Cómo sincronizar la memoria y el contexto entre Claude, ChatGPT y Gemini en mi flujo de trabajo (Guía 2026)

Introducción
Alternar entre los mejores modelos de IA es el estado por defecto del trabajador del conocimiento moderno. Podrías usar Claude para redactar un documento técnico complejo, cambiar a ChatGPT para iterar sobre ideas y abrir Gemini para contrastar la investigación con la web en vivo. Sin embargo, este enfoque multimodelo crea un cuello de botella inmediato: cada vez que cambias de herramienta, el contexto de tu proyecto se rompe.
Terminas pegando repetidamente la misma información de fondo, volviendo a subir los mismos documentos fuente y reexplicando tus restricciones. La fricción de la fragmentación del contexto agota tu productividad, desperdicia tokens y conduce a resultados inconsistentes entre distintos asistentes.
Para sincronizar la memoria y el contexto entre Claude, ChatGPT y Gemini, necesitas una capa de memoria persistente centralizada —como MemoryLake— que esté fuera de las plataformas de IA individuales. Al almacenar los archivos de tu proyecto, el conocimiento de fondo y las decisiones pasadas en un sistema portátil accesible mediante API o MCP, puedes alimentar sin problemas el mismo contexto a cualquier modelo de IA sin copiar, pegar o volver a subir archivos de forma repetitiva.
Esta guía desglosa exactamente cómo dejar de repetirte, cómo construir una memoria de IA unificada entre modelos y cuál es el flujo de trabajo paso a paso exacto para mantener Claude, ChatGPT y Gemini perfectamente sincronizados.
El problema real: por qué el contexto se rompe entre Claude, ChatGPT y Gemini
Los distintos modelos de IA sobresalen en diferentes tareas cognitivas. Es natural asignar cargas de trabajo específicas a la herramienta mejor adaptada para el trabajo. Pero las plataformas de IA individuales son jardines cerrados.
Cuando mueves un proyecto de ChatGPT a Claude, el nuevo modelo no tiene ninguna conciencia de las decisiones que acabas de tomar. Cuando pasas de Claude a Gemini, los documentos PDF y archivos de datos subyacentes no viajan contigo. Las "instrucciones personalizadas" o los "espacios de proyecto" integrados dentro de una sola aplicación solo resuelven el problema si nunca sales de ese ecosistema específico.
Esto conduce a varios fallos sistémicos en el flujo de trabajo:
Desperdicio de tokens: alimentas constantemente los mismos documentos enormes en la ventana de contexto de distintas herramientas.
Degradación de la información: como volver a escribir el contexto es tedioso, proporcionas un prompt más corto y más descuidado a la segunda herramienta de IA, lo que da como resultado salidas de menor calidad.
Caos en el control de versiones: pierdes el seguimiento de qué IA tiene la comprensión más actualizada del estado de tu proyecto.
Las ventanas de contexto son memoria de trabajo temporal. El historial del chat es un registro aislado e imposible de buscar. Ninguno funciona como un pasaporte de memoria portátil y persistente para tu flujo de trabajo diario.
Mi flujo de trabajo de 2026 para sincronizar memoria entre herramientas de IA
Un flujo de trabajo sostenible entre IAs requiere separar tus datos de los modelos de IA. En lugar de tratar a Claude o ChatGPT como la unidad de almacenamiento de tu proyecto, trátalos únicamente como motores de cómputo. Tus archivos, instrucciones y contexto deberían vivir en una capa de infraestructura de memoria unificada.
Aquí está la arquitectura de alto nivel de un flujo de trabajo sincronizado:
Archivos de proyecto centralizados: todos los documentos fuente, trabajos de investigación y hojas de datos viven en una sola capa de memoria externa, no se cargan individualmente en diferentes interfaces de chat.
Memoria compartida a largo plazo: las restricciones centrales del proyecto, la información de fondo y las preferencias del usuario se almacenan de forma persistente y se recuperan solo cuando es necesario.
Instrucciones específicas por tarea: el prompt dentro de Claude, ChatGPT o Gemini contiene solo las instrucciones inmediatas de la tarea, mientras que el trabajo pesado del contexto se maneja sin fricción mediante integraciones.
Usar una capa de memoria compartida es infinitamente más eficiente que duplicar configuraciones en cada aplicación. Te permite actualizar, cambiar o combinar asistentes de IA sobre la marcha sin perder ni un solo dato.
Qué es lo que realmente necesita sincronizarse
Para mantener la continuidad entre herramientas de IA, debes identificar qué tipo de información constituye realmente "contexto". Una capa de memoria adecuada debería capturar y sincronizar los siguientes elementos:
Antecedentes del proyecto
Los objetivos generales, la audiencia objetivo, los plazos y los objetivos principales de lo que estás construyendo. Esto evita que la IA genere salidas genéricas que no se alineen con tu misión principal.
Archivos de trabajo y documentos fuente
Datos en bruto, PDFs, hojas de cálculo y materiales de referencia. Estos son los anclajes fácticos de tus flujos de trabajo con IA. Sincronizarlos asegura que cada modelo analice exactamente la misma fuente de verdad.
Instrucciones y preferencias reutilizables
Reglas de formato, pautas de voz de marca, estándares de codificación y marcos específicos que esperas que la IA siga.
Decisiones pasadas e ისტორial de conversaciones
Las conclusiones que alcanzaste en conversaciones previas con IA. Si ChatGPT te ayudó a finalizar un esquema estructural ayer, Claude necesita conocer ese esquema hoy antes de redactar el contenido.
Conocimiento del dominio / contexto de investigación
Terminología específica de la industria, conjuntos de datos especializados e investigación en profundidad que los modelos base de IA podrían no poseer de forma innata.
Contexto específico de la tarea vs memoria a largo plazo
Debes separar lo que la IA necesita saber para siempre (el tono de voz de tu empresa) de lo que necesita saber ahora (resume este correo). Una capa de memoria estructurada maneja lo primero, manteniendo tus prompts diarios ligeros y centrados en lo segundo.
Paso a paso: cómo usar MemoryLake para sincronizar contexto en todo tu flujo de trabajo
Para ejecutar este flujo de trabajo entre IAs, necesitas un sistema diseñado específicamente como un pasaporte de memoria portátil para asistentes de IA. MemoryLake funciona exactamente así: una capa de memoria persistente, propiedad del usuario, que conecta archivos, conocimiento e ისტორial de conversaciones entre distintas herramientas.
Aquí te explico cómo configurarlo como la infraestructura de memoria central para tu pila.
Paso 1 — Crea un proyecto y sube tus archivos y datos
Empieza creando un espacio de trabajo dedicado para tu iniciativa. Haz clic en el botón de adjuntos para subir tus documentos fuente directamente a MemoryLake. El sistema analizará, procesará y estructurará automáticamente el contenido para su recuperación inmediata.
Admite de forma nativa una amplia gama de formatos, incluidos PDF, Word, Excel y Markdown. Si tus datos están en otro lugar, también puedes navegar a la sección de archivos para conectar directamente fuentes de datos externas, asegurando que tu memoria de IA siempre tome la información de tus datos operativos más recientes sin necesidad de volver a subirlos manualmente.
Paso 2 — Busca o chatea con tu proyecto
Antes de conectar herramientas de IA externas, puedes verificar tu contexto en el Playground integrado. Al hacer preguntas directamente sobre tu proyecto, te aseguras de que el sistema haya indexado correctamente tu conocimiento.
Este paso destaca que MemoryLake no es solo almacenamiento estático en la nube: es una capa de memoria de proyecto buscable, conversacional y altamente reutilizable. Preprocesa tu contexto para que, cuando Claude o ChatGPT lo accedan, la información ya esté optimizada para la comprensión de la IA.
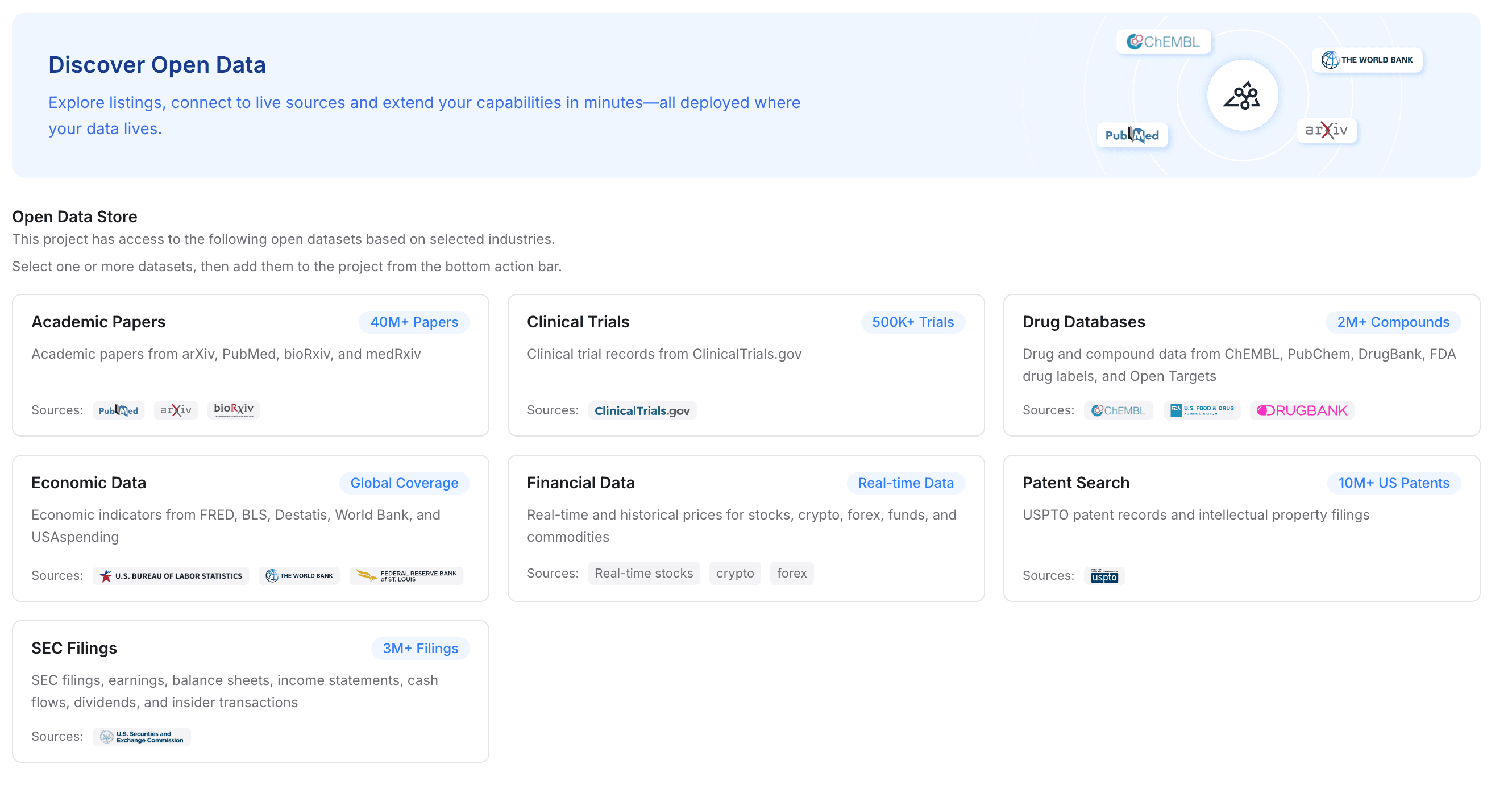
Paso 3 — Añade datos abiertos para fortalecer el proyecto
Si tu flujo de trabajo requiere experiencia profunda en un dominio, puedes ampliar tus archivos privados con datos abiertos. MemoryLake te permite añadir conjuntos de datos especializados de la industria a tu proyecto con un solo clic.
Puedes integrar al instante acceso a artículos académicos, ensayos clínicos, bases de datos de medicamentos, datos económicos, registros financieros, búsquedas de patentes y presentaciones ante la SEC. Para flujos de trabajo intensivos en investigación, esto proporciona una ventaja inigualable: estás alimentando a Claude, ChatGPT y Gemini con una capa de contexto profundamente enriquecida que combina tus archivos privados con conjuntos de datos globales autorizados.
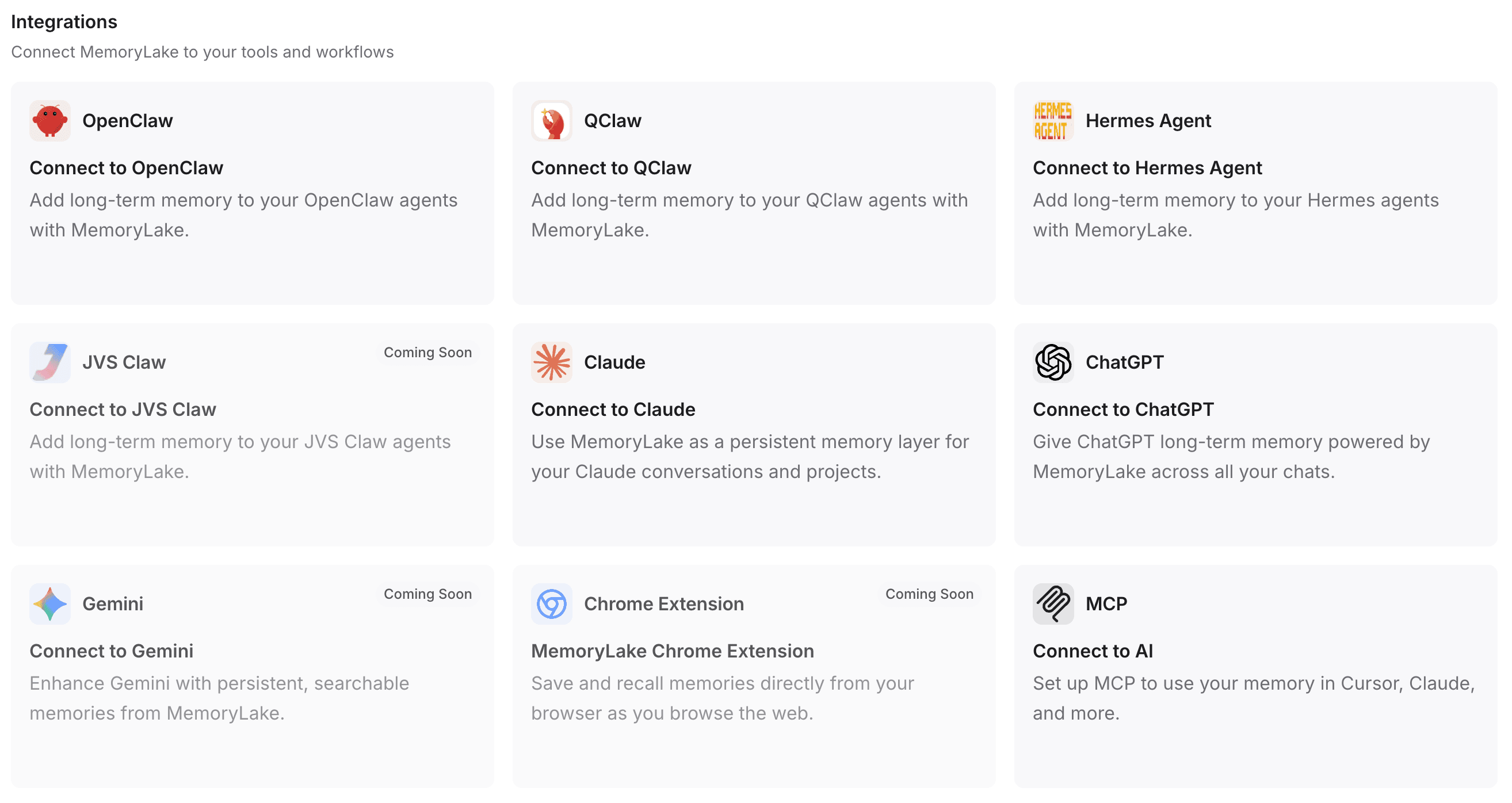
Paso 4 — Conecta MemoryLake a tus herramientas y flujo de trabajo
Este es el paso crítico que cierra la brecha entre herramientas fragmentadas y una memoria de IA unificada entre modelos. Al conectar esta infraestructura con tus asistentes diarios, eliminas la necesidad de pegar contexto repetidamente.
Primero, selecciona o crea tu propia API Key. MemoryLake admite una integración rápida:
Instalación con un clic: para entornos compatibles, un solo comando es todo lo necesario para instalar y configurar los complementos requeridos.
Configuración automatizada: si usas herramientas como OpenClaw, simplemente puedes copiar las pautas de integración proporcionadas y pegarlas en el cliente. Instalará automáticamente el complemento, completará la configuración y reiniciará la puerta de enlace por ti.
Amplia compatibilidad: puedes canalizar sin problemas esta capa de memoria hacia ChatGPT, Claude, OpenClaw, Hermes Agent y más.
Integraciones avanzadas: para desarrolladores y usuarios avanzados, conectarse programáticamente mediante MCP (Model Context Protocol) o endpoints nativos de API garantiza que tus scripts y agentes personalizados compartan exactamente el mismo pasaporte de memoria.
Cómo divido el trabajo entre Claude, ChatGPT y Gemini una vez que la memoria está sincronizada
Una vez que MemoryLake gestiona el contexto persistente, desaparece la fricción de la productividad multimodelo. Tus archivos y conocimientos de fondo están accesibles universalmente. Así es como puedes dividir con confianza las tareas entre el ecosistema:
Claude para redacción profunda y razonamiento: con la capa de memoria proporcionando el esquema estructural y los PDF fuente, Claude se utiliza mejor para generación de texto pesada, arquitecturas de programación complejas y escritura analítica matizada.
ChatGPT para iteración, formato e ideación: conecta ChatGPT al mismo espacio de memoria para generar rápidamente alternativas, dar formato a los datos analizados por Claude o ejecutar análisis de datos usando sus modelos de razonamiento avanzados.
Gemini para tareas multimodales y verificación cruzada del ecosistema: usa Gemini conectado a tu memoria persistente cuando necesites contrastar los datos de tu proyecto con documentos en vivo de Google Workspace, consultas web o entradas multimodales complejas.
El objetivo no es declarar un modelo como el ganador absoluto, sino diseñar un flujo de trabajo en el que los modelos sean trabajadores intercambiables que acceden al mismo cerebro unificado.
Errores comunes que aún rompen los flujos de trabajo multi-IA
Incluso con acceso a múltiples herramientas, muchos usuarios sabotean su propia productividad aferrándose a hábitos heredados. Evita estos errores comunes:
Atiborrar cada prompt: pegar manualmente 10.000 palabras de contexto en cada nueva ventana de chat desperdicia tiempo, agranda la ventana de contexto y diluye la atención del modelo.
Depender de una sola ventana de chat: tratar un único hilo infinito como tu "base de datos del proyecto" inevitablemente lleva a que la IA olvide instrucciones anteriores o alucine decisiones pasadas.
No distinguir entre memoria a largo plazo y contexto de tarea: obligar a una IA a leer tu guía de marca de 50 páginas solo para escribir un tuit de dos frases es ineficiente.
Dispersar archivos entre herramientas: subir un CSV a ChatGPT y un PDF relacionado a Claude garantiza que ambos modelos te darán consejos contradictorios.
Carecer de conocimiento estructurado del proyecto: arrojar datos en bruto a una IA sin organizarlos en un espacio de proyecto coherente da como resultado una recuperación deficiente.
Tratar el historial del chat como una capa de conocimiento reutilizable: lo que discutiste con una IA ayer es diálogo no estructurado, no una base de conocimiento fiable y portátil.
Capa de memoria vs historial del chat vs ventana de contexto
Para dominar una configuración de productividad de IA multimodelo, debes entender las distinciones técnicas entre cómo la IA maneja la información.
Ventana de contexto (la RAM): es la memoria activa y a corto plazo de un modelo de IA específico durante una sola interacción. Está limitada por un tope de tokens. Una vez que lo superas, la IA empieza a "olvidar" la información proporcionada al principio.
Historial del chat (el registro): el registro histórico de lo que escribiste y de lo que respondió la IA. Está bloqueado dentro de la aplicación específica (por ejemplo, la barra lateral de ChatGPT). Es esencialmente texto muerto: no lo pueden buscar otras herramientas y es inútil para Claude o Gemini.
Capa de memoria (el disco duro): una infraestructura persistente y estructurada (como MemoryLake) que almacena archivos, conocimiento y contexto independientemente de cualquier herramienta de IA específica. Es buscable, conversacional y completamente portátil a través de toda tu pila de IA.
Para quién es mejor este flujo de trabajo
Un flujo de trabajo de contexto persistente se recomienda encarecidamente para profesionales cuyo trabajo depende de la precisión, la coherencia y la investigación profunda:
Investigadores y académicos: que necesitan que varios modelos de IA analicen los mismos conjuntos enormes de artículos y datos sin perder el hilo narrativo.
Fundadores y operadores: que cambian entre modelado financiero en una IA, textos de marketing en otra y estrategia de producto en una tercera, todo ello requiriendo exactamente el mismo contexto empresarial.
Consultores y analistas: que gestionan proyectos distintos y altamente confidenciales para varios clientes y necesitan espacios de memoria estrictos y aislados que viajen con su conjunto de herramientas de IA.
Equipos de producto: que requieren contexto compartido entre documentación técnica, comentarios de usuarios y hojas de ruta, asegurando que ningún asistente de IA trabaje con especificaciones desactualizadas.
Usuarios intensivos de IA del día a día: cualquiera que sienta cansancio por el ciclo interminable de copiar y pegar los mismos prompts en diferentes interfaces de chat.
Reflexiones finales
El verdadero secreto de la productividad entre IAs es darse cuenta de que los modelos en sí mismos son commodities. Hoy, Claude puede ser el mejor para programar; mañana, una nueva actualización de ChatGPT puede superarlo; la semana que viene, Gemini podría lanzar un avance en razonamiento multimodal.
Si tus flujos de trabajo, archivos y contextos de proyecto están atrapados dentro de la interfaz de chat de solo una de estas herramientas, enfrentarás constantemente la fricción de la migración y la fragmentación. La verdadera eficiencia multimodelo no proviene de intentar que cada asistente individual "te recuerde". Proviene de establecer una capa de memoria altamente organizada, de acceso fácil y totalmente portátil que sirva como la única fuente de verdad para cada herramienta que uses.
Si tu flujo de trabajo está empezando a romperse por el cambio repetido de contexto, un sistema de memoria portátil como MemoryLake puede hacer que toda tu pila sea significativamente más usable. Al centralizar tus archivos, conectar datos abiertos y transmitir ese conocimiento sin fricción a Claude, ChatGPT y Gemini, por fin tomas posesión de tu contexto de IA.
Preguntas frecuentes
¿Cómo sincronizo el contexto entre Claude, ChatGPT y Gemini?
Para sincronizar el contexto entre distintas herramientas de IA, necesitas desacoplar tus datos de los modelos de IA. Usa una capa de infraestructura de memoria de terceros para almacenar los archivos de tu proyecto, las instrucciones y el conocimiento de fondo, y conéctala a Claude, ChatGPT y Gemini mediante integraciones de API o MCP.
¿Pueden Claude, ChatGPT y Gemini compartir memoria?
De forma nativa, no. Viven en ecosistemas aislados. Sin embargo, pueden compartir memoria si usas una capa externa y portátil de memoria para IA que actúe como una base de conocimiento centralizada accesible por las tres herramientas simultáneamente.
¿Cuál es la mejor manera de reutilizar contexto entre herramientas de IA?
El mejor enfoque es dejar de pegar texto y, en su lugar, crear un espacio de trabajo de proyecto estructurado en un sistema de memoria dedicado. Sube tus archivos y define tus instrucciones una sola vez, luego consulta esa base de datos desde cualquier asistente de IA cada vez que empieces una nueva tarea.
¿Cómo evito repetir prompts en distintas aplicaciones de IA?
Almacena tus prompts de sistema principales, las pautas de marca y los marcos del proyecto en una capa de memoria persistente. Al usar diferentes aplicaciones, simplemente escribe un prompt mínimo que llame a la memoria externa conectada para proporcionar el contexto necesario.
¿Qué herramienta puede almacenar memoria entre varios asistentes de IA?
Las herramientas diseñadas específicamente como infraestructuras de memoria entre modelos, como MemoryLake, te permiten almacenar archivos, datos abiertos y contexto conversacional en un solo lugar, actuando como un pasaporte de memoria universal para tu pila de IA.
¿Es suficiente el historial del chat para flujos de trabajo multi-IA?
No. El historial del chat está bloqueado en la plataforma específica donde ocurrió la conversación. No puede exportarse dinámicamente a otro modelo, lo que lo hace inútil para mantener la continuidad al pasar de ChatGPT a Claude o Gemini.
¿Cómo subo archivos una sola vez y los uso en varias herramientas de IA?
Sube tus documentos fuente (PDFs, hojas de cálculo, Markdown) a una capa de memoria externa accesible por API. Una vez que esa sistema haya analizado y vectorizado los documentos, puedes usar integraciones para permitir que varias herramientas de IA consulten exactamente el mismo repositorio de archivos.
¿Cuál es la diferencia entre ventana de contexto, historial del chat y capa de memoria?
La ventana de contexto es la capacidad temporal de procesamiento de una IA para un solo prompt. El historial del chat es un registro de texto aislado de interacciones pasadas. Una capa de memoria es una base de datos persistente, portátil y propiedad del usuario que estructura tus archivos y contexto para acceso universal desde cualquier herramienta de IA.