Cómo almacenar PDF, Excel y memoria de investigación para que la IA no empiece de cero cada vez

Introducción
Si usas IA para revisión de documentos, análisis financiero o investigación académica, probablemente estés familiarizado con un ciclo frustrante: subir una y otra vez los mismos PDF y hojas de cálculo de Excel a tu asistente de IA. Cada vez que inicias una nueva sesión, la IA sufre de "amnesia." Olvida el artículo de investigación de 50 páginas que subiste ayer, pierde el contexto de tus modelos financieros y te obliga a explicar los objetivos de tu proyecto desde cero.
¿Por qué sucede esto? La mayoría de las herramientas de IA tratan las cargas de archivos como contexto temporal en lugar de conocimiento persistente. Aunque estos sistemas son excelentes procesando información en el momento, carecen de una infraestructura dedicada para la retención a largo plazo.
Para crear flujos de trabajo verdaderamente inteligentes, necesitas pasar de cargas de archivos puntuales a una capa de memoria persistente. Esta guía explicará por qué los chatbots de IA estándar siguen empezando de nuevo con tus archivos y cómo usar MemoryLake—una infraestructura persistente de memoria de IA—para construir un flujo de trabajo de memoria reutilizable, قابل de búsqueda y duradero para tus documentos, hojas de cálculo y materiales de investigación.
Respuesta rápida
¿Qué significa almacenar memoria de PDF, Excel e investigación para IA?
Significa dejar atrás las cargas temporales de archivos y establecer una infraestructura de memoria persistente donde tus documentos se almacenan continuamente, se vectorizan y se estructuran para su recuperación continua por IA a través de múltiples sesiones y herramientas.
¿Por qué la IA suele empezar de nuevo?
Los modelos de IA operan dentro de estrictos límites de ventana de contexto. Cuando una sesión termina o la ventana de contexto se llena, la memoria temporal de tus archivos subidos se borra. El historial de chat estándar conserva texto, pero no indexa de forma duradera archivos complejos para una recuperación futura robusta.
¿Cómo resuelve esto MemoryLake?
MemoryLake actúa como una capa persistente de infraestructura de memoria de IA. En lugar de volver a subir archivos, los subes una vez a un proyecto de MemoryLake. La plataforma procesa automáticamente PDFs, archivos de Excel y datos de investigación en una capa de memoria duradera que puede conectarse directamente a tus flujos de trabajo, agentes y chatbots mediante API o MCP, asegurando que tu IA nunca tenga que empezar de nuevo.
Por qué la IA sigue empezando de nuevo con PDFs, archivos de Excel e investigación
Para solucionar el problema de la amnesia de la IA, primero necesitamos entender las limitaciones de cómo la mayoría de las plataformas de IA manejan actualmente los archivos y la memoria.
Historial de chat ≠ memoria duradera
Muchos usuarios asumen que porque una IA recuerda lo que se dijo hace tres prompts, está "aprendiendo". Sin embargo, el historial de chat es solo un registro lineal de texto. Una vez que un hilo de conversación se vuelve demasiado largo, el contexto más antiguo se expulsa de la memoria activa de la IA. No es una base de datos estructurada y consultable para tus archivos complejos.
Las cargas de archivos puntuales ≠ sistema de memoria reutilizable
Cuando arrastras y sueltas un PDF o un archivo de Excel en una interfaz de chatbot estándar, el sistema lo lee temporalmente para esa conversación específica. En el momento en que abres una nueva ventana de chat, ese archivo desaparece. Esto obliga a los flujos de trabajo con mucha investigación a entrar en un bucle repetitivo de subir, esperar el procesamiento y volver a hacer preguntas.
RAG estándar ≠ capa de memoria de proyecto
Generación Aumentada por Recuperación (RAG) es excelente para encontrar fragmentos de texto relevantes en una gran base de datos. Sin embargo, una configuración básica de RAG suele estar aislada y ser muy técnica. Ofrece capacidad de búsqueda, pero no se traduce automáticamente en una capa holística de memoria de proyecto donde conviven de forma coherente archivos, contexto conversacional y datos estructurados a lo largo de múltiples sesiones de usuario y agentes de IA.
Cómo se ve un mejor flujo de trabajo de memoria
Si quieres evitar que tu IA empiece de nuevo, necesitas un flujo de trabajo que trate la memoria como infraestructura. Un mejor flujo de trabajo de memoria persistente debería incluir:
Memoria a nivel de proyecto: La información se agrupa por proyecto, lo que significa que todos los PDF, hojas de cálculo y el contexto de investigación relacionados viven en un único espacio dedicado.
Contexto reutilizable: Subes y procesas un archivo exactamente una vez. Después de eso, cualquier herramienta de IA conectada al proyecto puede acceder instantáneamente a sus conocimientos.
Compatibilidad con conocimiento basado en archivos: El sistema debe analizar con precisión formatos complejos, incluidos los datos tabulares de Excel y los diseños complejos de PDF académicos.
Independencia de herramienta: Tu memoria no debería estar bloqueada dentro de un solo chatbot específico. Debería conectarse vía API o MCP a las herramientas que uses (ChatGPT, Claude, agentes personalizados, etc.).
Paso a paso: cómo usar MemoryLake para almacenar memoria de PDF, Excel e investigación
MemoryLake se presenta como una infraestructura de memoria persistente diseñada específicamente para archivos, conversaciones y contexto de proyecto. Tiende un puente entre tus entradas de conocimiento en bruto y tus flujos de trabajo de IA en curso.
Aquí tienes una guía paso a paso para establecer un flujo de trabajo de memoria persistente usando MemoryLake.
Paso 1: crea un proyecto y sube tus archivos y datos
Para dejar de repetirte, primero necesitas establecer un contenedor de memoria dedicado.
Inicia sesión en MemoryLake y crea un nuevo proyecto (por ejemplo, "Investigación de mercado T3").
Haz clic en el botón de adjuntar para subir tus archivos locales. MemoryLake analiza, fragmenta y registra automáticamente el contenido.
La plataforma admite una amplia gama de tipos de documentos, incluidos PDF, Word, Excel y Markdown.
Si tus datos están en otro lugar, también puedes ir a la sección de archivos para conectar fuentes de datos externas, asegurando que todos tus materiales de investigación fluyan hacia una única memoria de proyecto unificada.
Paso 2: busca y chatea con tu proyecto en el Playground
Antes de integrar esta memoria en herramientas externas, deberías verificar que la IA entiende correctamente el contexto de tus archivos.
Abre el Playground integrado dentro de tu proyecto de MemoryLake.
Haz preguntas directas sobre los datos complejos que acabas de subir (por ejemplo, "Resume los riesgos financieros mencionados en el modelo de Excel subido").
Prueba la recuperación, las capacidades de chat y la comprensión contextual.
Al hacer esto, estás demostrando el concepto central: el conocimiento de tu proyecto ahora se reutiliza activamente, en lugar de obligarte a volver a subir la hoja de cálculo para una nueva consulta.
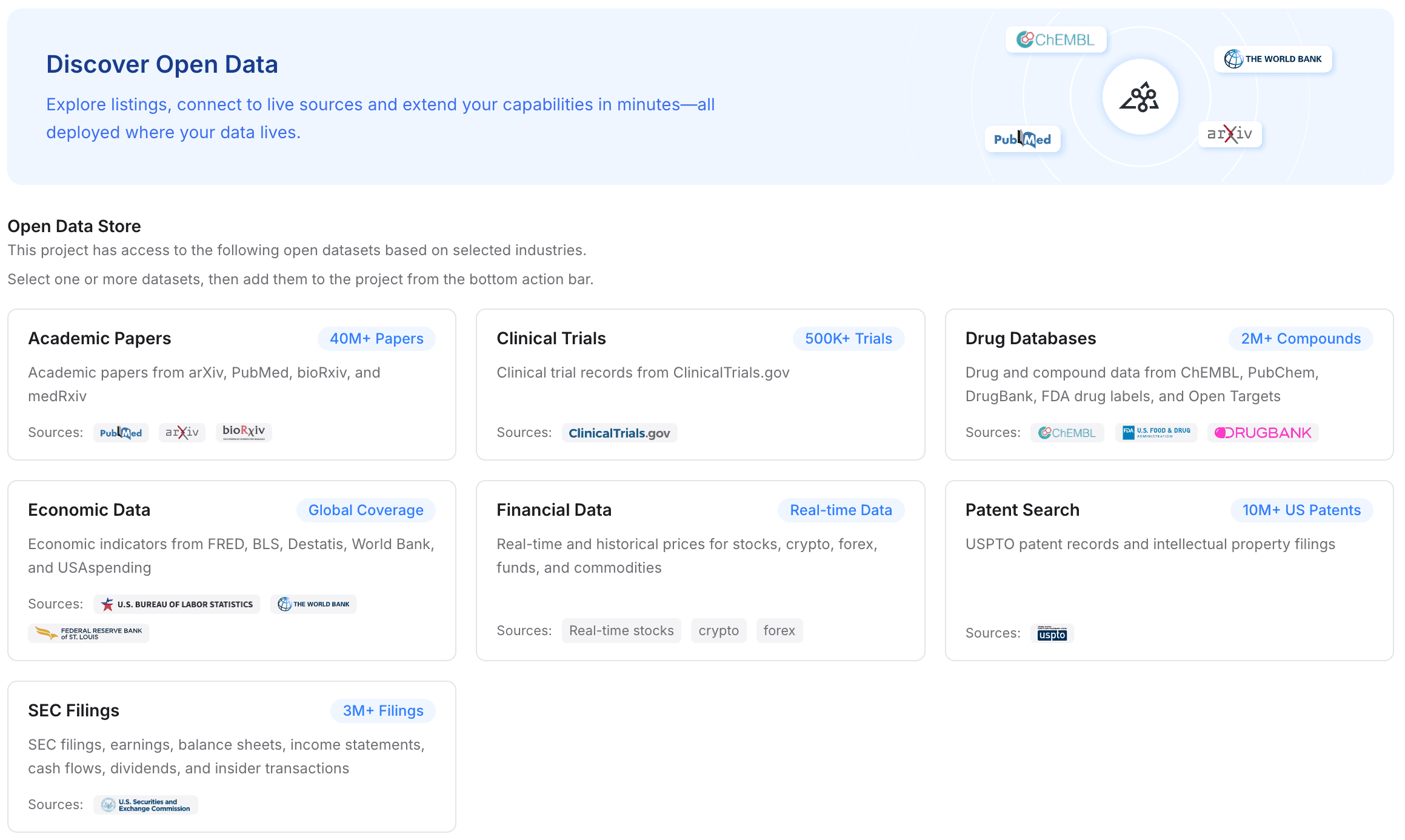
Paso 3: añade datos abiertos para enriquecer el conocimiento del dominio
Una poderosa capa de memoria no solo almacena tus archivos privados; los contextualiza con un conocimiento más amplio de la industria. MemoryLake te permite enriquecer la memoria de tu proyecto con datos abiertos en lugar de buscar y subir manualmente conjuntos de datos públicos.
Ve a la sección de conjuntos de datos en tu proyecto.
Con un clic, añade conjuntos de datos gratuitos y de alta calidad directamente a la memoria de tu proyecto.
Los tipos de datos disponibles incluyen artículos académicos, ensayos clínicos, bases de datos de medicamentos, datos económicos, datos financieros, búsquedas de patentes y presentaciones ante la SEC.
Al fusionar tus archivos privados PDF/Excel con estos conjuntos de datos abiertos, tu asistente de IA obtiene al instante un conocimiento profundo y especializado del dominio sin que nunca tengas que descargar y subir por tu cuenta una presentación pública ante la SEC.
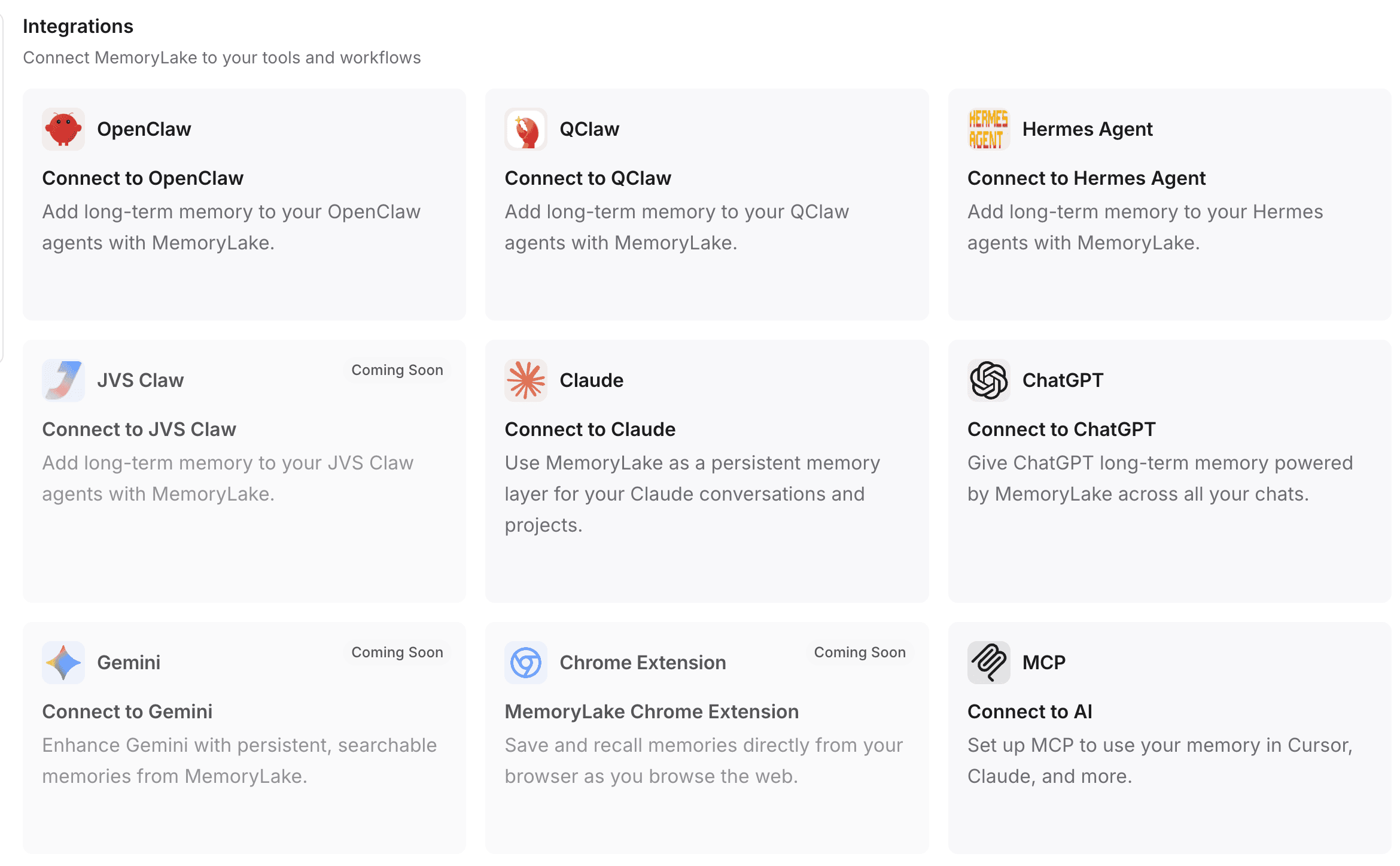
Paso 4: conecta MemoryLake con tus herramientas y flujos de trabajo
La memoria solo es útil si se conecta con las herramientas que realmente usas. MemoryLake está diseñado para integrarse directamente en tus flujos de trabajo diarios de IA.
Ve a la configuración de tu proyecto para elegir o crear tu propia clave API.
Instalación con un solo comando: para muchas integraciones, MemoryLake admite un flujo de instalación de un solo comando para poner tus complementos en funcionamiento al instante.
Configuración automática (por ejemplo, OpenClaw): si estás usando plataformas como OpenClaw, simplemente puedes copiar las instrucciones de configuración proporcionadas y pegarlas directamente en la interfaz de OpenClaw. OpenClaw instalará automáticamente el complemento necesario, configurará los ajustes de tu proyecto y reiniciará sin problemas la puerta de enlace por ti.
Amplia compatibilidad: puedes dirigir esta memoria persistente directamente a interfaces populares como ChatGPT, Claude, OpenClaw y Hermes Agent.
Acceso programático: para desarrolladores y creadores de agentes de IA, MemoryLake puede integrarse profundamente en sistemas backend mediante MCP (Protocolo de Contexto de Modelo) y API, asegurando que tus bots personalizados tengan una capa de memoria duradera y a largo plazo.
Mejores prácticas para construir memoria reutilizable de IA a partir de archivos
Organiza por proyecto, no solo por archivo: no arrojes todos tus documentos en un único enorme grupo de memoria global. Mantén los contextos separados (por ejemplo, "Análisis de la competencia" frente a "Políticas de RR. HH.") para garantizar una recuperación de alta calidad.
Trata la memoria como contexto reutilizable, no solo como almacenamiento en la nube: tu objetivo no es solo hacer copias de seguridad de los PDF; es hacer que se puedan conversar. Asegúrate de que los archivos que subes sean relevantes para las consultas que planeas hacer.
Combina cuidadosamente archivos privados con conjuntos de datos del dominio: usa datos abiertos (como presentaciones ante la SEC o artículos académicos) para complementar tus archivos internos de Excel, dando a la IA una visión holística del tema.
Tén en cuenta la integración del flujo de trabajo desde el principio: no construyas la memoria en un silo. Desde el primer día, planifica cómo se mostrará esta memoria, ya sea dentro de Claude, ChatGPT o de un agente interno personalizado.
Decide qué debe ser memoria a largo plazo frente a contexto temporal: si un documento solo se necesita para una corrección rápida de formato, una carga estándar en el chat está bien. Si es un artículo de investigación fundamental al que volverás durante meses, pertenece a MemoryLake.
Errores comunes que debes evitar
Confiar solo en el historial de chat: asumir que mantener abierto un hilo de ChatGPT durante seis meses es una forma viable de almacenar investigación. (Eventualmente se romperá, se ralentizará o lo olvidará).
Subir repetidamente los mismos archivos: desperdiciar tokens, límites de cómputo y tu propio tiempo arrastrando y soltando el mismo PDF cada lunes por la mañana.
Confundir RAG con memoria duradera: pensar que construir un script básico de RAG en Python resuelve el problema de experiencia de usuario de la memoria persistente y multiagente del proyecto.
Tratar hojas de cálculo y PDF como simples bloques de texto: los archivos de Excel tienen filas, columnas y relaciones. Los chatbots estándar a menudo desordenan estos datos al subirlos. Una capa de memoria dedicada analiza con precisión los datos tabulares y estructurados.
Nunca operacionalizar la memoria en herramientas reales: configurar una gran base de datos pero no conectarla vía API o MCP a las herramientas donde realmente trabaja tu equipo.
Quién debería usar este flujo de trabajo
Este flujo de trabajo de memoria persistente está altamente recomendado para:
Investigadores y académicos: que necesitan consultar docenas de artículos académicos densos a lo largo de un proyecto de varios meses.
Analistas financieros: que necesitan que su IA recuerde modelos complejos de Excel y presentaciones históricas ante la SEC sin perder el contexto.
Creadores de agentes de IA: que están desarrollando asistentes autónomos de larga duración que requieren un contexto fiable y duradero.
Equipos con mucha necesidad de conocimiento: equipos legales, médicos y de consultoría cuyo trabajo diario gira en torno a grandes volúmenes de archivos interconectados.
Desarrolladores: que quieren una infraestructura de memoria lista para usar para conectar vía API/MCP en lugar de construir desde cero complejos pipelines RAG.
Conclusión
Si estás luchando constantemente contra los límites de la ventana de contexto, las restricciones de tokens y la amnesia de la IA, la solución no es escribir mejores prompts. La solución es cambiar la forma en que tu IA maneja los archivos.
Esperar que una IA recuerde PDFs complejos, hojas de cálculo de Excel y materiales de investigación profundos a través de un historial de chat básico o cargas puntuales siempre hará que la IA empiece de nuevo. Para construir flujos de trabajo verdaderamente inteligentes y de larga duración, necesitas implementar una capa de memoria persistente.
Al utilizar MemoryLake, puedes transformar las cargas temporales de archivos en memoria de proyecto duradera y reutilizable. Ya sea que estés enriqueciendo tus documentos internos con conjuntos de datos abiertos como artículos académicos y presentaciones ante la SEC, o conectando sin problemas esta memoria a herramientas como Claude, ChatGPT y OpenClaw, MemoryLake garantiza que tu IA conserve su conocimiento. Deja de empezar de cero en cada sesión y comienza a construir flujos de trabajo de IA con una memoria que perdura.
Preguntas frecuentes
¿Cómo haces que la IA recuerde archivos PDF entre sesiones?
Para hacer que la IA recuerde PDFs entre sesiones, debes dejar atrás las interfaces de chat estándar y usar una capa de memoria persistente como MemoryLake. Al subir el PDF a un proyecto dedicado, el archivo se procesa y se almacena de forma permanente, permitiendo que cualquier herramienta de IA conectada recupere su contexto en sesiones futuras sin volver a subirlo.
¿Puede la IA recordar hojas de cálculo de Excel sin volver a subirlas?
Sí, pero no a través del historial de chat estándar. Al utilizar una infraestructura de memoria de IA, tus archivos de Excel se analizan y se almacenan como memoria estructurada del proyecto. Esto permite a la IA hacer referencia a celdas específicas, tendencias y datos tabulares en cualquier momento futuro.
¿Es suficiente RAG para flujos de trabajo de memoria de investigación?
Aunque RAG (Generación Aumentada por Recuperación) proporciona la capacidad técnica de buscar documentos, el RAG básico a menudo no es suficiente para un flujo de trabajo de investigación sin fricciones. Los usuarios necesitan una capa completa de memoria de proyecto que combine análisis de documentos, contexto conversacional, integraciones con conjuntos de datos abiertos y conectividad API/MCP sencilla con interfaces de chat reales.
¿Cuál es la mejor manera de almacenar memoria de investigación para IA?
La mejor manera es usar una infraestructura de memoria persistente que organice los datos por proyecto, admita tipos de archivos multimodales (PDF, Markdown, Excel) y te permita enriquecer la investigación privada con conjuntos de datos abiertos (como ensayos clínicos o artículos académicos).
¿Cómo funciona MemoryLake con herramientas como OpenClaw o Claude?
MemoryLake actúa como el "cerebro" externo para estas herramientas. Al configurar una clave API o pegar instrucciones de configuración directamente en herramientas como OpenClaw (que puede instalar automáticamente el complemento, configurarlo y reiniciar la puerta de enlace), otorgas a tus LLM acceso directo a tu memoria duradera del proyecto.
¿Puedes conectar MemoryLake mediante API o MCP?
Sí. MemoryLake admite integración programática tanto mediante APIs tradicionales como mediante el Protocolo de Contexto de Modelo (MCP), lo que lo hace muy flexible para desarrolladores que crean agentes de IA personalizados o aplicaciones empresariales.
¿Por qué la IA sigue empezando de nuevo con documentos?
Los modelos estándar de IA no poseen memoria local a largo plazo; dependen de ventanas de contexto temporales. Una vez que termina un chat o se alcanza el límite de tokens, los documentos subidos se expulsan de la memoria activa para hacer espacio para nuevas entradas.