Cómo migrar de OpenClaw a Hermes Agent sin perder tus flujos de trabajo ni la memoria

Introducción
Pasar de OpenClaw a un nuevo entorno como Hermes Agent suele ser un paso emocionante para los equipos que buscan mejorar sus capacidades de IA. Sin embargo, una vez que tomas la decisión de cambiar, rápidamente te encuentras con un obstáculo frustrante: tu nuevo agente está completamente vacío.
Cambiar de herramientas de IA sin perder el contexto es uno de los mayores desafíos en los flujos de trabajo modernos de IA. La inteligencia de un agente de IA no proviene solo de su modelo fundacional subyacente; proviene de los documentos que has subido, de las preferencias que ha aprendido y del contexto específico que has ido construyendo a lo largo de cientos de interacciones.
Si quieres migrar de OpenClaw a Hermes Agent sin tener que empezar tus proyectos desde cero, necesitas una estrategia para la continuidad del flujo de trabajo de IA. Esta guía explicará por qué fallan los métodos estándar de migración, qué se pierde realmente durante una transición y cómo usar una capa de memoria portátil para mantener intacto tu trabajo.
Respuesta rápida: cómo migrar de OpenClaw a Hermes Agent
Para migrar de OpenClaw a Hermes Agent sin perder tus flujos de trabajo ni tu memoria, deberías evitar depender del copiar y pegar manual o de las exportaciones básicas del historial de chat. En su lugar, el enfoque más eficaz es desacoplar tus datos del agente específico mediante una capa de memoria de IA portátil.
Este es el mejor proceso para garantizar la continuidad del flujo de trabajo:
Extrae tu contexto principal: Reúne los documentos que usas con frecuencia, la investigación en curso y las notas estructuradas de OpenClaw.
Centralízalo en una capa de memoria persistente: Sube estos archivos (PDF, Word, Excel) a una infraestructura de memoria agnóstica a la herramienta como MemoryLake.
Enriquécelo con conjuntos de datos relevantes: Añade datos abiertos específicos del sector (por ejemplo, artículos académicos o informes financieros) para cubrir cualquier vacío de contexto.
Conecta la memoria a Hermes Agent: Usa claves API, complementos o el Protocolo de Contexto del Modelo (MCP) para enrutar esta memoria persistente directamente a Hermes Agent, dándole acceso instantáneo a tus flujos de trabajo anteriores.
Por qué migrar agentes de IA es más difícil de lo que parece
Cambiar de herramientas suele implicar mover datos del punto A al punto B. Pero los agentes de IA no tratan los datos como una base de datos tradicional. En la mayoría de las plataformas de IA, la memoria y el contexto están fuertemente aislados dentro de sesiones de chat específicas o espacios de trabajo propietarios.
Cuando decides pasar a Hermes Agent, no solo estás migrando archivos; estás tratando de migrar comprensión. Si tu flujo de trabajo depende de que la IA conozca los antecedentes de un caso legal, las decisiones arquitectónicas de tu base de código o las reglas de formato de tus informes semanales, cambiar a una nueva herramienta normalmente significa reiniciar esa comprensión a cero. “Cambiar de herramienta” y “preservar la continuidad” son dos desafíos técnicos completamente distintos.
Qué se pierde en un movimiento típico de OpenClaw → Hermes Agent
Cuando los usuarios intentan una transición directa, a menudo subestiman la enorme cantidad de trabajo invisible que dejan atrás. Sin una estrategia de migración adecuada, probablemente perderás:
Documentos y archivos subidos: Todos los PDF, CSV y documentos internos que alimentaste en OpenClaw para fundamentar sus respuestas.
Contexto previo y matices: Las instrucciones sutiles y el conocimiento de fondo que el agente acumuló sobre los objetivos de tu proyecto.
Memoria del flujo de trabajo: Los pasos secuenciales que el agente aprendió a seguir al procesar tus tipos específicos de solicitudes.
Conocimiento estructurado: Conclusiones, resúmenes y notas sintetizadas generadas en sesiones anteriores.
Historial de tareas: El hilo continuo de lo que ya se intentó, lo que falló y cuáles son los siguientes pasos.
Por qué fallan los métodos comunes de migración
La mayoría de los usuarios intenta resolver a la fuerza una migración de IA. Aquí se explica por qué los métodos manuales más comunes suelen fallar a la hora de preservar tus flujos de trabajo:
1. Copiar y pegar manualmente y saturar con prompts
Intentar copiar tus mejores prompts y conversaciones pasadas de OpenClaw y pegarlos en Hermes Agent no es un flujo de trabajo escalable. Saturar con prompts —amontonar texto de contexto interminable en cada nuevo prompt— agota tus límites de tokens, aumenta los costes y a menudo confunde al nuevo agente.
2. Exportar notas dispersas
Exportar registros de chat como archivos de texto o JSON puede hacerte sentir que eres dueño de tus datos, pero no ayuda a Hermes Agent. Un volcado de texto en bruto de una conversación pasada es increíblemente difícil de analizar y usar eficazmente en tiempo real para un nuevo agente.
3. Volver a subir archivos uno por uno
Si tenías docenas de documentos de referencia en OpenClaw, volver a subirlos manualmente a Hermes Agent es tedioso. Peor aún, si en el futuro cambias de agente otra vez, tendrás que repetir exactamente esta misma tarea.
La solución: pasar a una capa de memoria de IA portátil
Para dejar de empezar de cero con las herramientas de IA, necesitas cambiar de perspectiva. En lugar de intentar migrar la memoria al nuevo agente, deberías mover tu memoria completamente fuera del agente.
Aquí es donde entra el concepto de una capa de memoria de IA portátil. Una herramienta como MemoryLake está diseñada para actuar como una infraestructura de memoria persistente para sistemas de IA. No es solo un registrador del historial de chat ni un simple cargador de archivos; la documentación pública la presenta como un “segundo cerebro” o un “pasaporte de memoria” que abarca herramientas, modelos y agentes.
Al usar una capa de memoria persistente, tus documentos, contexto y trabajo previo permanecen en un centro unificado y gobernado. Tanto si usas OpenClaw, Hermes Agent, Claude o ChatGPT, el agente simplemente se conecta a esta capa de memoria para recuperar exactamente lo que necesita.
Paso a paso: usar MemoryLake para preservar flujos de trabajo y memoria
Si estás planeando migrar a Hermes Agent, aquí tienes una guía práctica, paso a paso, sobre cómo usar MemoryLake para garantizar la continuidad del flujo de trabajo y evitar la pérdida de datos.
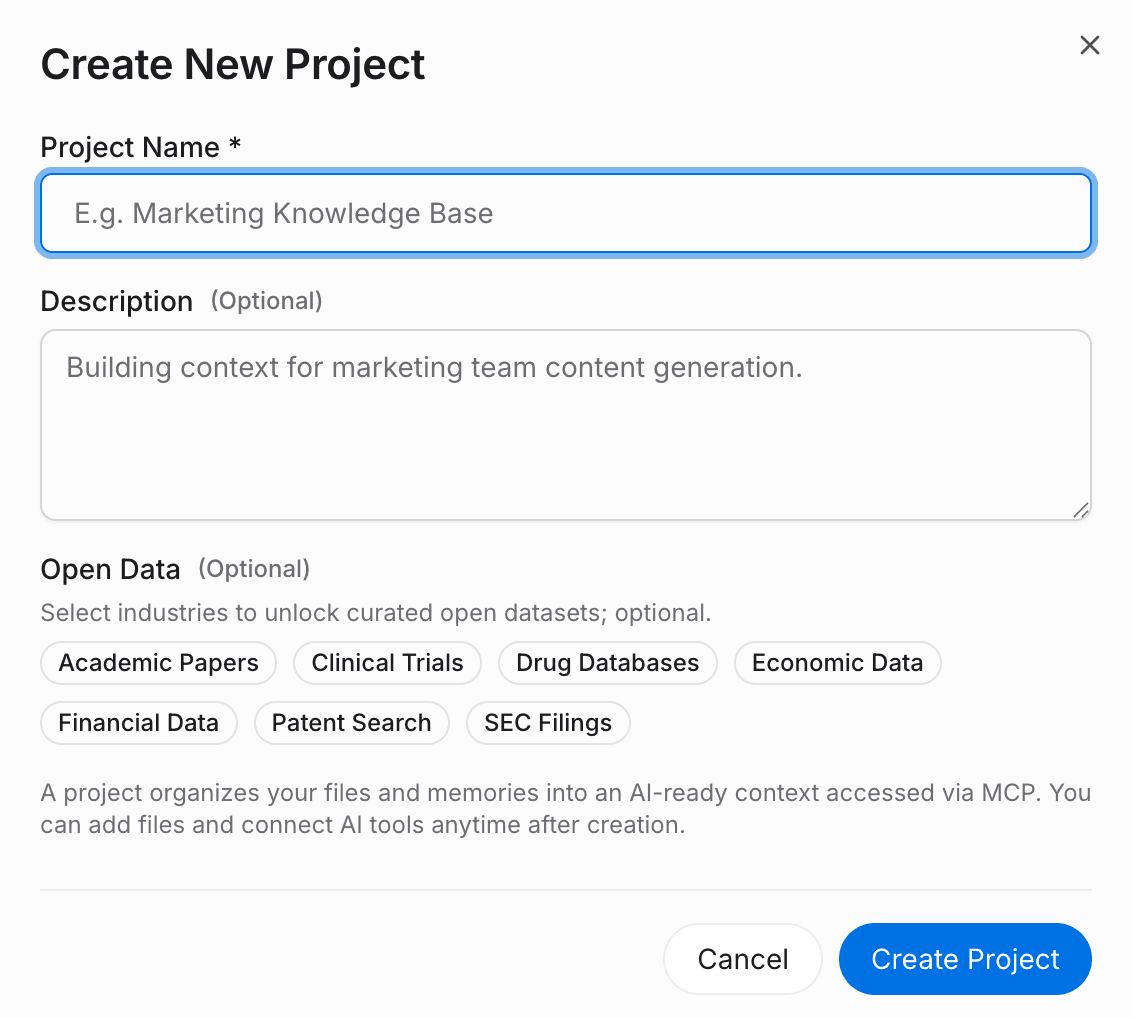
Paso 1: crea un proyecto y sube tus datos anteriores
El primer paso es rescatar tu contexto de los silos de OpenClaw. En MemoryLake, creas un proyecto dedicado que servirá como hogar persistente para este flujo de trabajo específico.
Acción: Haz clic en el botón de adjuntar en MemoryLake para subir los documentos fuente que usabas anteriormente en OpenClaw.
Detalles: Admite formatos como PDF, Word, Excel y Markdown. MemoryLake analiza y estructura automáticamente este contenido para su recuperación por IA.
Fuentes externas: Si tu flujo de trabajo en OpenClaw dependía de datos en vivo, puedes usar la sección de archivos para conectar directamente fuentes de datos externas.
Por qué importa: En lugar de subir archivos a Hermes Agent, donde podrían quedar atrapados otra vez, los estás subiendo a una capa reutilizable.
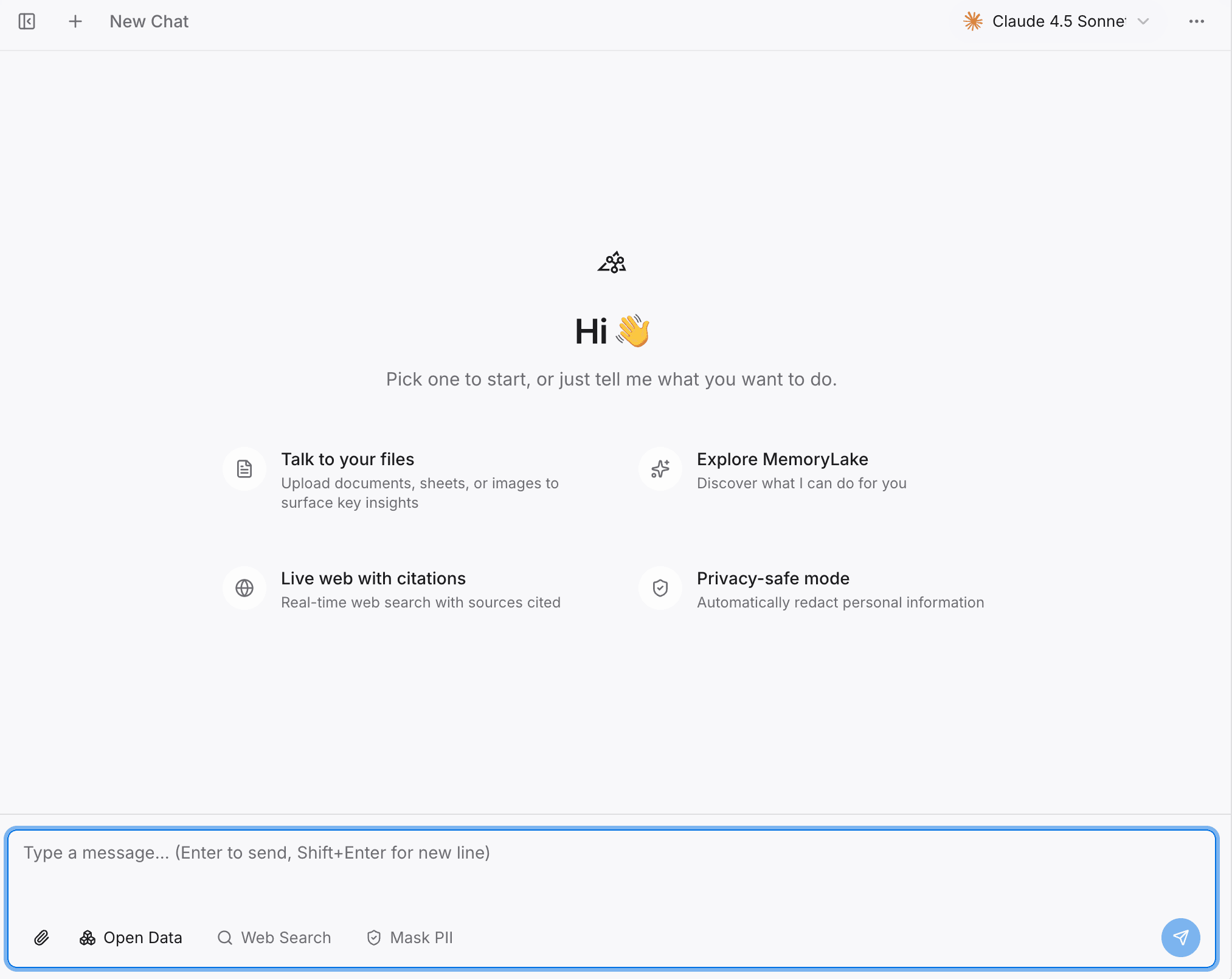
Paso 2: prueba el contexto en el Playground
Antes de comprometer por completo tu flujo de trabajo con Hermes Agent, quieres verificar que tu memoria esté intacta y pueda recuperarse con precisión.
Acción: Abre el Playground de MemoryLake y empieza a consultar tu proyecto.
Detalles: Haz las mismas preguntas complejas que solías hacerle a OpenClaw.
Por qué importa: Esto garantiza que el contexto de tus documentos y el conocimiento histórico se hayan analizado correctamente y estén listos para ser entregados al siguiente agente.
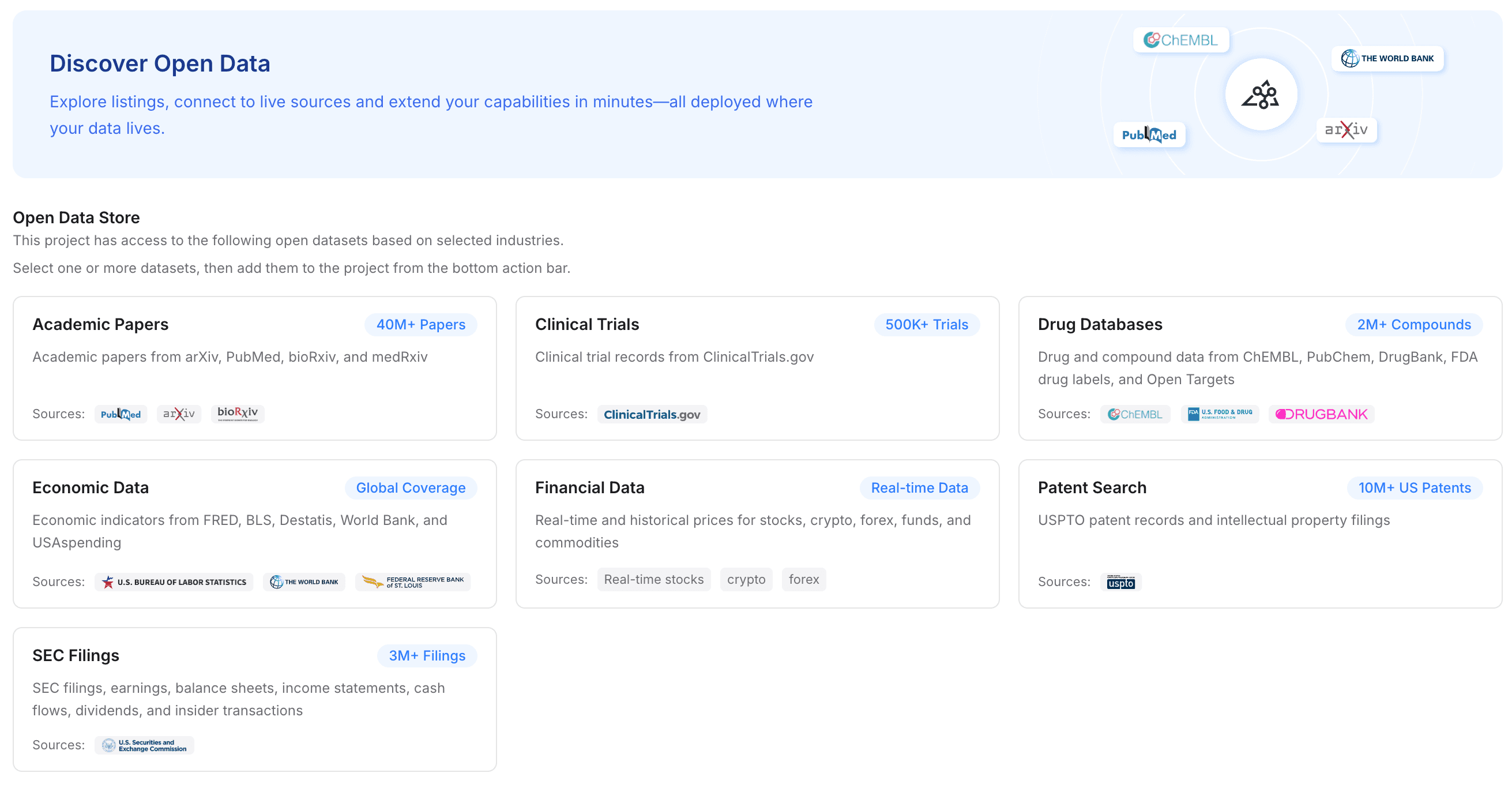
Paso 3: enriquece tu proyecto con datos abiertos
Las migraciones son un momento excelente para mejorar las capacidades de tu agente. MemoryLake te permite complementar tus cargas privadas con un conocimiento más amplio del sector.
Acción: Ve a las opciones de datos abiertos y añade conjuntos de datos relevantes del sector a tu proyecto.
Detalles: Según tu campo, puedes conceder a la capa de memoria acceso a artículos académicos, ensayos clínicos, bases de datos de fármacos, datos económicos, datos financieros, búsquedas de patentes o presentaciones ante la SEC.
Por qué importa: Esto mejora al instante la inteligencia base de Hermes Agent. En lugar de depender solo de tus antiguos archivos de OpenClaw, Hermes Agent tendrá ahora una memoria consciente de los documentos, reforzada por datos públicos autorizados.
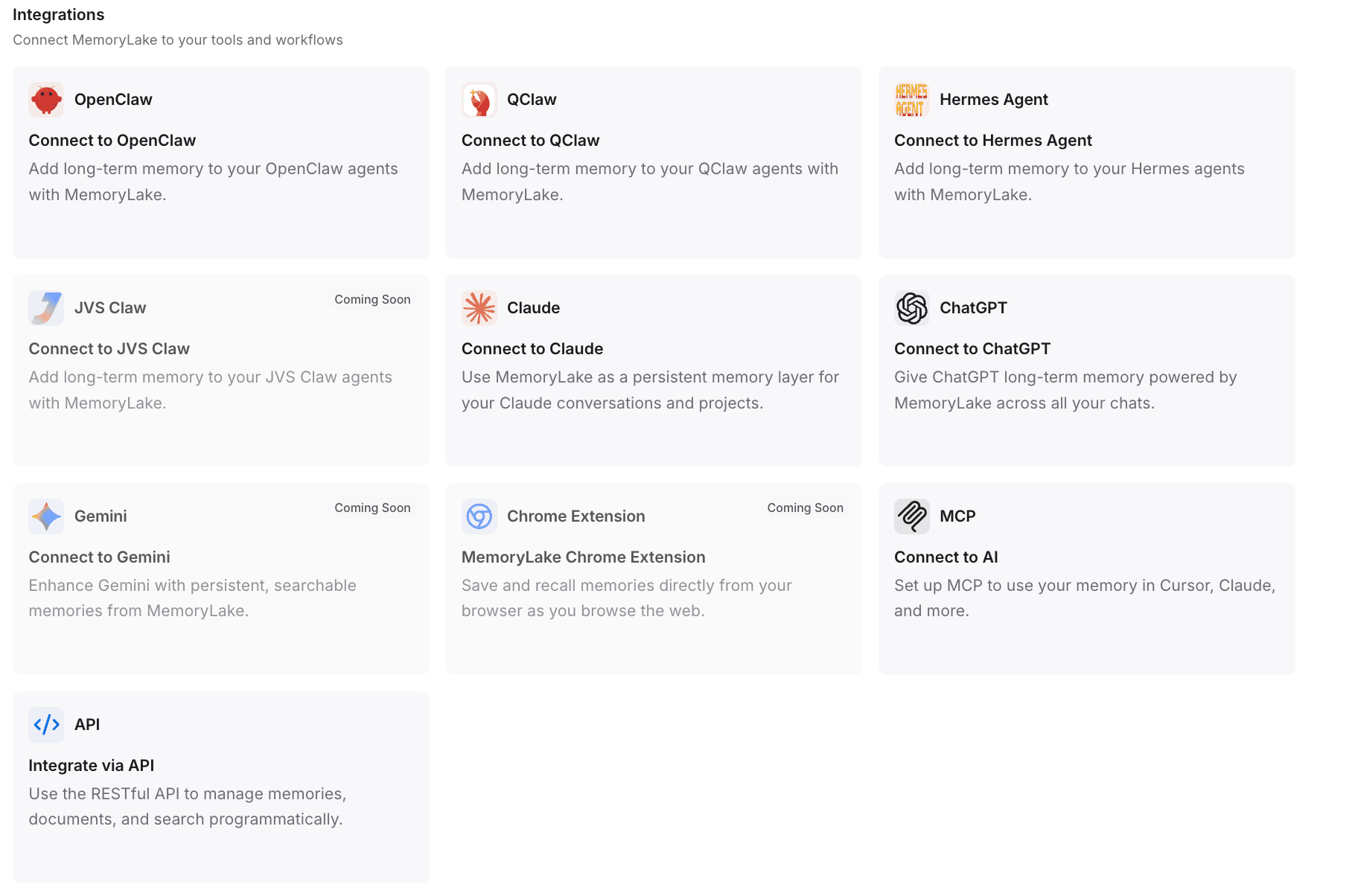
Paso 4: conecta MemoryLake con tus herramientas y flujos de trabajo
Este es el paso crítico que completa la migración. Ahora conectarás esta memoria persistente a Hermes Agent (y, si lo deseas, retirarás correctamente tu configuración de OpenClaw).
Acción: Genera una clave API dentro de MemoryLake.
Detalles para una integración sin fricciones: MemoryLake admite instalaciones con 1 clic y configuraciones automatizadas. Por ejemplo, la documentación pública destaca que puedes copiar la guía de configuración y pegarla en OpenClaw; el sistema instalará automáticamente el complemento, completará la configuración y reiniciará la puerta de enlace.
Conexión con Hermes Agent: Puedes usar una sola línea de comando para instalar el complemento, o integrarlo directamente en Hermes Agent mediante el Protocolo de Contexto del Modelo (MCP) o integraciones por API. MemoryLake está diseñado para integrarse sin problemas con OpenClaw, Hermes Agent, ChatGPT y Claude.
Por qué importa: Tu nuevo Hermes Agent se hidrata al instante con todo tu conocimiento previo. El flujo de trabajo continúa exactamente donde lo dejaste.
Errores comunes de migración que debes evitar
Tratar la memoria como una idea secundaria: Esperar hasta haberte mudado por completo a Hermes Agent para darte cuenta de que te falta contexto crucial. Extrae y centraliza siempre tus datos antes de hacer el cambio total.
Confundir los registros de chat con la memoria: Exportar un PDF de 50 páginas con tu historial de chat de OpenClaw y dárselo a Hermes Agent provocará un exceso en la ventana de contexto. Necesitas un sistema de memoria consciente de documentos, no una transcripción en bruto.
Depender de archivos locales: Mantener tus PDF de referencia en una carpeta local del escritorio significa que tendrás que arrastrarlos y soltarlos constantemente en la interfaz de chat de Hermes Agent. Una capa persistente basada en API es mucho más eficiente.
Mejores casos de uso para este enfoque de migración
El uso de una capa de memoria de IA persistente para unir herramientas es altamente recomendable para:
Flujos de trabajo con muchos documentos: Flujos de trabajo que dependen en gran medida de PDF densos, contratos legales o informes financieros.
Equipos de investigación: Equipos que pasan semanas construyendo revisiones bibliográficas y no pueden permitirse perder ese contexto al probar un nuevo modelo fundacional.
Usuarios de múltiples agentes: Usuarios que quieren usar Hermes Agent para programar, OpenClaw para redactar borradores iniciales y Claude para editar, todo compartiendo exactamente el mismo pasaporte de memoria.
Fundadores y ejecutivos: Líderes que cambian de herramientas de IA con frecuencia para buscar el mejor rendimiento, pero necesitan que su contexto operativo permanezca estable.
Conclusión
Migrar de OpenClaw a Hermes Agent no tiene por qué significar perder semanas de contexto, volver a empezar tu investigación o volver a subir interminables carpetas de PDF. La fricción que sientes durante una migración no es un problema del nuevo agente; es un problema de cómo la memoria de IA está actualmente aislada en silos.
Al cambiar a un modelo en el que tus datos viven independientemente de la herramienta, ganas la libertad de actualizar tus asistentes de IA cuando quieras sin pagar el precio de perder productividad.
Si tu flujo de trabajo depende en gran medida de documentos, contexto de proyecto e inteligencia reutilizable, MemoryLake merece ser evaluado. Te ofrece una forma de cambiar de herramientas sin retroceder. Para los equipos que cambian de modelo o de agente con frecuencia, utilizar una capa de memoria portátil como MemoryLake es una opción sólida para preservar la continuidad del flujo de trabajo, permitiendo que tus nuevos sistemas de IA continúen exactamente donde lo dejaron los anteriores.
Preguntas frecuentes
¿Cómo se migra de un agente de IA a otro sin perder el contexto?
Para migrar sin perder el contexto, evita depender estrictamente de copiar manualmente los prompts. En su lugar, extrae tus documentos e instrucciones fundamentales, súbelos a una capa de memoria de IA portátil y conecta esa capa de memoria a tu nuevo agente mediante una API o una integración MCP.
¿Qué suele perderse al cambiar de herramientas de IA?
Al cambiar de herramientas de IA, los usuarios suelen perder documentos de referencia subidos, el historial de tareas en curso, el conocimiento estructurado que la IA ha aprendido sobre sus preferencias y los hábitos de flujo de trabajo específicos desarrollados durante múltiples sesiones.
¿Es suficiente el historial de chat al cambiar entre asistentes de IA?
No. El historial de chat en bruto es difícil de analizar eficazmente para un nuevo asistente de IA. Pegar registros de chat largos consume rápidamente los límites de tokens y a menudo degrada el rendimiento de la IA. Necesitas memoria estructurada y recuperable, no simples registros de texto.
¿Cómo mantienes documentos y memoria del flujo de trabajo entre herramientas?
Puedes mantener documentos entre herramientas usando una infraestructura de memoria agnóstica a la herramienta. Al almacenar tus PDF, archivos de Excel y contexto en una capa centralizada (en lugar de dentro del almacenamiento propietario de un agente específico), cualquier nueva herramienta que adoptes puede consultar la misma fuente de datos.
¿Qué es MemoryLake y cómo ayuda con la migración?
MemoryLake es una capa de memoria persistente para sistemas de IA. Ayuda con la migración al actuar como un “segundo cerebro” reutilizable. Según su flujo de configuración, puedes almacenar tus documentos y contexto en MemoryLake y luego conectarlo directamente a plataformas como Hermes Agent u OpenClaw, garantizando una continuidad fluida entre herramientas.
¿Cómo evitas reconstruir flujos de trabajo de IA desde cero?
Para evitar reconstruir flujos de trabajo, desacopla tus datos de tu entorno de ejecución de IA. Establece una base de conocimiento persistente que contenga tus prompts, reglas y archivos de referencia, y enruta esos datos hacia el agente de IA que estés usando en ese momento.