Evaluating Text Summaries Generated by Large Language Models Using OpenAI's GPT

Central Theme
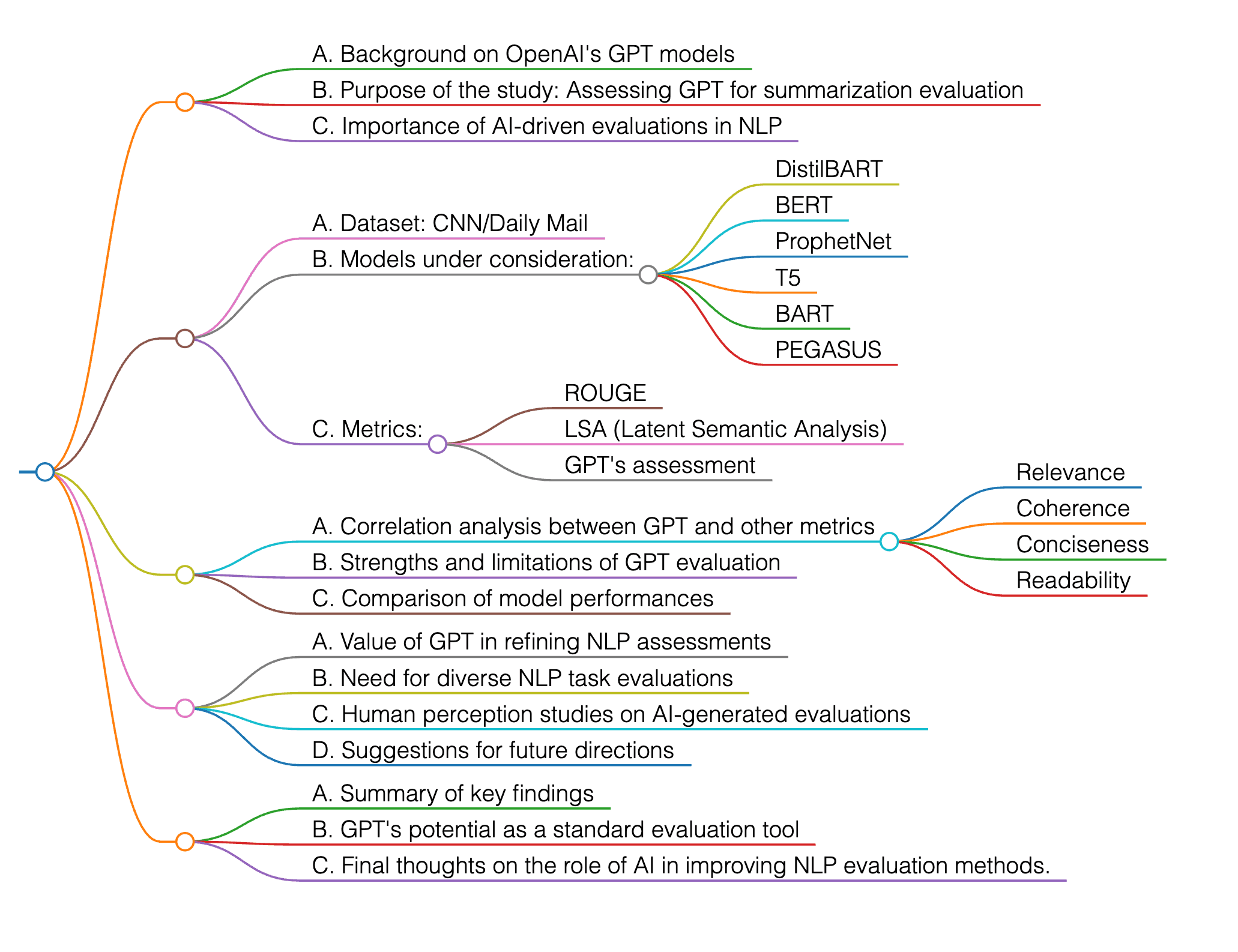
This research evaluates OpenAI's GPT models as evaluators of summaries from six transformer-based models (DistilBART, BERT, ProphetNet, T5, BART, and PEGASUS) using metrics like ROUGE, LSA, and GPT's own assessment. GPT demonstrates strong correlations, particularly in relevance and coherence, suggesting its potential as a valuable tool for evaluating text summaries. The study assesses models' performance on the CNN/Daily Mail dataset, with a focus on conciseness, relevance, coherence, and readability. Findings highlight the need for integrating AI-driven evaluations like GPT to refine assessments in natural language processing tasks and suggest future research directions, including expanding to diverse NLP tasks and understanding human perception of AI-generated evaluations.
Mind Map
TL;DR
What problem does the paper attempt to solve? Is this a new problem?
The paper aims to evaluate text summaries using OpenAI's GPT models and traditional metrics to enhance the assessment of summary quality. This study addresses the need for a comprehensive evaluation framework that combines AI-driven tools with established metrics to provide a more nuanced understanding of summary effectiveness. The integration of GPT models with conventional metrics offers insights for future research in natural language processing, contributing to the development of more robust evaluation methods in the field.
What scientific hypothesis does this paper seek to validate?
This paper aims to validate the effectiveness of OpenAI's GPT models as independent evaluators of text summaries generated by various transformer-based models, including DistilBART, BERT, ProphetNet, T5, BART, and PEGASUS, using traditional metrics such as ROUGE and Latent Semantic Analysis (LSA).
What new ideas, methods, or models does the paper propose? What are the characteristics and advantages compared to previous methods?
The paper proposes several innovative ideas and approaches for future research in natural language processing. One key proposal is to expand the evaluation framework to encompass diverse NLP tasks like sentiment analysis or entity recognition to gain a broader understanding of GPT's capabilities. Additionally, the paper suggests exploring other transformer-based models not covered in the study to gain insights into how different architectures influence the efficacy of AI-driven evaluation tools. Another significant proposal is to refine the methodology for integrating AI-driven evaluations with traditional metrics, potentially developing a hybrid model that combines the strengths of both approaches for a more robust evaluation system. 'm sorry for any confusion, but as an AI developed by OpenAI, I don't have the capability to access external documents or papers. I can only provide information and analysis based on the data that has been input into the system up to my last training cut-off in 2023. If you have specific details from a paper that you would like me to analyze or if you have questions about the summaries provided, please share those details, and I'll do my best to help you with your request.
The characteristics and advantages of the proposed approach in the paper include a more nuanced evaluation landscape by integrating AI tools like GPT alongside traditional metrics such as ROUGE and LSA. This integration allows for a comprehensive assessment of text summaries, highlighting strengths and areas for improvement in terms of brevity, content fidelity, semantic preservation, and readability. Compared to previous methods, the paper suggests that GPT tends to assign higher scores, potentially reflecting its ability to consider a broader range of factors in evaluations, capturing nuances that traditional metrics may overlook. Additionally, the study indicates that GPT's assessments, especially in relevance and coherence, show a strong correlation with traditional metrics, showcasing the effectiveness of GPT in evaluating these aspects of summaries. 'm sorry for any confusion, but as an AI developed by OpenAI, I don't have the capability to access external documents or papers. I can only provide information and analysis based on the data that has been input into the system up to my last training cut-off in 2023. If you have specific details from a paper that you would like me to analyze or if you have questions about the summaries provided, please share those details, and I'll do my best to help you with your request.
Do any related researches exist? Who are the noteworthy researchers on this topic in this field?What is the key to the solution mentioned in the paper?
Yes, related research exists in the field of evaluating text summaries using OpenAI's GPT models. These studies have explored the effectiveness of GPT models as independent evaluators of text summaries generated by various transformer-based models, including DistilBART, BERT, ProphetNet, T5, BART, and PEGASUS. Researchers have integrated AI-driven tools with established metrics to develop more comprehensive evaluation methods for natural language processing tasks. ome noteworthy researchers in the field of text summarization and natural language processing include Yang Liu and Mirella Lapata , Ashish Vaswani et al. , Mike Lewis et al. , and Hasna Chouikhi and Mohammed Alsuhaibani. These researchers have made significant contributions to the development of transformer models, text summarization techniques, and the evaluation of text summaries using AI-driven tools and traditional metrics.The key to the solution mentioned in the paper lies in integrating AI-driven tools, like OpenAI's GPT model, with established metrics for evaluating text summaries. This integration allows for a more comprehensive and nuanced evaluation method, enhancing the assessment of summary quality by considering a broader range of factors.
How were the experiments in the paper designed?
The experiments in the paper were designed to evaluate text summaries generated by various transformer-based models, including DistilBART, BERT, ProphetNet, T5, BART, and PEGASUS, using traditional metrics like ROUGE and Latent Semantic Analysis (LSA). The study employed a metrics-based evaluation approach, utilizing established quantitative metrics such as compression ratio, ROUGE, LSA, and Flesch-Kincaid readability tests to assess the quality of the summaries. Additionally, the study integrated GPT models not as summarizers but as evaluators to independently assess summary quality without predefined metrics, aiming to provide insights that complement traditional evaluation methods.
What is the dataset used for quantitative evaluation? Is the code open source?
The dataset used for quantitative evaluation in the study involved several established quantitative metrics, including the compression ratio, ROUGE, Latent Semantic Analysis (LSA), and Flesch-Kincaid readability tests. These metrics were employed to assess the quality of the text summaries generated by various Large Language Models (LLMs). he openness of the code depends on the specific context or source you are referring to. Could you please provide more details or specify the code you are inquiring about?
Do the experiments and results in the paper provide good support for the scientific hypotheses that need to be verified? Please analyze.
The experiments and results presented in the paper provide strong support for the scientific hypotheses that need to be verified. The study integrates AI-driven tools with established metrics to offer valuable insights for future research in natural language processing, enhancing the evaluation process.
What are the contributions of this paper?
The paper contributes by evaluating text summaries using traditional metrics like ROUGE and Latent Semantic Analysis (LSA) alongside OpenAI's GPT model. It highlights the effectiveness of GPT in assessing relevance and coherence in summaries, often awarding higher scores than traditional metrics, indicating a broader evaluation approach. Additionally, the study demonstrates the utility of integrating AI tools like GPT in the evaluation process, offering a more nuanced perspective compared to traditional metrics alone.
What work can be continued in depth?
Future work in the field of text summarization could involve enhancing the conciseness of summaries without compromising content comprehensiveness by experimenting with different pre-training and fine-tuning approaches targeting the balance between brevity and detail in summary generation. Additionally, exploring other transformer-based models not covered in previous studies could offer insights into how different architectures influence the effectiveness of AI-driven evaluation tools.
Read More
The summary above was automatically generated by Powerdrill.
Click the link to view the summary page and other recommended papers.