Cómo mover tu flujo de trabajo de IA a un nuevo agente sin perder el contexto, la memoria ni el trabajo previo (Guía 2026)

Introducción
El panorama de la IA se mueve increíblemente rápido. Una semana dependes en gran medida de ChatGPT; la siguiente, quieres probar las capacidades de programación superiores de Claude, o quizá estés pasando a agentes especializados como OpenClaw o Hermes Agent.
Cambiar de herramientas para una mejor especialización de tareas, por preferencia del equipo o por diferencias de capacidad es algo común. Sin embargo, los usuarios se dan cuenta rápidamente de que el verdadero desafío no es cambiar de herramienta, sino preservar la continuidad del flujo de trabajo.
Cuando te mueves a un nuevo agente, básicamente estás entrando en una oficina vacía. Tus archivos, notas, contexto del proyecto, instrucciones recurrentes y entregables parciales quedan varados en la herramienta anterior. Si quieres cambiar de agentes de IA sin empezar de cero, necesitas una estrategia para una memoria de IA portátil.
En esta guía, exploraremos por qué migrar un flujo de trabajo de IA es estructuralmente difícil, por qué fallan los atajos de migración habituales y cómo usar una capa de memoria persistente para garantizar el intercambio de contexto entre agentes.
Respuesta rápida: cómo mover tu flujo de trabajo de IA a un nuevo agente sin perder contexto
Para mover tu flujo de trabajo de IA a un nuevo agente sin perder contexto, memoria ni trabajo previo, necesitas desacoplar tu memoria de tu interfaz de chat. Sigue estos pasos básicos:
Adopta una capa de memoria portátil (como MemoryLake) para actuar como un segundo cerebro persistente para tus sistemas de IA.
Centraliza tus documentos y datos subiendo tus archivos, notas y conclusiones previas a esta capa independiente en lugar de hacerlo directamente en un solo agente.
Conecta tu nuevo agente de IA a esta capa de memoria mediante una API, un plugin o MCP (Protocolo de Contexto del Modelo).
Configura tu nuevo agente para que extraiga la memoria existente del proyecto, asegurando la continuidad del flujo de trabajo sin tener que empezar de nuevo ni volver a subir archivos.
Por qué mover un flujo de trabajo de IA es más difícil de lo que parece
Cuando migras un flujo de trabajo de IA a otro agente, no solo estás cambiando la interfaz en la que escribes. Estás intentando mover una red compleja e interconectada de contexto. Las herramientas de IA se convierten naturalmente en silos; cuanto más las usas, más contexto acumulan.
Qué suele perderse cuando cambias de agentes de IA
Si simplemente abres una nueva pestaña y empiezas a escribirle a un nuevo agente, varios componentes críticos de tu trabajo se quedan atrás:
Archivos subidos: los PDF, hojas de cálculo y documentos de Word que pasaste horas subiendo y explicando.
Notas y conclusiones previas: las decisiones estratégicas, resúmenes e investigación sintetizada que generó el agente anterior.
Contexto construido con el tiempo: la comprensión matizada de los objetivos, el tono y las restricciones de tu proyecto que la IA aprendió a lo largo de docenas de interacciones.
Continuidad del flujo de trabajo: la lógica en curso, paso a paso, de un proyecto de varios días.
Instrucciones previas: reglas recurrentes, preferencias de formato y memoria a nivel de proyecto.
Por qué fallan los atajos de migración habituales
La mayoría de los usuarios intenta resolver por la fuerza el cambio de agente mediante soluciones manuales. Desafortunadamente, estos métodos rara vez preservan la verdadera continuidad del flujo de trabajo.
Copiar y pegar: copiar largas cadenas de texto de un agente a otro genera prompts desordenados y pesados en tokens que confunden al nuevo modelo.
Exportaciones de chat: exportar el historial de chat te da un archivo de texto estático, no un sistema de memoria con capacidad de búsqueda y consciente de los documentos.
Volver a subir documentos: volver a subir manualmente cada archivo desperdicia tiempo y borra por completo las ideas históricas que el agente anterior ya había derivado de esos archivos.
Rellenar el prompt: intentar meter todo el contexto de tu proyecto en un único "superprompt" a menudo supera las ventanas de contexto y provoca un rendimiento degradado del modelo.
Cómo se ve una mejor configuración para migrar flujos de trabajo
El objetivo de migrar un flujo de trabajo de IA no es simplemente mover registros de chat. El objetivo es preservar contexto reutilizable, documentos, notas y trabajo previo en una capa portátil.
En lugar de tratar a tu agente de IA como el procesador (el cerebro) y el almacenamiento (la memoria), necesitas separar ambos. Al introducir una capa de memoria persistente para flujos de trabajo de IA, creas un "pasaporte de memoria". Esto te permite conectar cualquier agente nuevo a tu red de conocimiento existente.
Aquí es donde entra en juego una infraestructura como MemoryLake. MemoryLake está diseñado para ser una capa de memoria persistente para sistemas de IA. No es solo un exportador de historial de chat; es una capa de memoria portátil entre herramientas, modelos, sesiones y agentes. Al actuar como una infraestructura de memoria consciente de documentos y de flujos de trabajo, ayuda a los usuarios a moverse entre agentes sin empezar desde cero.
Paso a paso: usar MemoryLake para mover tu flujo de trabajo a un nuevo agente
Si quieres migrar tu flujo de trabajo de IA a otro agente sin perder tu trabajo previo, aquí tienes un flujo de migración práctico usando MemoryLake.
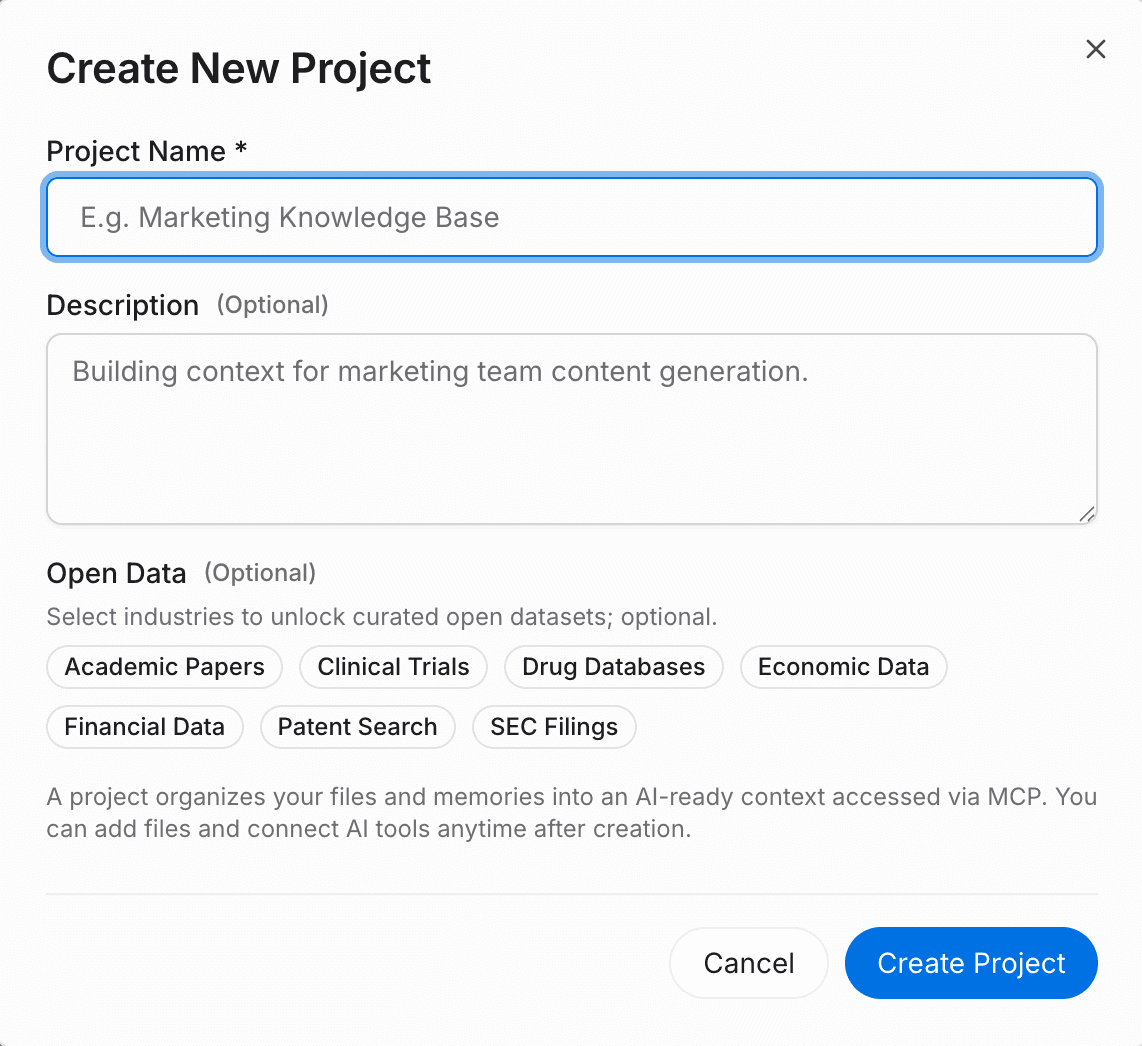
Paso 1: crea un proyecto y centraliza tus archivos y datos
El primer paso para lograr memoria de IA portátil es mover tus materiales sin procesar de tu agente antiguo a una capa persistente.
Crea un nuevo proyecto en MemoryLake.
Haz clic en el botón de adjuntar para subir tus documentos principales. La plataforma admite varios formatos, incluidos PDF, Word, Excel y Markdown.
MemoryLake analiza e indexa automáticamente el contenido, convirtiéndolo en memoria reutilizable.
También puedes conectar fuentes de datos externas directamente en la sección de archivos.
Valor de la migración: al hacer esto una sola vez en una capa persistente, mantienes el contexto de los documentos portátil. Eliminas por completo la necesidad de volver a subir archivos cada vez que cambias de herramientas de IA.
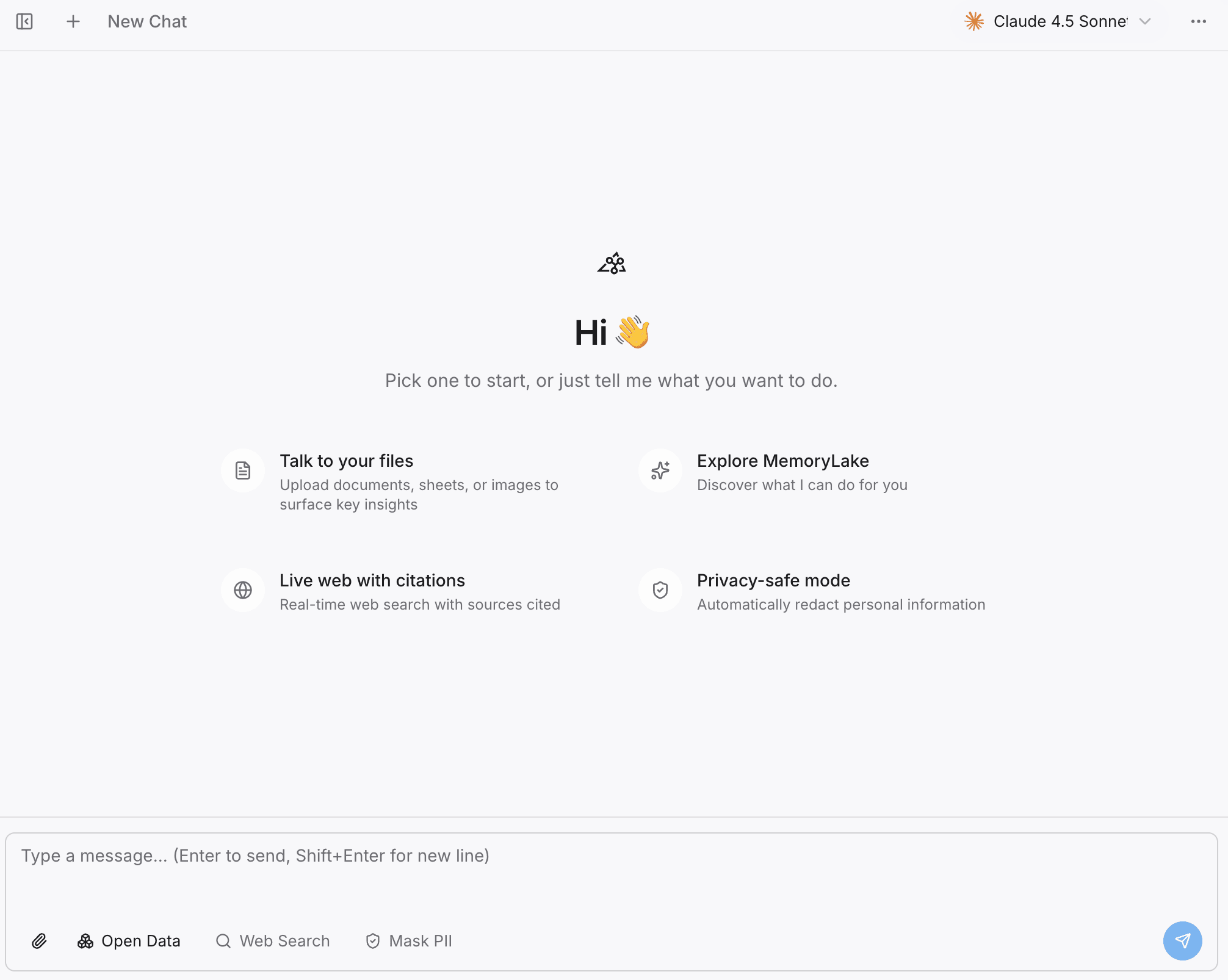
Paso 2: prueba las capacidades de búsqueda y diálogo
Antes de pasar a tu nuevo agente externo, verifica que tu contexto se haya preservado correctamente.
Abre el Playground de MemoryLake.
Haz preguntas directamente sobre la memoria de tu proyecto para asegurarte de que el sistema recupera con precisión tus notas, trabajo previo e ideas de los documentos.
Valor de la migración: esto garantiza que tu trabajo previo sea realmente utilizable y se pueda buscar, asegurando la continuidad del flujo de trabajo incluso antes de conectar tu nueva herramienta.
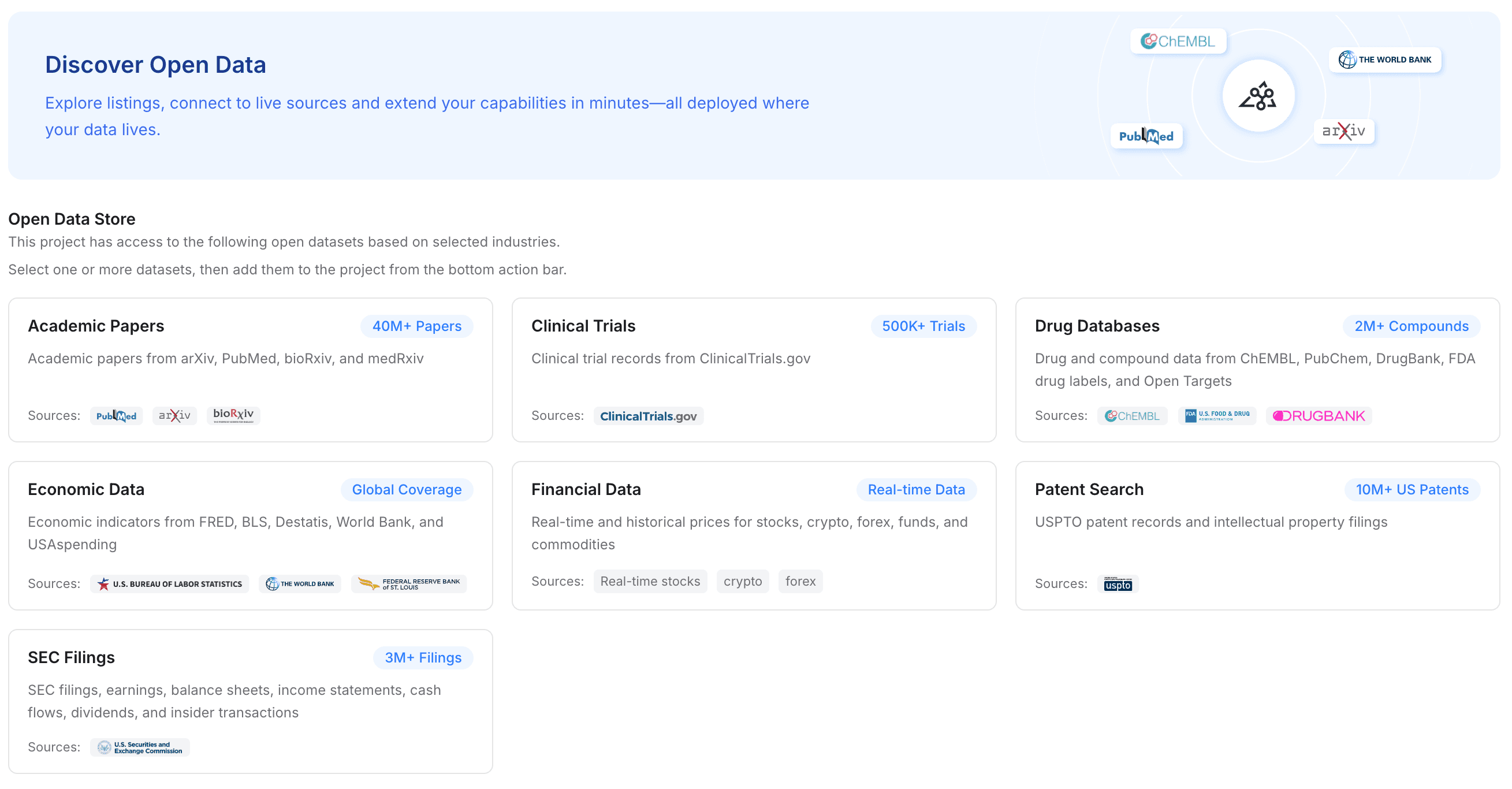
Paso 3: añade datos abiertos de la industria para potenciar tu proyecto
A menudo, al pasar a un nuevo agente, quieres que rinda mejor que el anterior. MemoryLake te permite ampliar tu contexto personal con un conocimiento más amplio de la industria.
Haz clic para añadir "Datos abiertos" a tu proyecto.
Selecciona entre conjuntos de datos gratuitos y disponibles de la industria para mejorar al instante el conocimiento del dominio de tu proyecto.
Según la industria que elijas, la documentación pública resalta el acceso a conjuntos de datos como artículos académicos, ensayos clínicos, bases de datos de medicamentos, datos económicos, datos financieros, búsquedas de patentes y presentaciones ante la SEC.
Valor de la migración: esto hace que tu nuevo agente sea útil mucho más rápido. En lugar de pasar horas enseñando a un nuevo modelo sobre los estándares de la industria, inyectas memoria altamente estructurada y específica del dominio directamente en el flujo de trabajo.
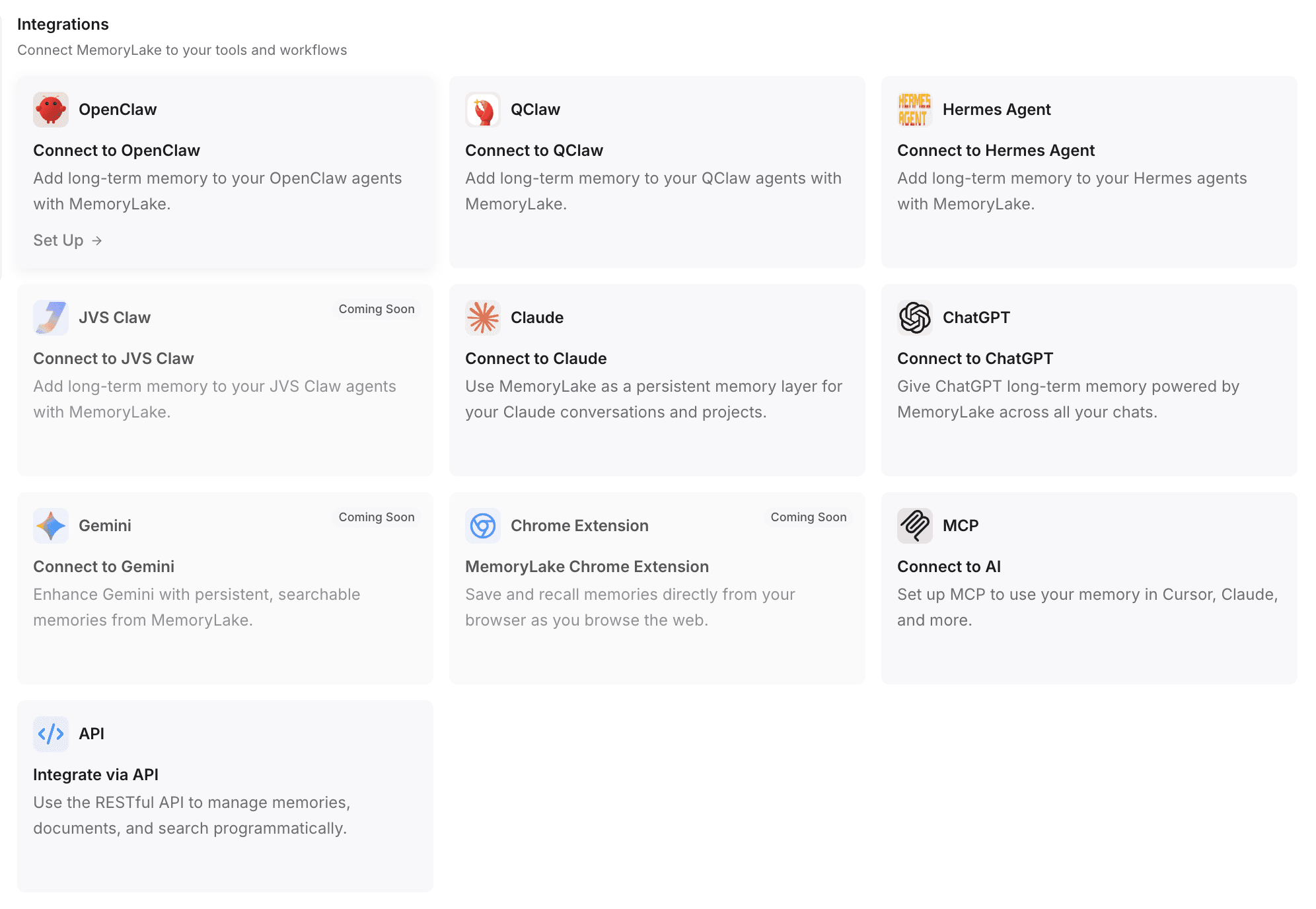
Paso 4: conecta MemoryLake con tus herramientas y flujos de trabajo
El paso final es conectar esta capa de memoria persistente a tu nuevo agente de IA.
Ve a la configuración de API y elige o crea tu propia clave de API.
Para configuración automatizada: según el flujo de configuración documentado, a menudo puedes usar comandos de configuración automática. Por ejemplo, si estás migrando a OpenClaw, puedes copiar la guía de integración y pegarla directamente en OpenClaw. El agente instalará automáticamente el plugin necesario, completará la configuración y reiniciará su puerta de enlace.
Para otras herramientas: MemoryLake admite integraciones con ChatGPT, Claude, OpenClaw, Hermes Agent y otras herramientas mediante plugins o instalaciones con 1 clic (a menudo requiriendo solo un único comando para ejecutarse).
Para flujos de trabajo personalizados: también puedes lograr una integración programática mediante API o conexiones de estilo MCP (Protocolo de Contexto del Modelo).
Valor de la migración: así es como logras memoria entre agentes. Tu nuevo agente tiene acceso inmediato a exactamente los mismos archivos, notas y contexto que el anterior. Evitas reconstruir prompts y reduces el reinicio del flujo de trabajo a cero.
Errores comunes que debes evitar al migrar flujos de trabajo de IA
Confundir registros de chat con memoria: descargar un archivo
.txtde tu historial de ChatGPT y subirlo a Claude no funcionará bien. Los registros de chat no estructurados diluyen el contexto. Necesitas un sistema de memoria estructurado y consciente de los documentos.Migrar herramienta por herramienta: si configuras instrucciones personalizadas dentro de Claude, esas instrucciones quedan atrapadas en Claude. Mantén los prompts del sistema, las reglas recurrentes y el contexto crítico del proyecto en una capa agnóstica a la herramienta.
Descuidar la seguridad de los datos: al migrar datos, asegúrate de utilizar una capa de memoria que respete tus requisitos de privacidad y cumplimiento, especialmente si trabajas con documentos legales o financieros.
Para quién es mejor este enfoque de migración
Adoptar una capa de memoria reutilizable está altamente recomendado para cualquiera que tenga flujos de trabajo de IA con muchos documentos o mucha continuidad. Este enfoque es especialmente beneficioso para:
Investigadores y analistas: que necesitan mantener acceso a docenas de artículos académicos o informes financieros a través de diferentes modelos de razonamiento.
Fundadores y equipos de producto: que iteran sobre especificaciones de producto, investigación de mercado y bases de código usando diferentes agentes especializados de IA.
Profesionales de finanzas, legal, biotecnología y consultoría: donde perder el contexto matizado del proyecto o las conclusiones analíticas previas puede descarrilar todo un flujo de trabajo.
Conclusión
La era de depender de un solo agente de IA para todo está llegando a su fin. A medida que las tareas se vuelven más especializadas, mover tu flujo de trabajo de IA a un nuevo agente se convertirá en una necesidad rutinaria. Sin embargo, cambiar de herramienta no debería significar abandonar tu trabajo. Al pasar de ventanas de chat aisladas a una infraestructura de memoria persistente, puedes cambiar de agentes de IA sin empezar de cero.
Si tu flujo de trabajo depende de archivos, notas, contexto del proyecto y memoria reutilizable, una capa de memoria portátil como MemoryLake puede hacer que el cambio sea mucho más fluido. Para equipos y personas que cambian de herramientas con regularidad, MemoryLake es una opción sólida para preservar la continuidad del flujo de trabajo en lugar de reconstruirlo desde cero.
Preguntas frecuentes
¿Cómo se mueve un flujo de trabajo de IA a un nuevo agente sin perder contexto?
Para mover un flujo de trabajo de IA sin perder contexto, debes dejar de almacenar tus documentos y el historial del proyecto dentro del propio agente de IA. En su lugar, usa una capa de memoria persistente (como MemoryLake) para alojar tus archivos, notas y contexto, y conecta tu nuevo agente a esa capa mediante API o MCP.
¿Qué se pierde cuando cambias de agentes de IA?
Cuando cambias de agentes de IA, normalmente pierdes archivos subidos, instrucciones específicas del proyecto, contexto histórico, conclusiones previas y la continuidad del flujo de trabajo que construiste a lo largo de docenas de interacciones.
¿El historial de chat es suficiente al pasar a una nueva herramienta de IA?
No. Exportar el historial de chat solo proporciona un registro de texto estático. No actúa como una memoria con capacidad de búsqueda y consciente de los documentos. Pegar registros de chat en un nuevo agente a menudo sobrepasa su ventana de contexto y degrada la calidad de sus resultados.
¿Cómo mantienes notas y trabajo previo entre agentes?
Puedes mantener notas y trabajo previo entre agentes usando una capa de memoria de IA portátil. Al subir tu trabajo a una plataforma centralizada y agnóstica al agente, cualquier nueva herramienta de IA que adoptes puede consultar esa memoria persistente para recuperar ideas pasadas.
¿Qué es MemoryLake y cómo ayuda?
MemoryLake está diseñado para ser una capa de memoria persistente para sistemas de IA. Ayuda actuando como un "segundo cerebro" o pasaporte de memoria, permitiendo a los usuarios almacenar documentos, contexto y notas de forma independiente de cualquier herramienta de IA específica, lo que facilita migrar flujos de trabajo a nuevos agentes.
¿Cómo evitas reconstruir tu flujo de trabajo desde cero?
Evita reconstruir desde cero centralizando tus procedimientos operativos estándar, instrucciones recurrentes y documentos principales en una infraestructura de memoria externa. Cuando adoptes un nuevo agente, simplemente conéctalo a esta infraestructura mediante plugins o MCP.