Demonstration of DB-GPT

Central Theme
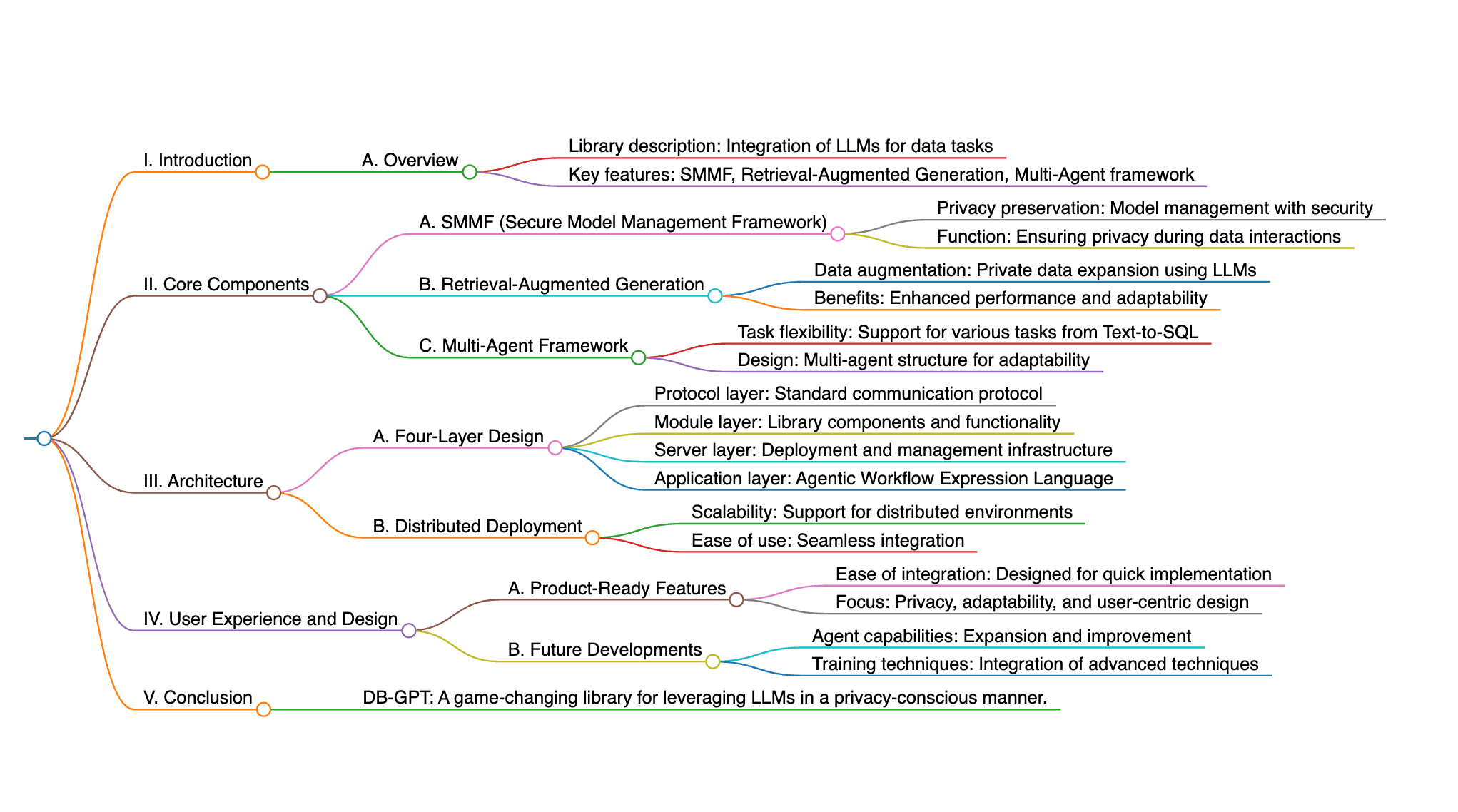
DB-GPT is an open-source Python library that revolutionizes data interaction by integrating large language models into tasks, ensuring privacy with the SMMF and supporting tasks from Text-to-SQL to complex analysis. Key components include the SMMF for model management, Retrieval-Augmented Generation for private data augmentation, and a Multi-Agent framework for task flexibility. The library features a four-layer architecture (Protocol, Module, Server, Application) with Agentic Workflow Expression Language, and supports deployment in distributed environments. DB-GPT enhances LLMs, offers product-ready features, and is designed for easy integration, with a focus on privacy, adaptability, and user experience. Future developments will expand agent capabilities and integrate more training techniques.
Mind Map
TL;DR
Q1. What problem does the paper attempt to solve? Is this a new problem?
The paper aims to address the challenge of enhancing data interaction tasks with Large Language Models (LLMs) to provide users with reliable understanding and insights into their data . This is not a new problem as the integration of LLMs in data interaction tasks has been an ongoing area of research and development.
Q2. What scientific hypothesis does this paper seek to validate?
The paper seeks to validate the hypothesis that integrating large language models (LLMs) into data interaction tasks can enhance user experience and accessibility by providing context-aware responses powered by LLMs, making it an indispensable tool for users ranging from novice to expert .
Q3. What new ideas, methods, or models does the paper propose?
What are the characteristics and advantages compared to previous methods?The paper proposes DB-GPT, a Python library that integrates large language models (LLMs) into traditional data interaction tasks to enhance user experience and accessibility . It introduces a Multi-Agents framework inspired by MetaGPT and AutoGen to address challenging data interaction tasks like generative data analysis . This framework leverages multiple agents with specialized capabilities to handle multifaceted challenges, such as constructing detailed sales reports from different dimensions . Additionally, DB-GPT's Multi-Agent framework archives the communication history among agents, enhancing the reliability of generated content . The paper also discusses the importance of incorporating LLM-powered automated reasoning and decision processes into data interaction tasks . It emphasizes the need for task-agnostic multi-agents frameworks to cater to various data interaction tasks effectively . Furthermore, the paper highlights the significance of privacy-sensitive setups for LLM-empowered data interactions, an aspect that has been under-investigated in previous efforts . The paper outlines several characteristics and advantages of DB-GPT compared to previous methods. DB-GPT integrates large language models (LLMs) into data interaction tasks, providing context-aware responses powered by LLMs, enhancing user experience and accessibility . It offers a Multi-Agents framework that leverages specialized capabilities of multiple agents to effectively address multifaceted challenges in generative data analysis . Unlike previous frameworks, DB-GPT's Multi-Agent framework archives the entire communication history among agents, significantly enhancing the reliability of the generated content . Additionally, DB-GPT incorporates privacy measures to protect private information, ensuring secure data interactions . The paper emphasizes the importance of task-agnostic multi-agents frameworks to cater to a broad range of data interaction tasks effectively, a feature that sets DB-GPT apart from previous methods . Moreover, DB-GPT addresses the need for privacy-sensitive setups in LLM-empowered data interactions, an aspect that has been under-investigated in prior efforts . These characteristics collectively position DB-GPT as a versatile and secure tool for enhancing data interaction tasks with the integration of LLMs and multi-agent frameworks .
Q4. What related research exists? How can it be categorized? Who are the noteworthy researchers in this field on this topic?
What is the key to the solution mentioned in the paper?Research related to data interaction tasks with large language models (LLMs) has been explored extensively . This research can be categorized into areas such as enhancing data interaction tasks with LLMs, incorporating automated reasoning and decision processes into data interactions, and addressing privacy concerns in LLM-empowered data interactions . Noteworthy researchers in this field include Siqiao Xue, Danrui Qi, Caigao Jiang, and other contributors from various organizations such as Ant Group, Alibaba Group, and JD Group . The key solution proposed in the paper involves the development of an open-sourced Python library called DB-GPT, which supports data interaction using multi-agents with flexible arrangements and a four-layer system design to handle complex data interaction tasks with privacy considerations .
Q5. How were the experiments in the paper designed?
The experiments in the paper were designed to showcase the capabilities of DB-GPT, a Python library that integrates large language models (LLMs) into traditional data interaction tasks . The setup involved using a laptop connected to the Internet to access DB-GPT smoothly with OpenAI's GPT service, with options for local models like Qwen and GLM . The experiments demonstrated DB-GPT's ability to perform generative data analysis by initiating tasks through natural language inputs, utilizing a Multi-Agent framework to generate strategies and specialized agents for tasks like creating data analytics charts and aggregating them for user interaction .
Q6. What is the dataset used for quantitative evaluation?Is the code open source?
The dataset used for quantitative evaluation in the DB-GPT system is not explicitly mentioned in the provided contexts . However, the code for DB-GPT is open source and available on Github with over 10.7k stars, allowing users to access and utilize it for their own purposes .
Q7. Do the experiments and results in the paper provide good support for the scientific hypotheses that need to be verified? please analyze as much as possible.
The experiments and results presented in the paper provide substantial support for the scientific hypotheses that need to be verified . The paper demonstrates a retrieval-augmented generation approach for knowledge-intensive NLP tasks, showcasing the effectiveness of the proposed method . By leveraging retrieval-augmented generation, the system enhances the generation of responses by integrating knowledge retrieval results during the inference process . This approach significantly improves the response generation process by incorporating relevant information retrieved from the knowledge base . The results suggest that the system effectively integrates retrieval strategies and interactive contextual learning to enhance the responses generated by the language model . Overall, the experiments and results provide strong evidence supporting the effectiveness of the proposed approach in addressing knowledge-intensive NLP tasks .
Q8. What are the contributions of this paper?
The paper presents DB-GPT, a Python library that integrates large language models (LLMs) into data interaction tasks, enhancing user experience and accessibility . It offers context-aware responses powered by LLMs, enabling users to describe tasks in natural language and receive relevant outputs . Additionally, DB-GPT can handle complex tasks like generative data analysis through a Multi-Agents framework and the Agentic Workflow Expression Language (AWEL) . The system design supports deployment across local, distributed, and cloud environments, ensuring data privacy and security with the Service-oriented Multi-model Management Framework (SMMF) .
Q9. What work can be continued in depth?
Further research can be conducted to enhance the capabilities of large language models (LLMs) in data interaction tasks, particularly focusing on improving the understanding and insights provided to users . Additionally, exploring the development of more task-agnostic multi-agents frameworks to broaden the range of tasks they can handle effectively would be beneficial. Moreover, investigating and refining the privacy-sensitive setup for LLM-empowered data interaction to ensure user data security could be an area for continued work.