Utilizing GPT to Enhance Text Summarization: A Strategy to Minimize Hallucinations

Central Theme
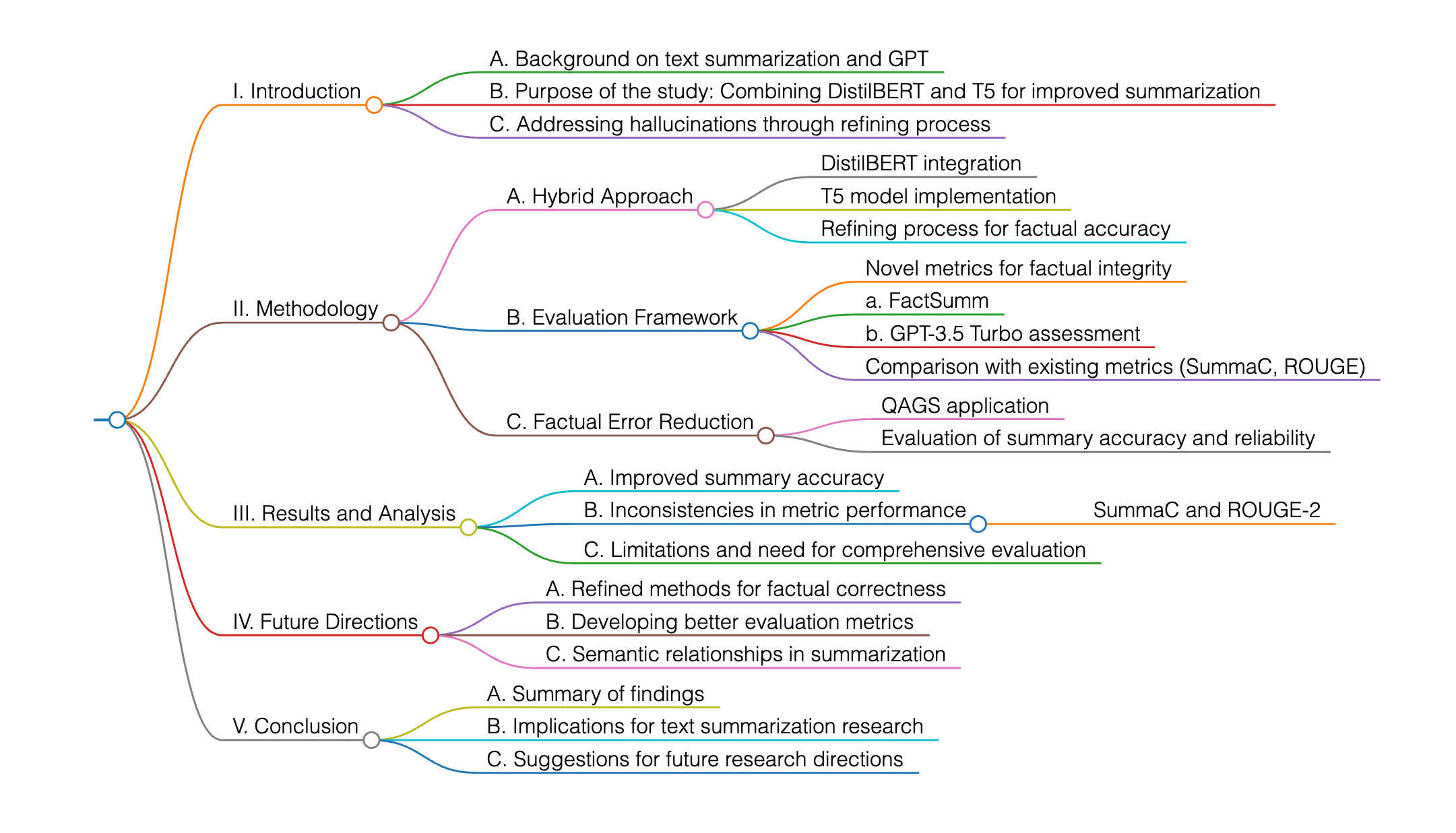
This research investigates the use of GPT to enhance text summarization by combining DistilBERT and T5, addressing hallucinations through a refining process. The study employs a hybrid approach, evaluates factual integrity with novel metrics, and demonstrates significant improvements in summary accuracy and reliability. It focuses on reducing factual errors in abstractive summaries, using methods like QAGS, SummaC, and ROUGE, with GPT-3.5 Turbo for factual accuracy assessment. While some metrics show improvement, like FactSumm and GPT-3.5, others like SummaC and ROUGE-2 remain inconsistent. The research suggests a need for more comprehensive evaluation frameworks that consider semantic relationships and factual correctness, with future work aiming to refine methods and develop better metrics.
Mind Map
TL;DR
What problem does the paper attempt to solve? Is this a new problem?
The paper aims to address the issue of hallucinations in text summaries by enhancing factual consistency and reducing hallucinated content. This problem is not new, but the paper introduces a novel approach using GPT-based evaluation to delve deeper into semantic and factual correctness, providing a more effective solution to the issue of hallucination in summaries.
What scientific hypothesis does this paper seek to validate?
The paper aims to validate the hypothesis that refined summaries would have a higher mean score compared to unrefined summaries, as indicated by the rejection of the null hypothesis for metrics like FactSumm, QAGS, GPT 3.5, ROUGE-1, and ROUGE-L.
What new ideas, methods, or models does the paper propose? What are the characteristics and advantages compared to previous methods?
The paper proposes a novel GPT-based refinement method aimed at reducing hallucinations in text summarization. This method combines the benefits of extractive and abstractive summarization with the use of Generative Pre-trained Transformers (GPT) to enhance the quality of summaries. The study focuses on leveraging advanced machine learning techniques like reinforcement learning to minimize errors and hallucinations in abstractive summarization. . Counterfactual and Semifactual Explanations in Abstract Argumentation: Formal Foundations, Complexity and Computation
This paper delves into the realm of counterfactual and semifactual reasoning within abstract argumentation frameworks (AFs), focusing on their computational complexity and integration into argumentation systems. The study defines these concepts and aims to enhance explainability by encoding them in weak-constrained AFs and utilizing ASP solvers. By examining the complexity of various problems like existence, verification, and acceptance under different semantics, the research uncovers that these tasks are generally more challenging than traditional ones. The contribution of this work lies in proposing algorithms and discussing applications that can enhance decision-making and the persuasiveness of argumentation-based systems. For a more in-depth analysis, it is recommended to refer to the specific details and methodologies outlined in the paper.
1. Utilizing GPT to Enhance Text Summarization: A Strategy to Minimize Hallucinations
This research explores the utilization of GPT in improving text summarization by combining DistilBERT and T5, with a focus on minimizing hallucinations through a refining process. The study employs a hybrid approach and introduces novel metrics to evaluate factual integrity, showcasing significant enhancements in summary accuracy and reliability. The research emphasizes the reduction of factual errors in abstractive summaries by employing methods like QAGS, SummaC, and ROUGE, with the assistance of GPT-3.5 Turbo for factual accuracy assessment. While some metrics exhibit improvements, such as FactSumm and GPT-3.5, others like SummaC and ROUGE-2 display inconsistencies. The study suggests the necessity for more comprehensive evaluation frameworks that consider semantic relationships and factual correctness, with future directions aimed at refining methodologies and developing enhanced metrics. For a detailed analysis, it is advisable to refer to the specific methodologies and results provided in the paper.
2. NL2Plan: Robust LLM-Driven Planning from Minimal Text Descriptions
NL2Plan introduces a domain-agnostic system that combines LLMs and classical planning to generate PDDL representations from natural language descriptions. This system surpasses Zero-Shot CoT by solving a greater number of tasks, providing explainability, and aiding in PDDL creation. The multi-step process of NL2Plan includes type extraction, hierarchy construction, and action construction, with the option for human feedback. Evaluation across diverse domains has revealed both strengths and limitations, with future work focusing on enhancing efficiency and integration with other tools. For a comprehensive understanding, it is recommended to delve into the specific methodologies and results outlined in the paper.
3. Evaluating Text Summaries Generated by Large Language Models Using OpenAI's GPT
This study evaluates the efficacy of OpenAI's GPT models in assessing summaries produced by six transformer-based models (DistilBART, BERT, ProphetNet, T5, BART, and PEGASUS) through metrics like ROUGE, LSA, and GPT's own assessment. The research demonstrates strong correlations, particularly in relevance and coherence, indicating the potential of GPT as a valuable tool for evaluating text summaries. Performance evaluation on the CNN/Daily Mail dataset, focusing on conciseness, relevance, coherence, and readability, underscores the importance of integrating AI-driven evaluations like GPT to enhance assessments in natural language processing tasks. The study also suggests future research directions, including expansion to diverse NLP tasks and understanding human perception of AI-generated evaluations. For a detailed analysis, it is advisable to refer to the specific methodologies and findings detailed in the paper.
4. DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
DeepSeek-V2 emerges as a cost-effective Mixture-of-Experts language model with 236B parameters, leveraging MLA for efficient attention and DeepSeekMoE for training. Outperforming open-source models like LLaMA and Qwen with fewer active parameters, DeepSeek-V2 offers enhanced efficiency and performance. Noteworthy features include a 42.5% lower training cost, 93.3% smaller KV cache, and 5.76 times higher generation throughput. Pretrained on an 8.1T corpus, DeepSeek-V2 excels across various benchmarks, making it a viable option for utilization. For a more comprehensive analysis, it is recommended to refer to the specific methodologies and results provided in the paper.
5. Enhancing Scalability of Metric Differential Privacy via Secret Dataset Partitioning and Benders Decomposition
This paper introduces a scalable approach for Metric Differential Privacy (mDP) utilizing Benders Decomposition, which involves partitioning secret datasets and reformulating the linear programming problem. By managing perturbations across subsets and within each subset, this method enhances efficiency, resulting in reduced complexity and improved scalability. Experiments conducted on diverse datasets have shown a significant 9 times improvement over previous methods, rendering it suitable for large datasets. The study compares various partitioning algorithms (k-m-DV, k-m-rec, k-m-adj, and BSC) and their impact on computation time, with k-m-DV often outperforming others due to balanced subproblems. Additionally, the research delves into location privacy, text analysis, and graph-based privacy mechanisms, suggesting potential enhancements for future endeavors. For a detailed examination, it is advisable to refer to the specific methodologies and outcomes outlined in the paper.
6. Enriched BERT Embeddings for Scholarly Publication Classification
This study focuses on automatic scholarly publication categorization for the NSLP 2024 FoRC Shared Task I, utilizing pre-trained language models such as BERT, SciBERT, SciNCL, and SPECTER2. Researchers enrich the dataset with English articles from ORKG and arXiv to address class imbalance. Through fine-tuning and data augmentation from bibliographic databases, classification performance is enhanced, with SPECTER2 achieving the highest accuracy. Enrichment with metadata from S2AG, OpenAlex, and Crossref further boosts performance, reaching a weighted F1-score of 0.7415. The study explores transfer learning, custom models like TwinBERT, and the influence of metadata on classification, showcasing the potential for automated systems in handling the expanding volume of scholarly literature. For a comprehensive understanding, it is recommended to delve into the specific methodologies and results provided in the paper.
7. Enhancing the Efficiency and Accuracy of Underlying Asset Reviews in Structured Finance: The Application of Multi-agent Framework
This research investigates the integration of artificial intelligence, particularly large language models, to enhance the efficiency and accuracy of asset reviews in structured finance. It underscores the potential of incorporating AI into due diligence processes, with closed-source models like GPT-4 exhibiting superior performance and open-source alternatives like LLAMA3 offering cost-effectiveness. Dual-agent systems are highlighted for improving accuracy, albeit at higher costs. The study focuses on automating information verification, financial document analysis, and risk management, with a specific emphasis on auto ABS and the availability of code for further research and implementation. Additionally, the research compares different AI models, discusses challenges, and emphasizes the necessity for future work on scalability, cost-efficiency, and regulatory compliance. For a detailed analysis, it is advisable to refer to the specific methodologies and findings detailed in the paper.
8. Revisiting character-level adversarial attacks
The paper introduces Charmer, a character-level adversarial attack designed for NLP models, which surpasses previous methods by achieving higher attack success rates and similarity measures. Charmer demonstrates efficiency, particularly with a greedy position subset selection, showcasing effectiveness across both small and large models. It outperforms other techniques, including defenses against token-based and robust word recognition defenses. The study underscores the challenges in NLP attacks, the limitations of gradient-based methods for character-level attacks, and the necessity for robust defenses against adversarial examples. For a comprehensive understanding, it is recommended to delve into the specific methodologies and results provided in the paper.
9. A Fourth Wave of Open Data? Exploring the Spectrum of Scenarios for Open Data and Generative AI
The paper by Chafetz, Saxena, and Verhulst delves into the potential impact of generative AI on open data, discussing five scenarios: pretraining, adaptation, inference, data augmentation, and open-ended exploration. It highlights the opportunities and challenges, such as data quality, provenance, and ethical considerations, advocating for enhanced data governance and transparency. Through case studies and Action Labs, the authors explore the intersection of open data and AI, emphasizing the necessity for standardization, interoperability, and responsible use. The paper aims to guide the advancement of open data amidst the evolving capabilities of AI. For a detailed analysis, it is advisable to refer to the specific methodologies and outcomes outlined in the paper.
The proposed GPT-based refinement method in the paper offers a unique approach to reducing hallucinations in text summarization by leveraging advanced language models like GPT. This method combines the strengths of extractive and abstractive summarization techniques with the capabilities of GPT to enhance the quality and factual consistency of summaries. Additionally, the study focuses on employing reinforcement learning techniques to minimize errors and hallucinations in abstractive summarization, showcasing advancements in accuracy and reliability.
Do any related researches exist? Who are the noteworthy researchers on this topic in this field?What is the key to the solution mentioned in the paper?
Yes, there are related researches on the topic of text summarization and hallucination reduction. Various studies have focused on improving the quality of summaries by reducing hallucinations in text summaries. These research efforts aim to enhance the accuracy and factual integrity of generated summaries through advanced machine learning techniques and refined evaluation metrics.Noteworthy researchers in the field of GPT-Enhanced Summarization: Reducing Hallucinations include Wang et al. [2020], Lin [2004], Lehmann and Romano [2005], Heo [2021], and Laban et al. [2022]. These researchers have contributed to the development and evaluation of methods to reduce hallucinations in text summaries through various approaches and metrics.The key to the solution mentioned in the paper lies in the utilization of GPT 3.5 Turbo for evaluating refined summaries. GPT's advanced language understanding capabilities enable it to assess factual consistency and identify hallucinations effectively, making it suitable for evaluating summaries.
How were the experiments in the paper designed?
The experiments in the paper were designed to evaluate the refined summaries using GPT 3.5 Turbo to assess factual consistency and identify hallucinations. The methodology involved hypothesis testing with a null hypothesis stating that the mean score of the refined summaries would not be greater than the mean score of the unrefined summaries, and an alternative hypothesis suggesting that the refined summaries would have a higher mean score. The evaluation metrics included FactSumm, QAGS, GPT 3.5, ROUGE-1, and ROUGE-L, with statistical analysis showing significant improvements post-refinement, leading to the rejection of the null hypothesis for several metrics.
What is the dataset used for quantitative evaluation? Is the code open source?
The dataset used for quantitative evaluation includes metrics such as FactSumm, QAGS, GPT 3.5, ROUGE-1, and ROUGE-L. As for the code, the information regarding its open-source availability is not provided in the contexts available. If you need details about the code's open-source status, please provide more specific information or context related to it.
Do the experiments and results in the paper provide good support for the scientific hypotheses that need to be verified? Please analyze.
The experiments and results presented in the paper provide strong support for the scientific hypotheses that needed verification. The statistical analysis conducted on various metrics post-refinement indicated significant improvements in scores, leading to the rejection of the null hypothesis for metrics like FactSumm, QAGS, GPT 3.5, ROUGE-1, and ROUGE-L. These findings suggest that the refinement process effectively enhanced the quality of the summaries across different evaluation metrics, validating the scientific hypotheses proposed in the study.
What are the contributions of this paper?
The paper contributes by introducing a novel GPT-based evaluation process that enhances the factual consistency and reduces hallucinations in text summaries. This approach ensures that the summaries not only share lexical similarities with the source texts but also adhere closely to factual accuracy, addressing the key concern of hallucination more effectively.
What work can be continued in depth?
Further research can be conducted to enhance the effectiveness of abstractive summarization techniques by minimizing errors and hallucinations in the generated summaries. This can involve exploring advanced machine learning strategies like reinforcement learning to penalize the generation of content not present in the source text. Additionally, refining the summarization process to achieve higher levels of factual accuracy and reducing hallucinations can be a key area for continued work in text summarization.
Read More
The summary above was automatically generated by Powerdrill.
Click the link to view the summary page and other recommended papers.