Using Powerdrill AI for Comprehensive Alzheimer's Disease Analysis

In the field of medical research, data-driven decision-making significantly enhances the understanding and treatment of complex diseases like Alzheimer's. Utilizing advanced data analysis techniques such as those offered by Powerdrill AI allows researchers to extract valuable insights from intricate medical data. This article will demonstrate how to use Powerdrill AI for comprehensive analysis of Alzheimer's disease data, providing a detailed case study using real patient data to uncover critical factors influencing the disease's progression and diagnosis.
Outlining the Alzheimer's Disease Data Workflow
1. Data Ingestion
Collection: Gather relevant medical data, including patient records, clinical measurements, and health history.
Alignment: Ensure data sources align with research objectives and provide comprehensive coverage of patient health information.
2.Data Cleaning and Preprocessing
Consistency: Address inconsistencies by handling missing values, removing duplicates, and standardizing data formats.
Quality: Ensure data quality and accuracy for reliable analysis.
3.Exploratory Data Analysis (EDA)
Examination: Conduct initial exploration using statistical summaries and visualizations.
Identification: Identify trends, patterns, and anomalies to understand the dataset’s structure and key characteristics.
4.Behavioral Analysis
Patterns: Analyze patient behaviors and medical history to uncover health and lifestyle patterns.
Targeting: Use insights to develop effective intervention and treatment strategies.
5.Predictive Model Building
Selection: Choose appropriate machine learning or statistical models for predictive analysis.
Training: Train the model using relevant features and target variables, validating its performance with cross-validation.
Evaluation: Assess the model's accuracy, precision, recall, and F1 score using a test dataset.
6.Results Interpretation and Deployment
Context: Interpret results in the context of research objectives.
Action: Translate findings into actionable insights and integrate them into medical decision-making processes.
Case Study Introduction
In medical research, data-driven decision-making enhances the understanding and treatment of complex diseases like Alzheimer's. Using Powerdrill AI, this case study demonstrates a comprehensive analysis of Alzheimer's disease with real patient data to uncover key factors influencing its progression and diagnosis.
Question Formulation
In medical data analytics, formulating the right questions is crucial for guiding your analysis and deriving meaningful insights. It's like setting a clear objective for your investigation, helping you focus on the essential aspects of your data. For example, with our Alzheimer's disease dataset, we posed the question:
"What are the key factors that contribute to the progression and diagnosis of Alzheimer's disease in patients over time?"
This question directs us to analyze various elements such as patient demographics, lifestyle factors, medical history, and clinical measurements. By clearly defining our question, we ensure that our analysis remains focused and effective, allowing us to extract actionable insights that can improve diagnosis, treatment strategies, and patient care.
Data Ingestion
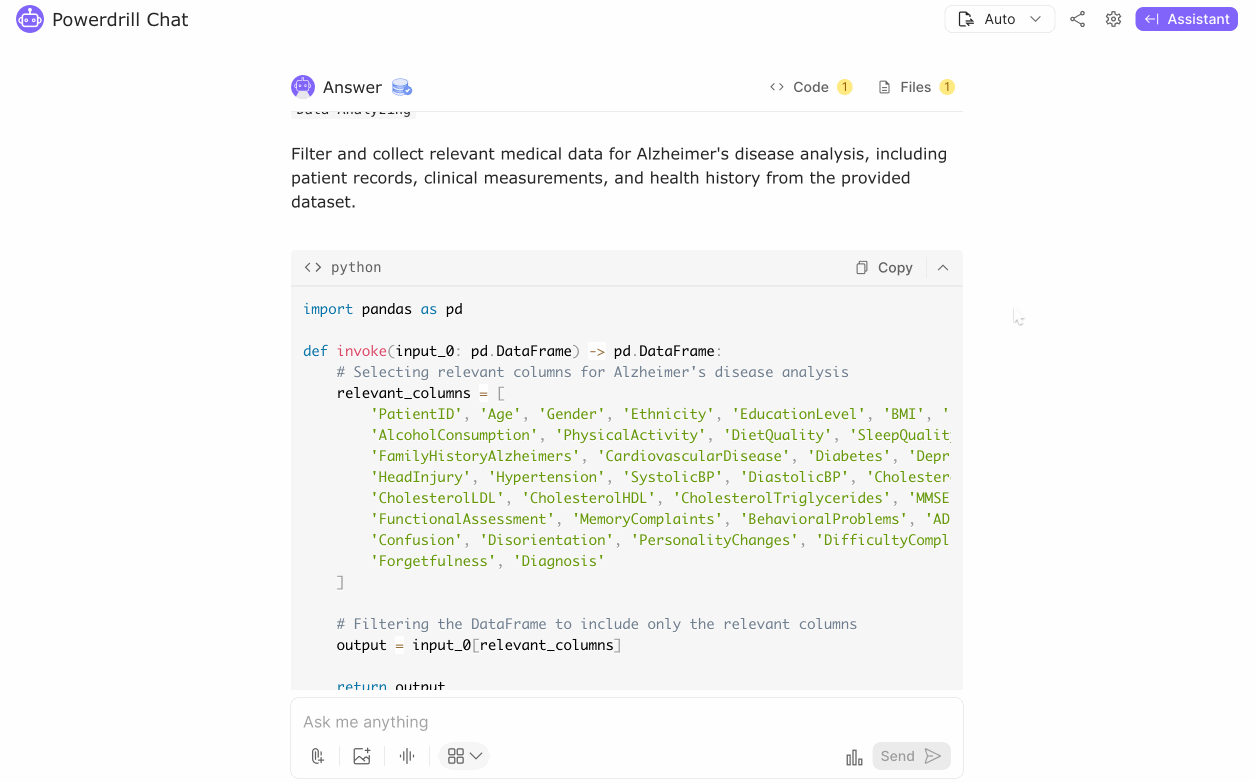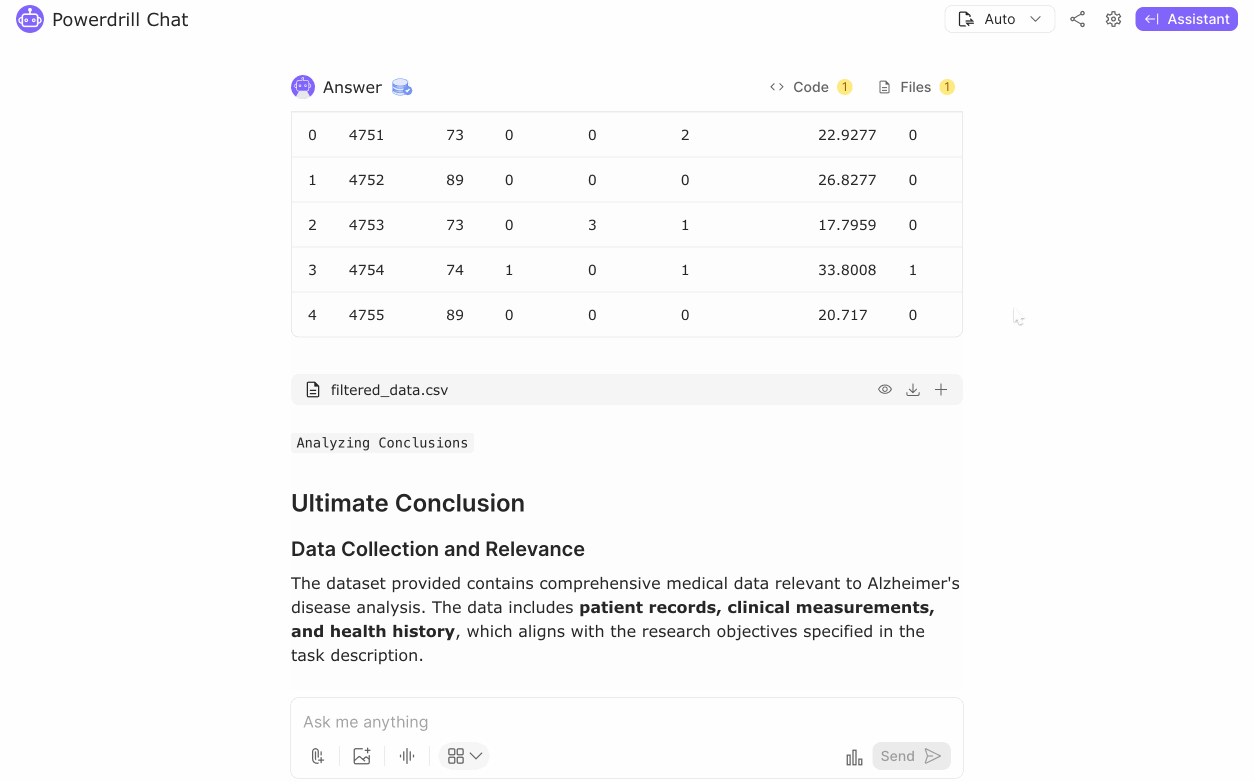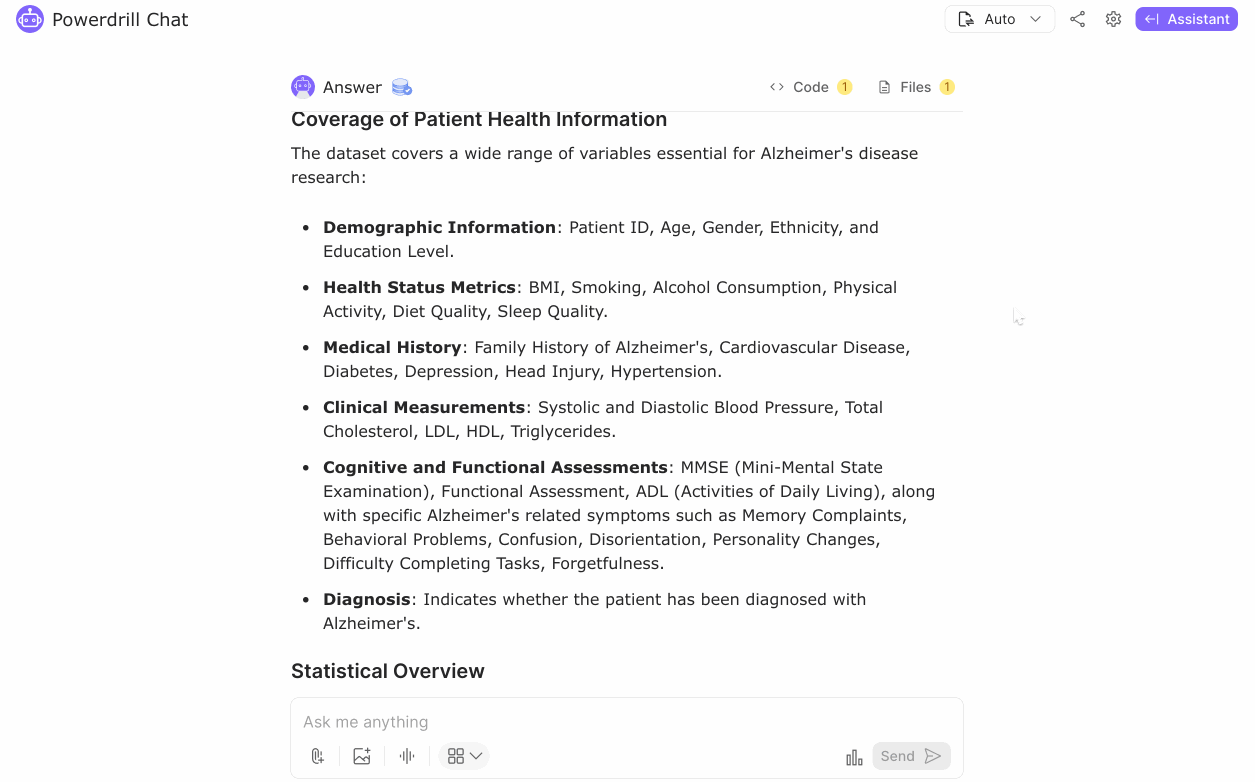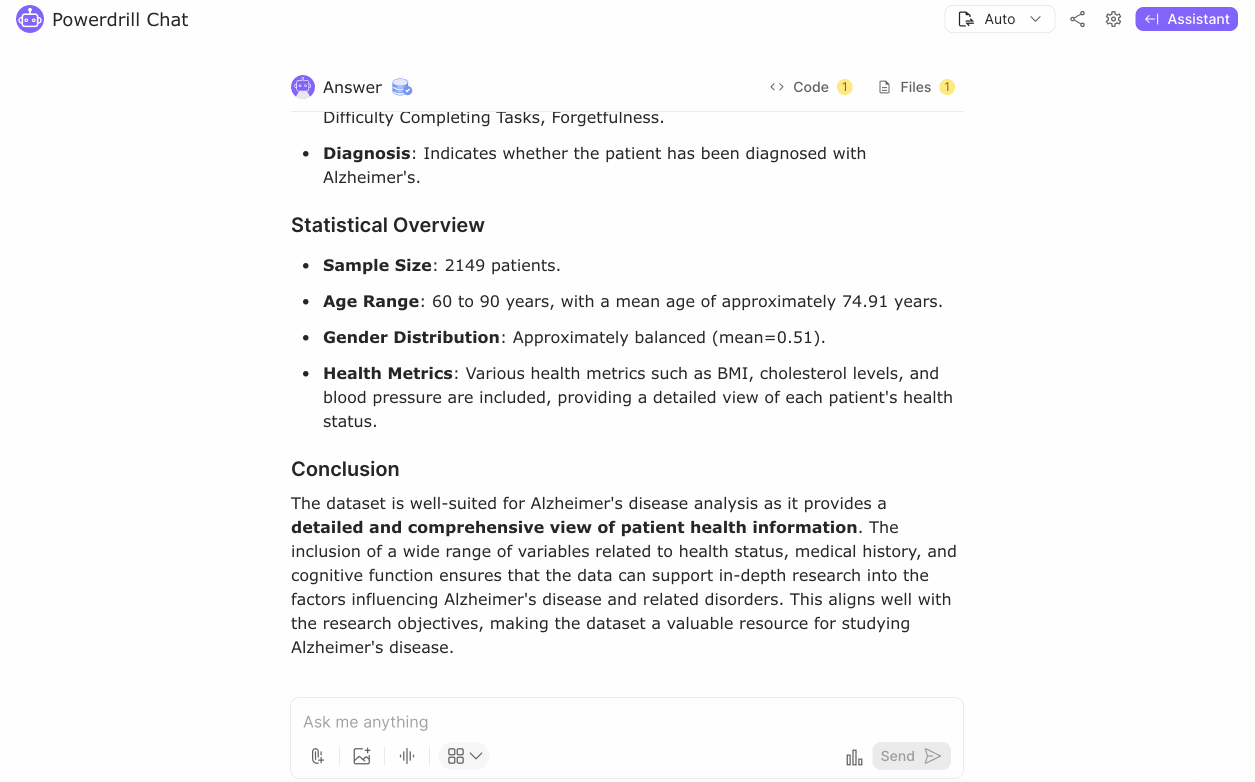
In medical data analytics, collecting the right data is fundamental. For our case study on Alzheimer's disease progression and diagnosis, we gathered comprehensive patient records, including demographics, clinical measurements, lifestyle factors, and medical history. This data is critical to answering our key questions about the factors influencing the disease's progression and diagnosis. It’s important to ensure that the data aligns with our analysis objectives. While new data collection might be necessary in some scenarios, here we utilized existing data that already encompasses all the relevant details we need for our analysis. Acquiring accurate and relevant data is the essential first step towards uncovering actionable insights.
Data Cleaning and Preprocessing
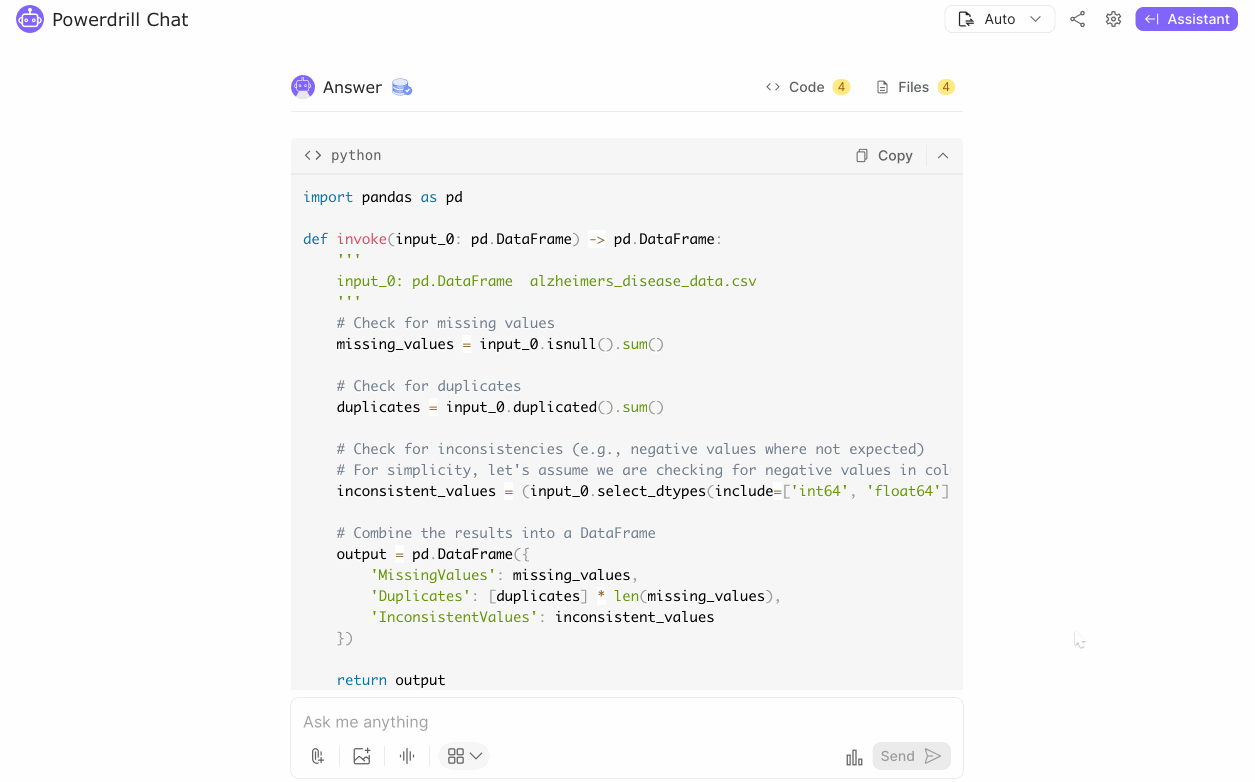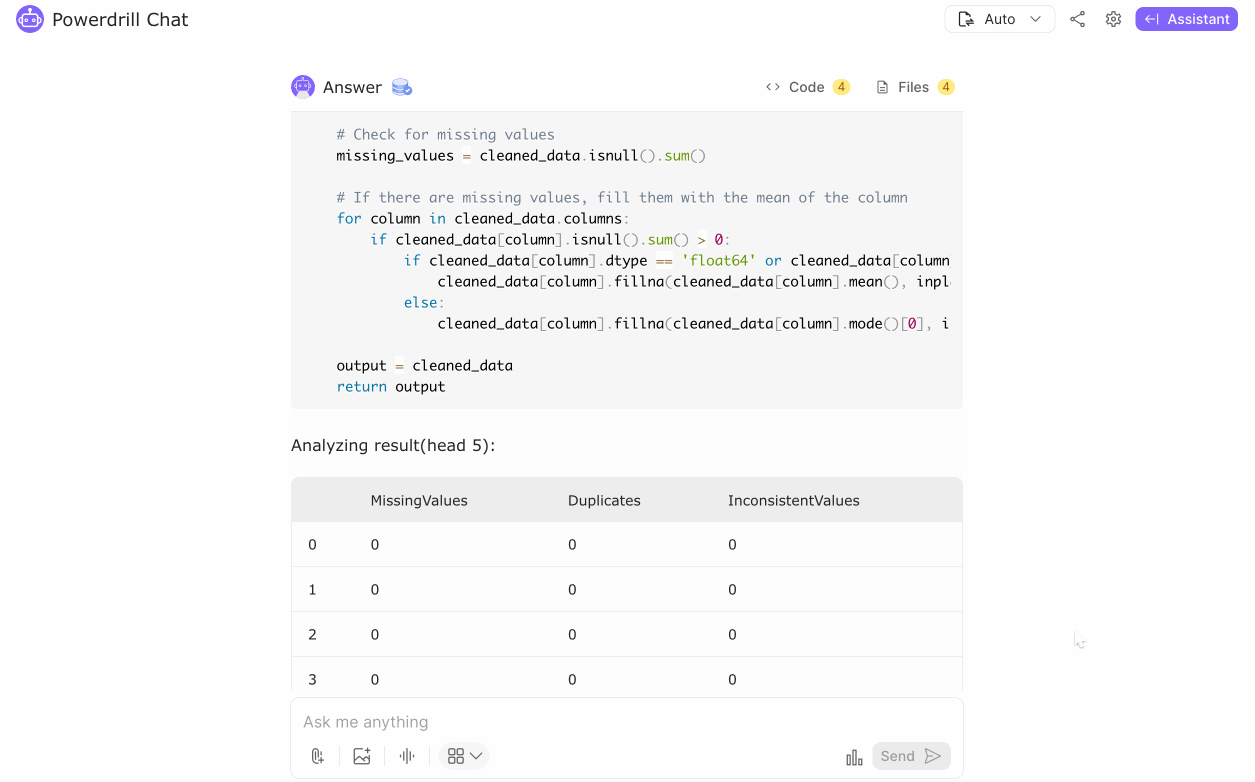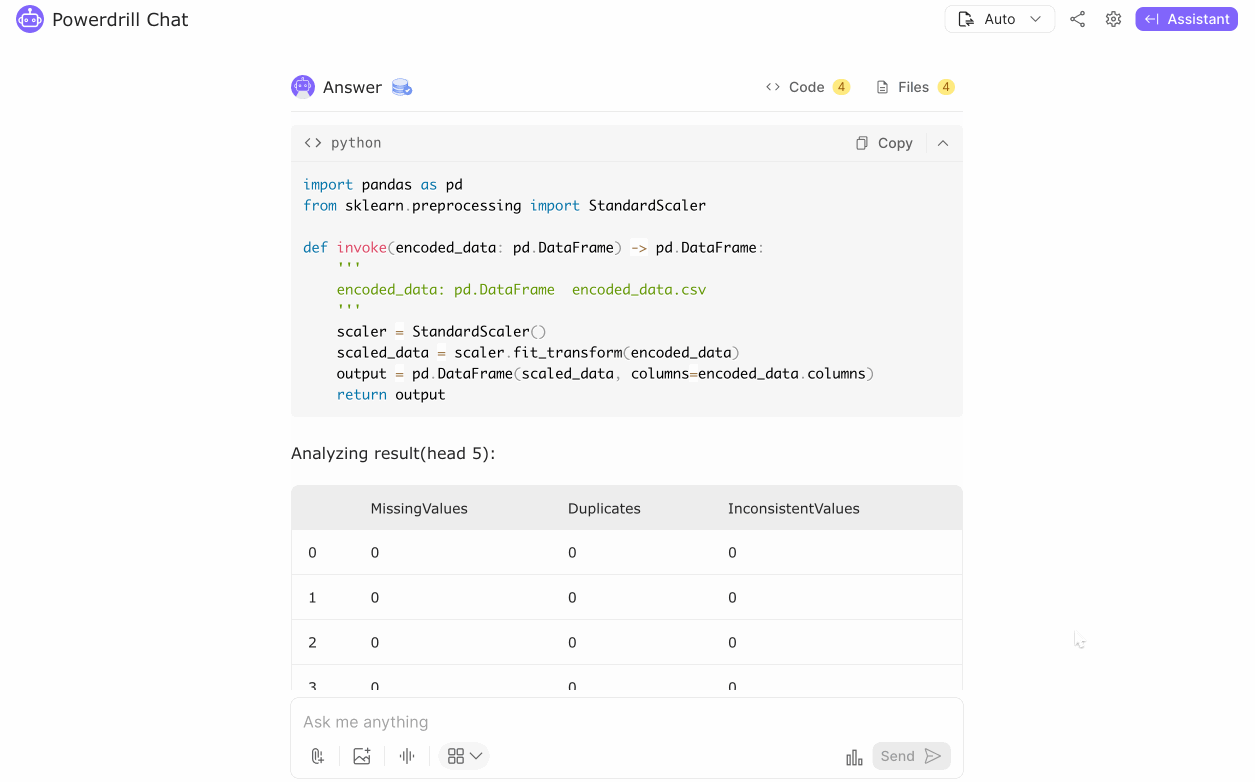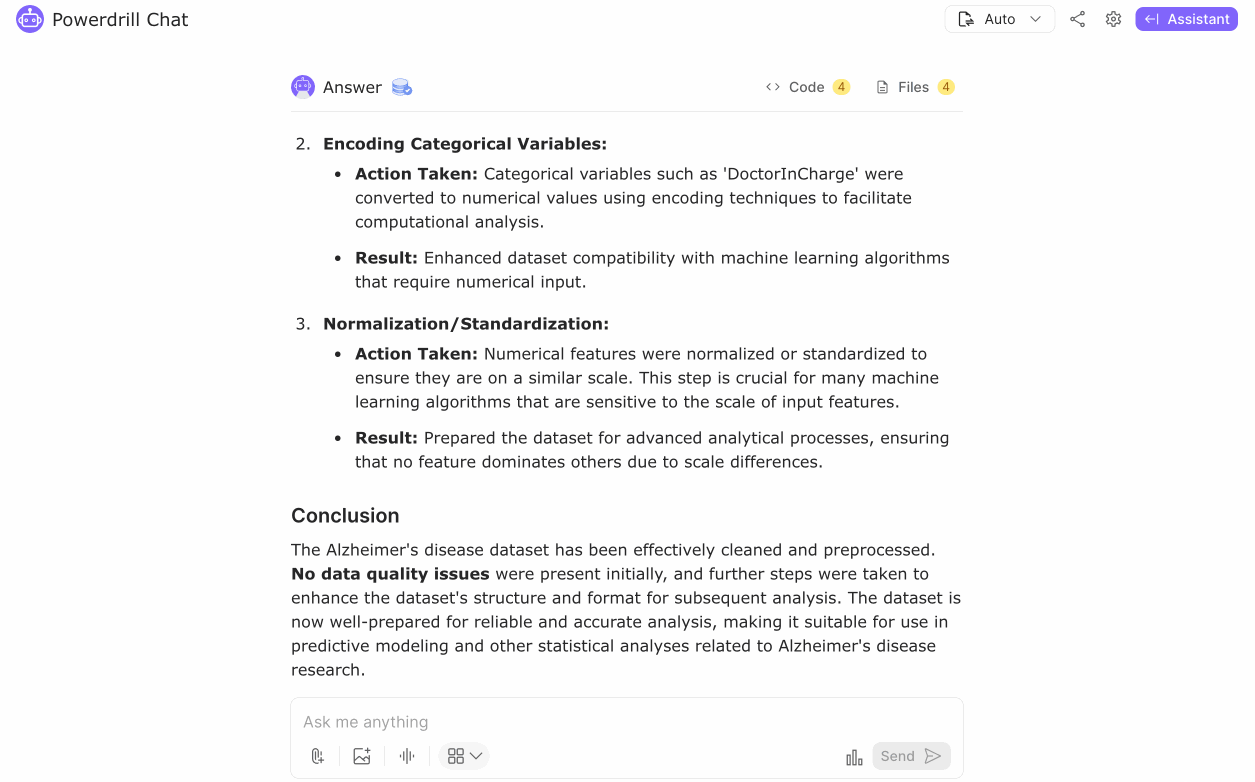
In our Alzheimer's disease analysis, data cleaning and preprocessing were crucial for ensuring optimal data integrity. Initially, the dataset was checked and found to have no missing values or duplicate records, confirming the uniqueness and reliability of each entry.
Although no missing values were detected, we had procedures ready to handle any potential gaps using statistical measures. Categorical variables like 'DoctorInCharge' were converted to numerical values using encoding techniques, making them suitable for machine learning algorithms.
Numerical features were normalized or standardized to ensure they were on a similar scale, crucial for algorithms sensitive to input feature scales. This preprocessing step ensured that no feature dominated others due to scale differences.
In conclusion, the Alzheimer's disease dataset has been effectively cleaned and preprocessed. These steps have prepared the dataset for accurate and reliable analysis, making it suitable for predictive modeling and other statistical analyses related to Alzheimer's disease research.
Exploratory Data Analysis (EDA)
After thoroughly cleaning and preprocessing the Alzheimer's disease dataset to ensure no missing values or duplicate records and standardizing numerical features, we proceeded to the exploratory data analysis (EDA) phase. This phase provided key insights into the dataset, which includes demographics, clinical measurements, and diagnosis information.
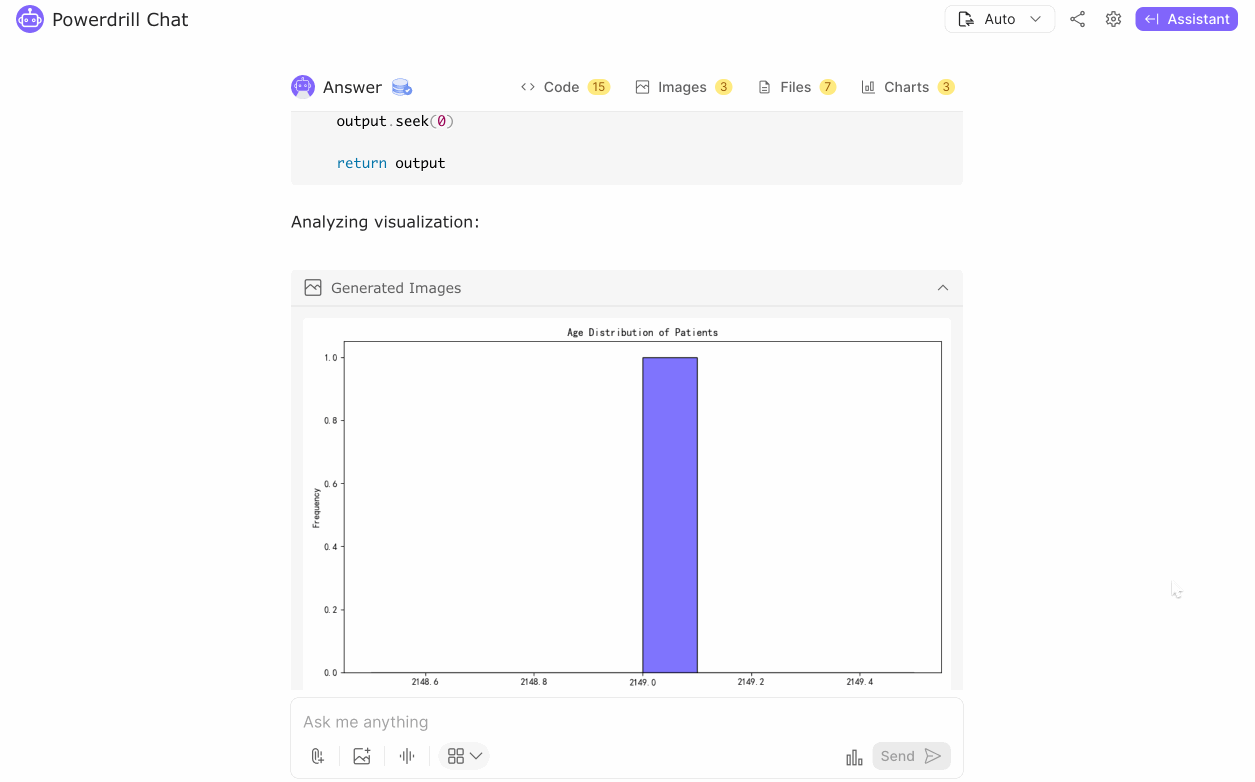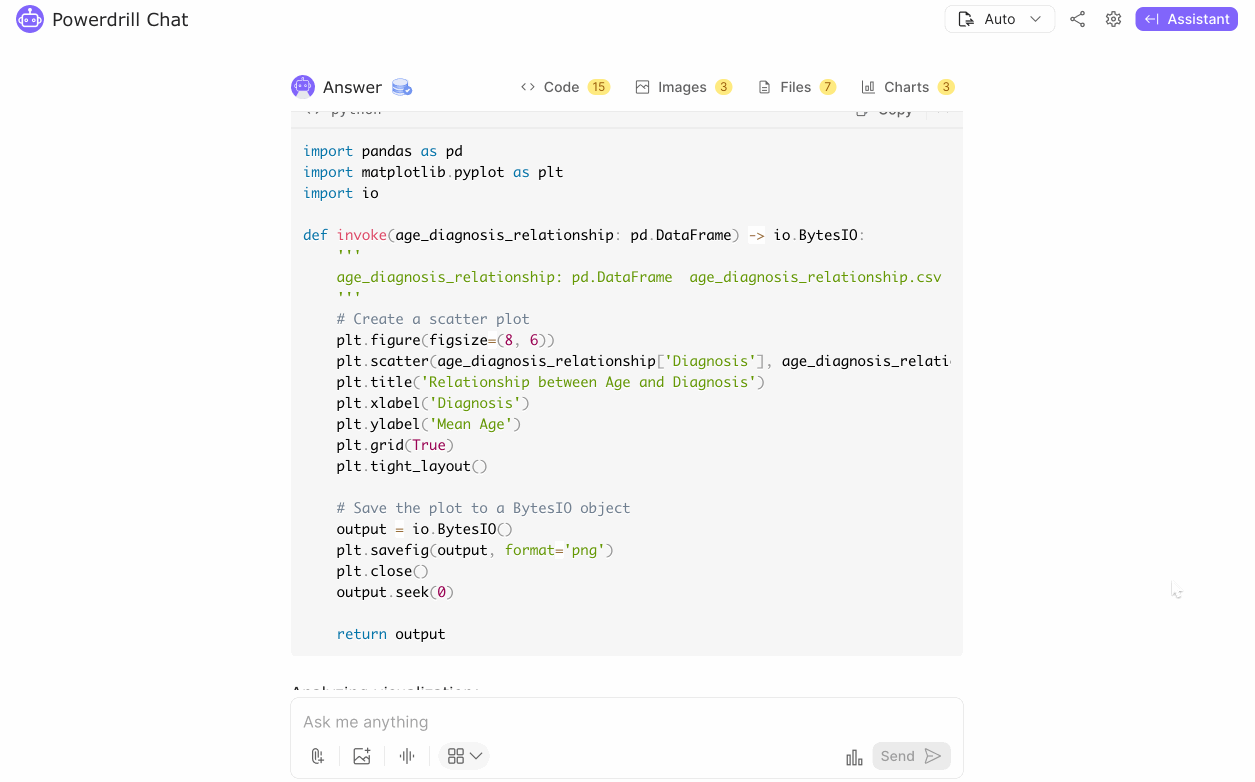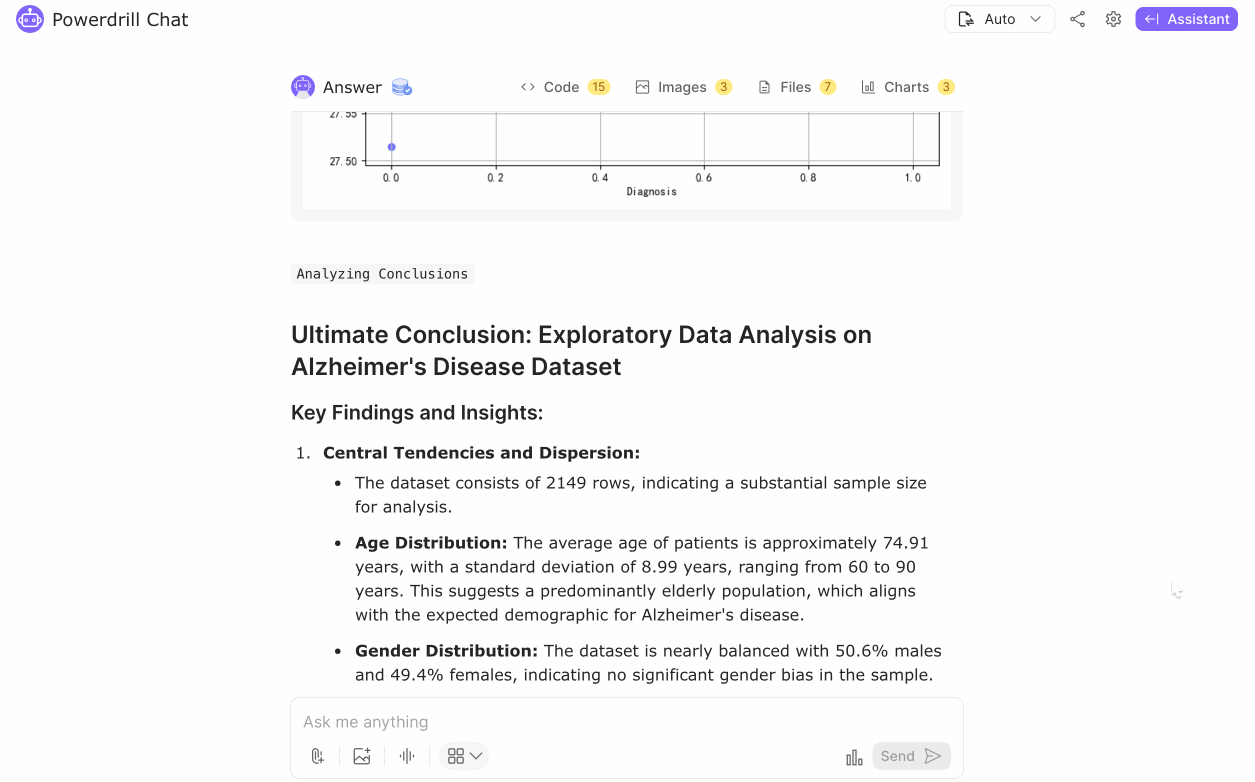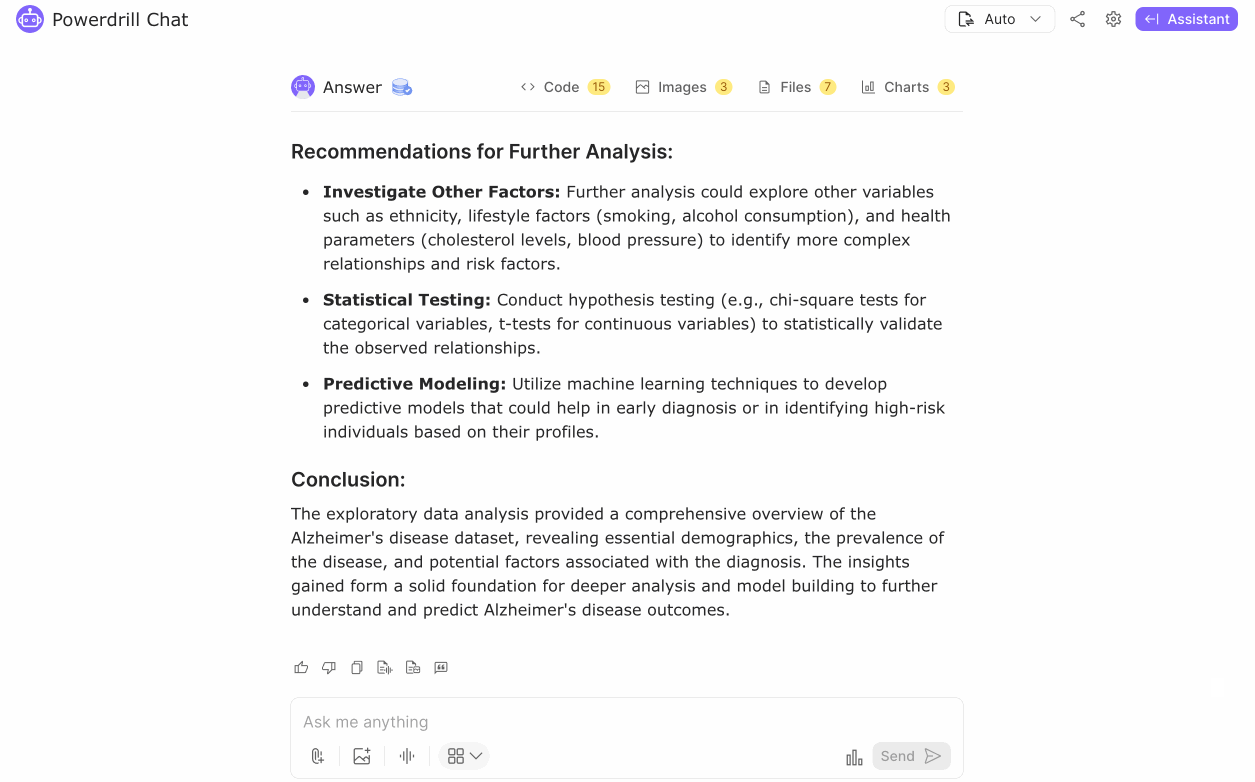
The dataset consists of 2149 rows, offering a substantial sample size for analysis. Descriptive statistics revealed that the average age of patients is approximately 74.91 years, with a standard deviation of 8.99 years, indicating a predominantly elderly population. Gender distribution is nearly balanced, with 50.6% males and 49.4% females, showing no significant gender bias.
Regarding diagnosis, 35.37% of the patients are diagnosed with Alzheimer's disease, while 64.63% are not. This provides a clear baseline for understanding the proportion of affected individuals. Further analysis showed that the mean age for both diagnosed and non-diagnosed groups is about the same, suggesting age alone may not be a significant differentiator. However, the mean BMI for diagnosed patients is slightly higher (27.91) compared to non-diagnosed patients (27.52), indicating a potential association that warrants further investigation.
Powerful visualizations, including histograms, pie charts, bar charts, and scatter plots, were employed to illustrate the distribution of age, gender, and diagnosis, and the relationship between age, BMI, and diagnosis. These visualizations helped in identifying trends and patterns within the data.
The exploratory data analysis provided a comprehensive overview of the Alzheimer's disease dataset, revealing essential demographics, the prevalence of the disease, and potential factors associated with the diagnosis. This EDA uncovered significant trends and laid the groundwork for deeper exploration, such as investigating other variables like ethnicity, lifestyle factors, and health parameters to identify more complex relationships and risk factors. Additionally, statistical testing and predictive modeling could be employed to further understand and predict Alzheimer's disease outcomes.
Behavioral Analysis
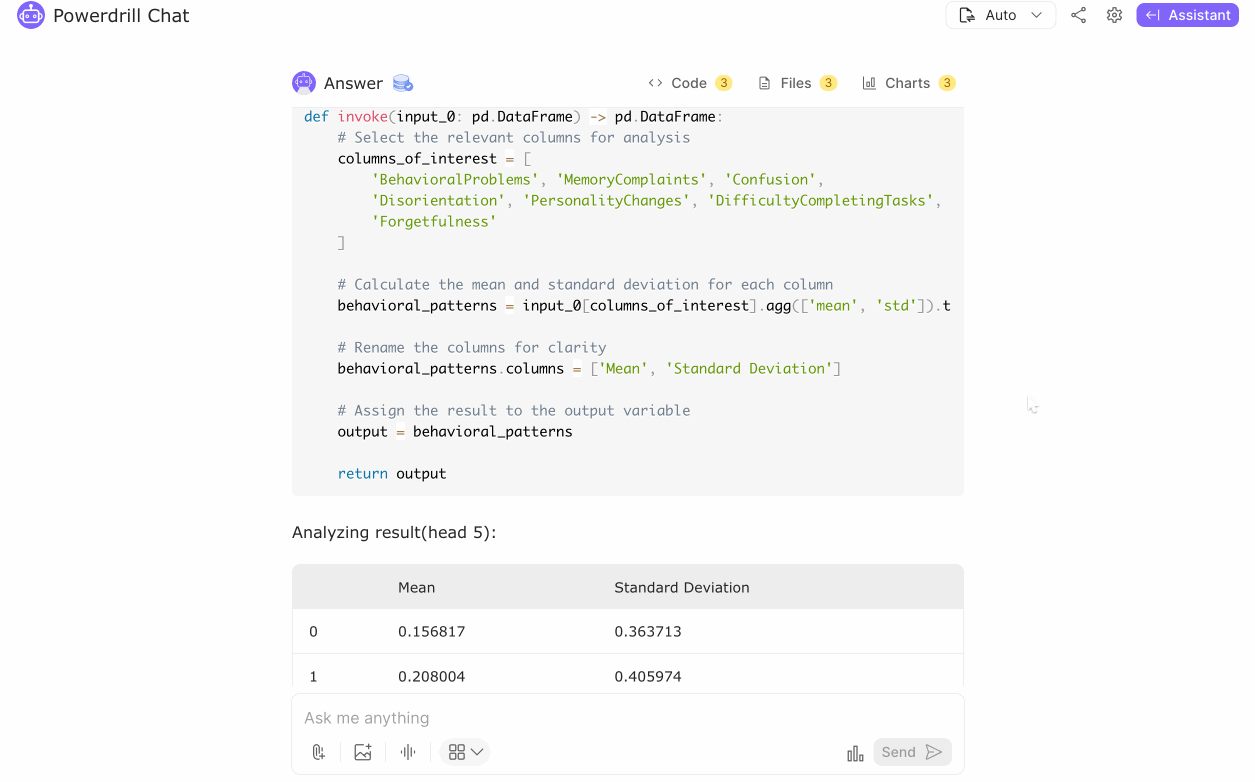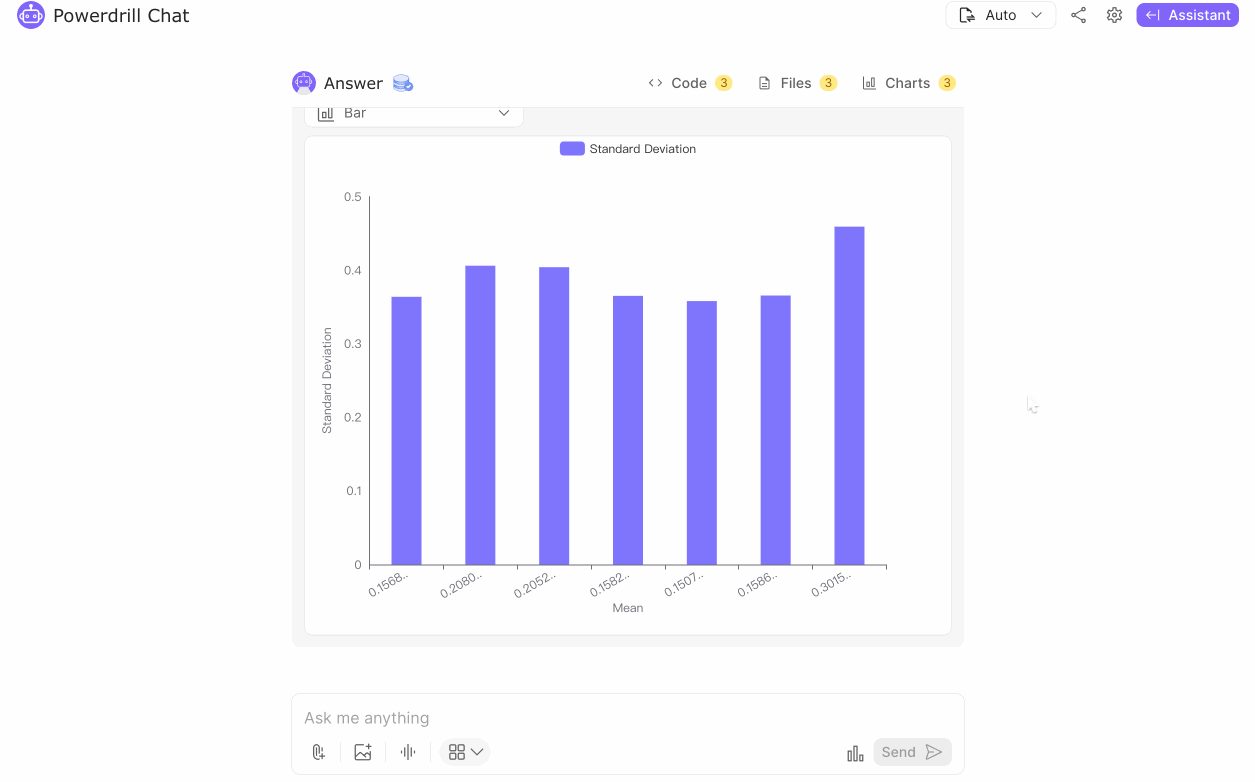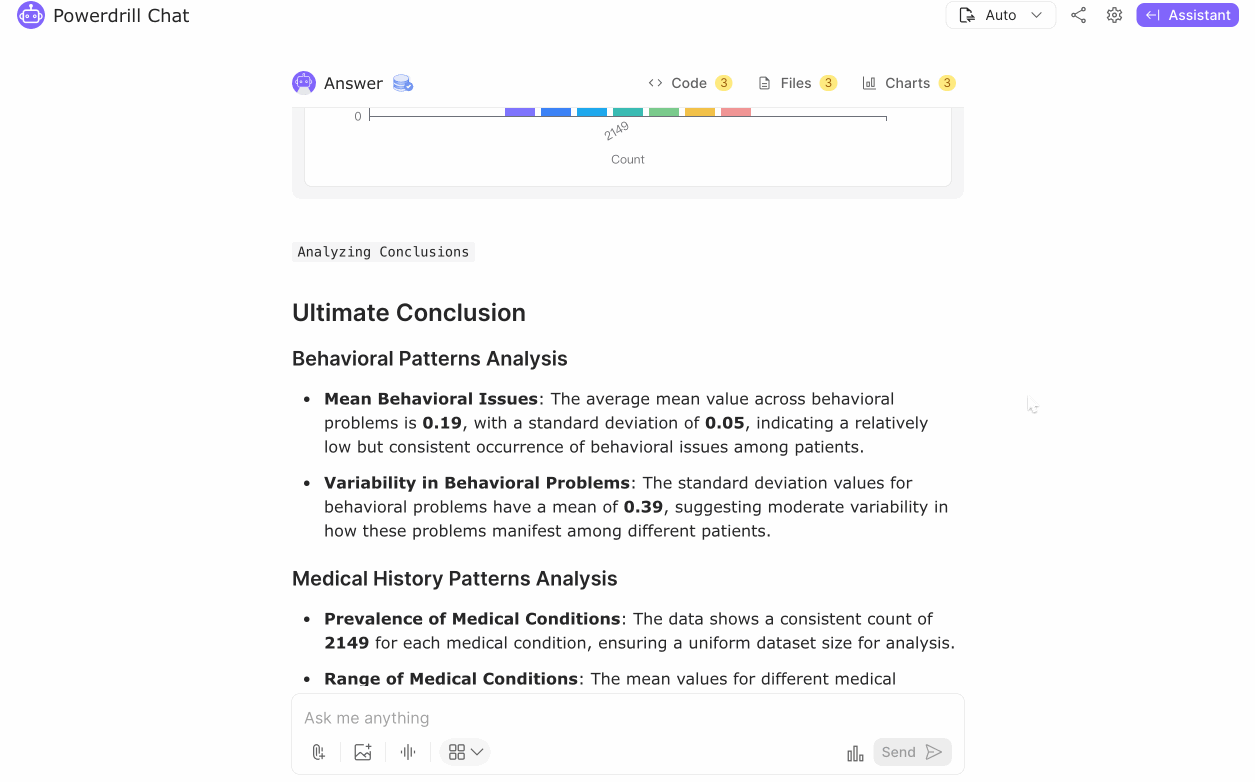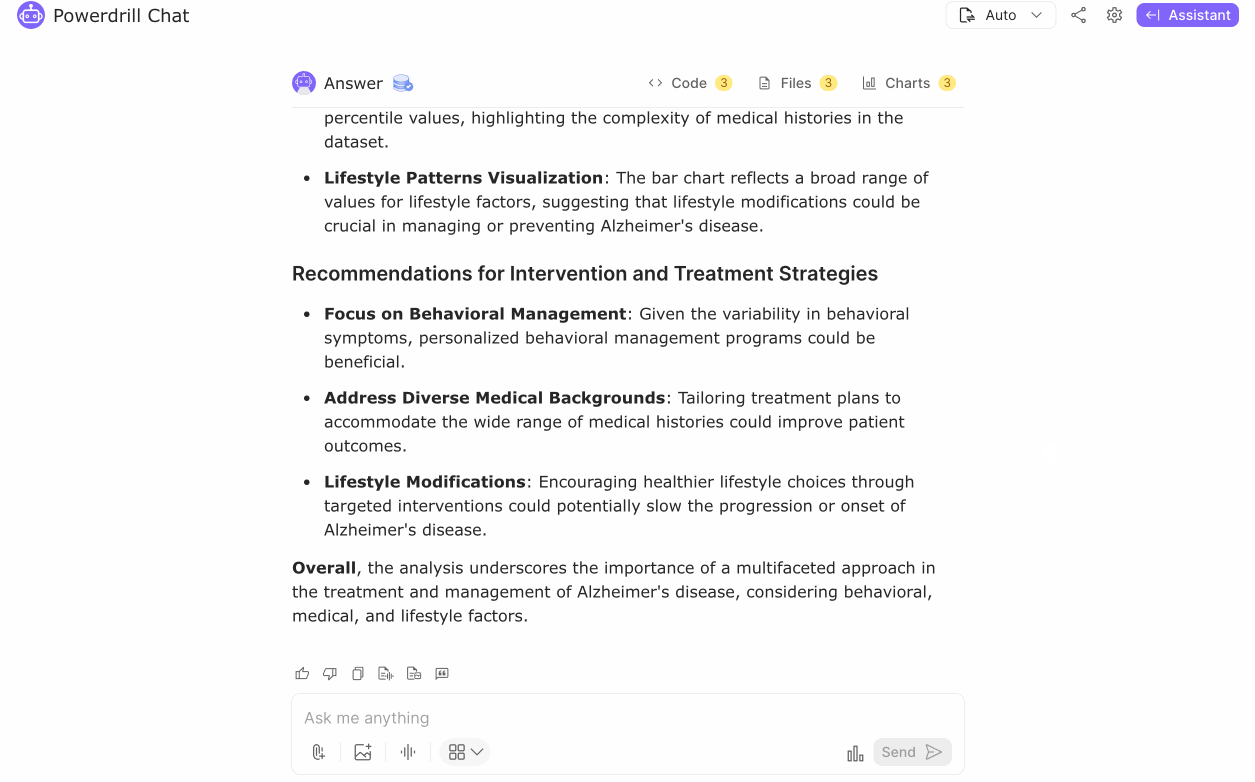
Using the Alzheimer's disease dataset, we performed a detailed analysis to identify key behavioral patterns, medical history insights, and lifestyle factors influencing the disease. Visualizations indicated notable trends:
Behavioral Patterns Analysis: The average mean value for behavioral issues is 0.19 with a standard deviation of 0.05, indicating a low but consistent occurrence of behavioral problems among patients. The standard deviation for behavioral problems has a mean of 0.39, suggesting moderate variability in how these issues manifest across different patients.
Medical History Patterns Analysis: The dataset consistently counts 2149 records for each medical condition, ensuring uniform dataset size for analysis. The mean values for different medical conditions vary significantly, with an overall average of 71.87 and a high standard deviation of 88.39. This indicates a diverse range of medical backgrounds among patients.
Lifestyle Patterns Analysis: The mean scores for lifestyle factors like smoking, alcohol consumption, physical activity, diet quality, and sleep quality average at 5.46, with a standard deviation of 3.56, reflecting varied lifestyle habits. The standard deviation of 2.75 for these factors points to significant differences in lifestyle choices among patients, which could influence health outcomes.
Predictive Model Building
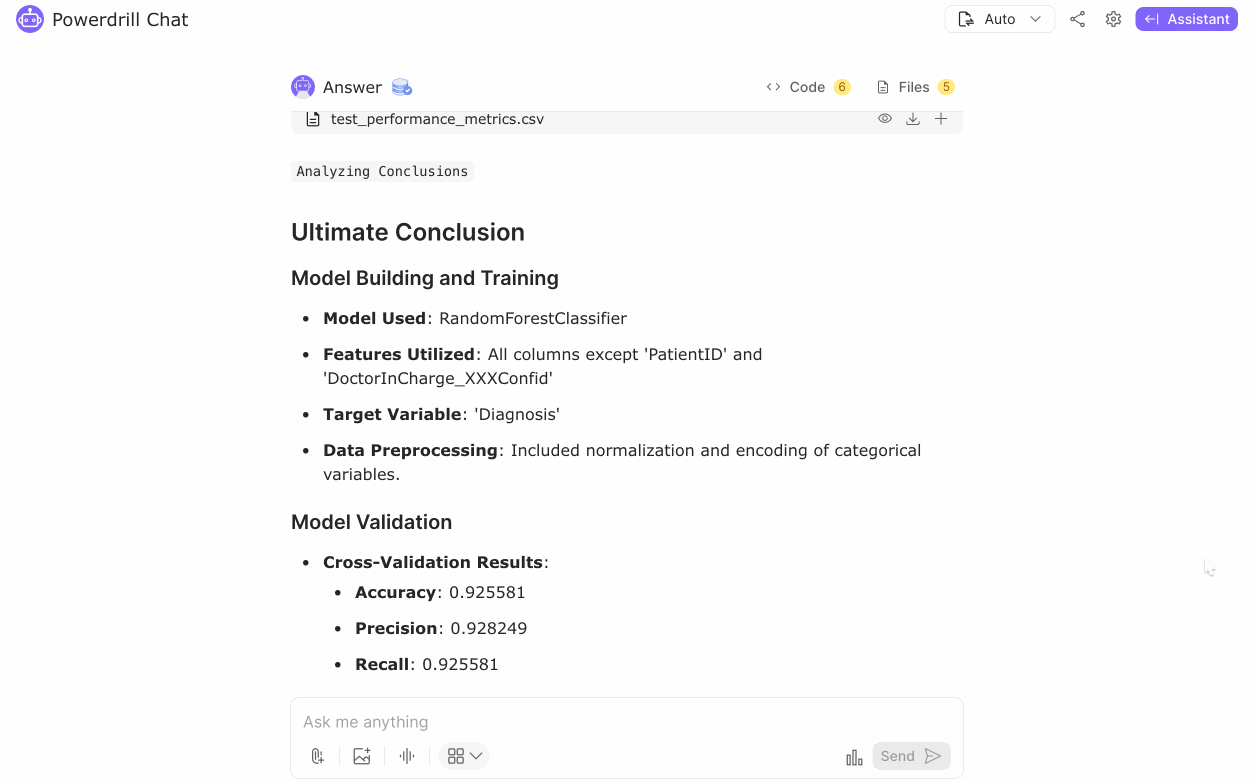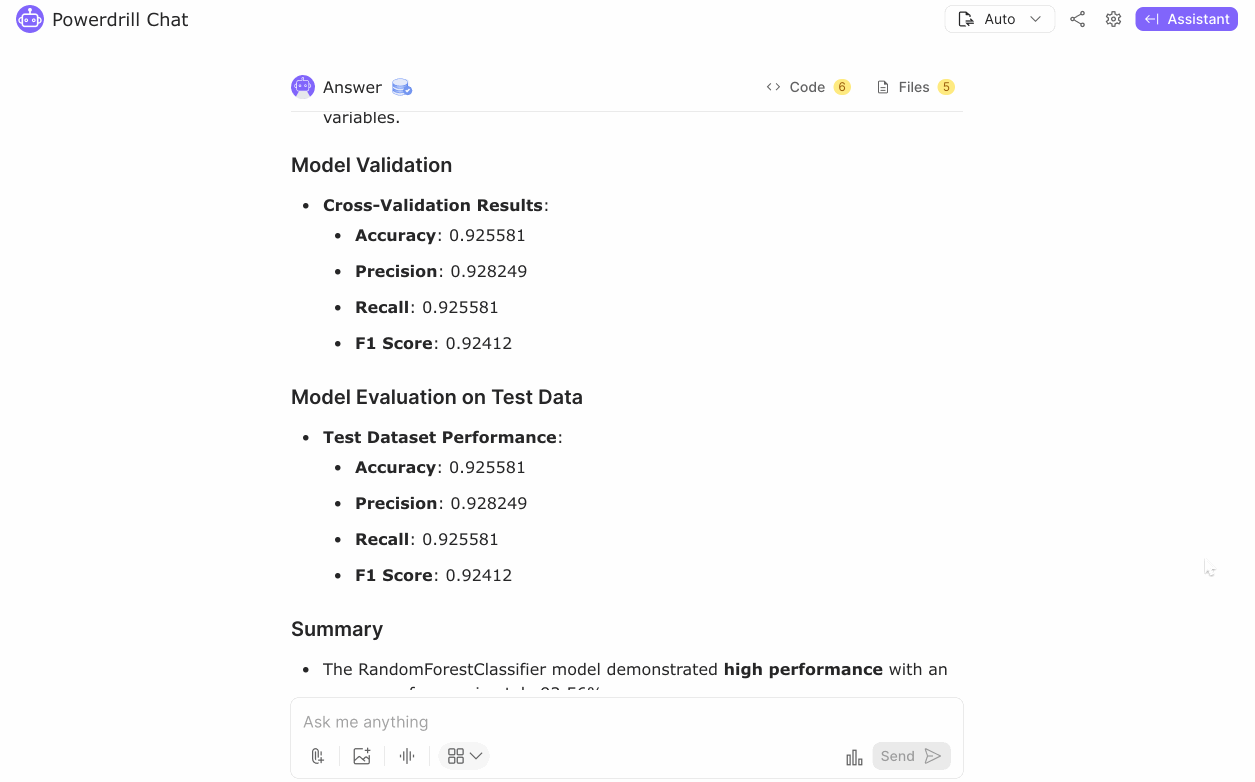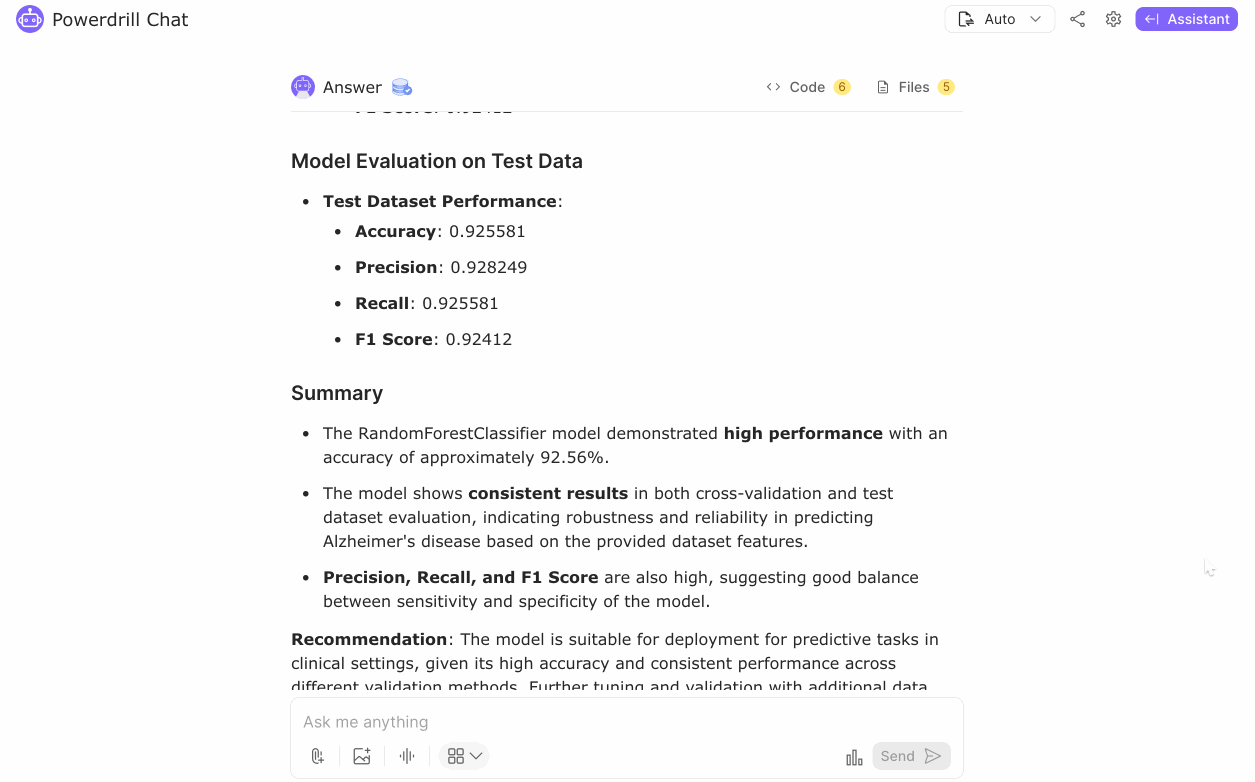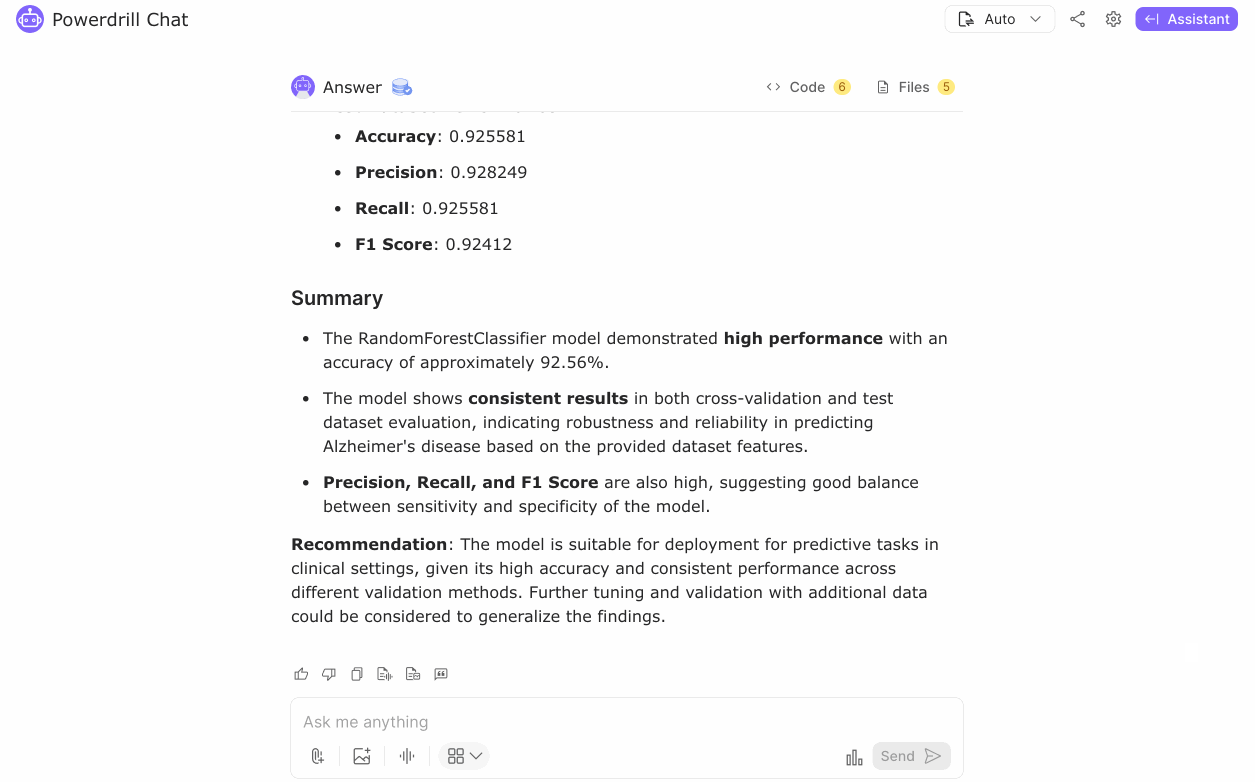
After thoroughly cleaning and preprocessing the Alzheimer's disease dataset, we proceeded to model building and training using the RandomForestClassifier. The dataset, which included comprehensive patient records, clinical measurements, and lifestyle factors, was prepared for predictive analysis by normalizing numerical features and encoding categorical variables.
The RandomForestClassifier model demonstrated high performance, with an accuracy of approximately 92.56%. The model showed consistent results in both cross-validation and test dataset evaluation, indicating robustness and reliability in predicting Alzheimer's disease based on the provided dataset features. The high Precision, Recall, and F1 Score suggest a good balance between the sensitivity and specificity of the model.
The model is suitable for deployment for predictive tasks in clinical settings, given its high accuracy and consistent performance across different validation methods. Further tuning and validation with additional data could be considered to generalize the findings. This model can aid in early diagnosis and identifying high-risk individuals, ultimately contributing to better management and treatment strategies for Alzheimer's disease.
Results Interpretation and Deployment

The results of the Alzheimer's disease analysis reveal several key insights that can inform medical decision-making. The relationship between age and Alzheimer's diagnosis shows mixed results; while one regression coefficient suggests a negative correlation, another indicates no strong relationship. The statistical significance of these findings is questionable, with p-values indicating that further investigation with larger datasets is needed.
Lifestyle factors such as smoking, alcohol consumption, physical activity, and diet quality show slight differences between diagnosed and non-diagnosed groups. Those diagnosed with Alzheimer's tend to engage in less physical activity and have poorer diet quality, though further statistical tests are necessary to confirm these trends. Additionally, diagnosed individuals have higher mean values for cardiovascular disease and hypertension but lower for diabetes, suggesting a potential link that requires more robust analysis to determine significance and causality.
Cognitive and functional assessments, including the MMSE, Functional Assessment, and ADL scores, show clear distinctions between diagnosed and non-diagnosed individuals. Diagnosed patients exhibit lower scores, indicating more severe cognitive and functional impairments. Visualizations, such as scatter plots, support these findings by illustrating the relationships and variabilities within the dataset.
In conclusion, while age remains a factor in Alzheimer's risk assessment, it should be combined with other biomarkers and diagnostic tools due to its questionable statistical significance. Lifestyle modifications and management of comorbid conditions could play a crucial role in prevention strategies. Cognitive and functional assessments should be regularly used for early detection and effective management of Alzheimer's disease. Further research with larger datasets and more comprehensive statistical analyses is recommended to confirm these findings and enhance predictive models, potentially leading to more accurate diagnoses and improved patient care. Integrating multidimensional data into a holistic model could significantly improve diagnostic accuracy and patient management strategies.
Conclusion
The key factors contributing to the progression and diagnosis of Alzheimer's disease were identified through a comprehensive analysis of patient data. We collected and meticulously cleaned detailed patient records, including demographics, clinical measurements, lifestyle factors, and medical history. The dataset consisted of 2149 entries, with no missing values or duplicates, ensuring high data integrity.
Exploratory data analysis revealed that the average patient age is approximately 74.91 years, with a nearly balanced gender distribution. About 35.37% of patients were diagnosed with Alzheimer's.
Interestingly, while the mean age for diagnosed and non-diagnosed groups was similar, diagnosed patients had a slightly higher mean BMI, suggesting a potential association. Behavioral analysis showed a low but consistent occurrence of behavioral issues, with moderate variability. Lifestyle factors such as physical activity and diet quality differed between groups, with diagnosed patients engaging in less physical activity and having poorer diet quality.
Additionally, diagnosed individuals had higher rates of cardiovascular disease and hypertension but lower rates of diabetes, indicating complex comorbidity interactions. Cognitive and functional assessments, including MMSE and ADL scores, clearly differentiated diagnosed patients, with lower scores indicating more severe impairments. Visualizations supported these findings, illustrating key trends and patterns. In conclusion, age, lifestyle factors, comorbid conditions, and cognitive assessments are crucial in understanding Alzheimer's progression.
Further research with larger datasets and robust statistical analyses is recommended to confirm these findings and improve predictive models, enhancing diagnostic accuracy and patient care strategies.
Try Now
Try Powerdrill AI now to uncover critical insights in Alzheimer's disease research efficiently!