document tente-t-il de résoudre ? S'agit-il d'un nouveau problème ?
L'objectif de cet article est de résoudre la limitation liée à la dépendance exclusive aux métriques d'évaluation quantitatives, telles que l'exactitude et les scores F-1, qui ne permettent pas toujours de valider entièrement la précision du texte généré et ne capturent pas la compréhension détaillée requise pour une évaluation rigoureuse dans la pratique clinique. Il met en avant l'importance des évaluations qualitatives par des évaluateurs humains, considérées comme la norme d’or pour garantir que les sorties des modèles de langage respectent les standards de fiabilité, d'exactitude factuelle, de sécurité et de conformité éthique. Pour déterminer s'il s'agit d'un problème nouveau, davantage de contexte ou d'informations spécifiques sur le problème en question sont nécessaires.
Quelle hypothèse scientifique cet article cherche-t-il à valider ?
Cet article cherche à valider l'hypothèse liée à la signification statistique des différences observées entre la performance d'un LLM et une référence, généralement évaluée à l'aide de la valeur P (P-Value).
Quelles nouvelles idées, méthodes ou modèles l'article propose-t-il ? Quelles sont les caractéristiques et les avantages par rapport aux méthodes précédentes ?
L'article propose des lignes directrices pour l'évaluation humaine des grands modèles de langage (LLM) afin de relever les défis liés à l'évaluation de ces modèles, notamment les limitations de l'échelle, de la taille de l'échantillon et des mesures d'évaluation. De plus, l'étude vise à combler le fossé entre les promesses des LLM et les exigences dans le secteur de la santé en proposant un cadre complet pour l'évaluation humaine. Le cadre proposé met l'accent sur l'importance des évaluations qualitatives par des évaluateurs humains, qui sont considérées comme la norme d’or pour garantir la fiabilité, l'exactitude factuelle, la sécurité et la conformité éthique des sorties des LLM. Cette approche contraste avec l'utilisation prédominante de métriques automatisées dans la littérature actuelle, mettant en lumière la nécessité d'une analyse plus complète des méthodologies d'évaluation humaine dans les applications de santé. Le cadre vise à pallier les limitations des métriques quantitatives en se concentrant sur des évaluations qualitatives, essentielles pour une évaluation rigoureuse dans la pratique clinique.
Existe-t-il des recherches liées ? Qui sont les chercheurs notables dans ce domaine ? Quelle est la clé de la solution mentionnée dans l'article ?
Oui, plusieurs études liées existent dans ce domaine. Des recherches ont été menées pour évaluer la performance de modèles de langage comme ChatGPT dans différentes spécialités médicales, y compris les propositions diagnostiques et les décisions cliniques. Ces études ont utilisé des tests statistiques tels que les tests T, les examens du Chi-carré, et les tests de McNemar pour évaluer la précision et la fiabilité des preuves médicales compilées par les modèles d'IA par rapport aux praticiens de la santé. De plus, des discussions ont eu lieu sur les meilleures pratiques en matière de conception et de suivi des évaluations humaines, ainsi que sur les limitations et les études de cas dans différentes spécialités médicales. Parmi les chercheurs notables dans ce domaine, on retrouve Sinha, R. K., Roy, A. D., Kumar, N., Mondal, H., et Sinha, R., qui ont exploré l’applicabilité de ChatGPT pour résoudre des problèmes complexes en pathologie. En outre, Ayers et al. ont mené une étude comparant les réponses de ChatGPT à celles fournies par des médecins dans les fils "Ask Doctors" de Reddit, en mettant l'accent sur la qualité et la pertinence des conseils. Ces chercheurs ont contribué de manière significative à l'évaluation et à l'application des modèles d'IA dans les environnements de santé. La clé de la solution mentionnée dans l'article réside dans le développement de cadres d'évaluation appropriés qui s'alignent sur les valeurs humaines, en particulier dans le contexte des applications des modèles de langage (LLM) en médecine.
Comment les expériences de l'article ont-elles été conçues ?
Les expériences de l'article ont été conçues en comparant les réponses de ChatGPT à celles fournies par des médecins dans les fils "Ask Doctors" de Reddit, en utilisant des tests du Chi-carré pour déterminer les différences dans la qualité et la pertinence des conseils. Les études ont également envisagé de tester les modèles de langage (LLM) dans des scénarios contrôlés et réels afin d'évaluer leur performance.
Quel est l'ensemble de données utilisé pour l’évaluation quantitative ? Le code est-il open-source ?
L'ensemble de données utilisé pour l’évaluation quantitative dans les applications de santé comprend souvent des métriques telles que la précision, les scores F-1, et l'aire sous la courbe de la caractéristique de fonctionnement du récepteur (AUCROC). Ces métriques sont couramment utilisées pour évaluer la performance des modèles de langage (LLM) dans divers contextes médicaux, mais elles peuvent ne pas saisir entièrement la compréhension nuancée nécessaire pour une évaluation rigoureuse dans la pratique clinique. Le code n’est pas open-source, car il est mentionné que des modèles open-source comme Llama de Meta ne figurent pas parmi les principaux modèles utilisés dans les études examinées.
Les expériences et résultats de l'article apportent-ils un bon soutien aux hypothèses scientifiques à vérifier ? Analysez.
Les articles de recherche présentent une variété d’expériences et de résultats liés aux modèles de langage dans le domaine de la santé. Par exemple, Tang et al. ont utilisé un test T pour comparer la précision des preuves médicales compilées par ChatGPT par rapport aux praticiens de la santé. De plus, Ayers et al. ont comparé les réponses de ChatGPT à celles fournies par des médecins dans les fils "Ask Doctors" de Reddit, en utilisant des tests du Chi-carré pour évaluer la qualité et la pertinence des conseils. Ces expériences visaient à évaluer les performances et les capacités des modèles de langage dans des contextes médicaux. Les hypothèses scientifiques présentées dans les articles de recherche peuvent varier en fonction de l’objectif de l’étude. Par exemple, certaines études peuvent viser à évaluer la performance des modèles de langage (LLM) dans des tâches ou des scénarios spécifiques, en testant la signification statistique des différences observées. D’autres peuvent comparer les réponses des LLM à celles des experts humains pour évaluer la qualité et la pertinence, en utilisant des tests statistiques comme le Chi-carré pour identifier des différences significatives. De plus, la recherche peut explorer la fiabilité et l’utilité des réponses générées par les LLM dans divers domaines, tels que la recherche scientifique ou les applications cliniques. Pour fournir une analyse précise, il serait nécessaire de disposer d'informations plus spécifiques concernant l'article, comme le titre, les auteurs, la question de recherche, la méthodologie et les résultats clés. Ces informations me permettront d’évaluer la qualité des expériences et des résultats par rapport aux hypothèses scientifiques testées. N’hésitez pas à fournir plus de détails afin que je puisse vous aider davantage.
Quelles sont les contributions de cet article ?
Les contributions de cet article incluent la conceptualisation, la conception et l'organisation de l’étude, l'analyse des résultats, ainsi que la rédaction, la révision et la réécriture de l'article par T.Y.C.T. et S.S. De plus, S.K., A.V.S., K.P., K.R.M., H.O. et X.W. ont contribué à l’analyse des résultats, ainsi qu’à la rédaction, la révision et la réécriture de l'article. En outre, S.V., S.F., P.M., G.C., C.S. et Y.P. ont participé à la rédaction, la révision et la réécriture de l'article.
Quel travail peut être approfondi ?
Un travail plus approfondi peut être réalisé dans divers domaines, tels que l'exploration des dimensions de l’évaluation humaine à travers différentes spécialités médicales, la discussion des meilleures pratiques pour concevoir et suivre les évaluations humaines, l’identification des limitations et des méthodes pour les surmonter, ainsi que la fourniture d’études de cas dans différentes tâches et spécialités médicales.
Lire la suite
Le résumé ci-dessus a été généré automatiquement par Powerdrill.
Cliquez sur le lien pour consulter la page de résumé et d'autres articles recommandés.