A Literature Review and Framework for Human Evaluation of Generative Large Language Models in Healthcare

Central Theme
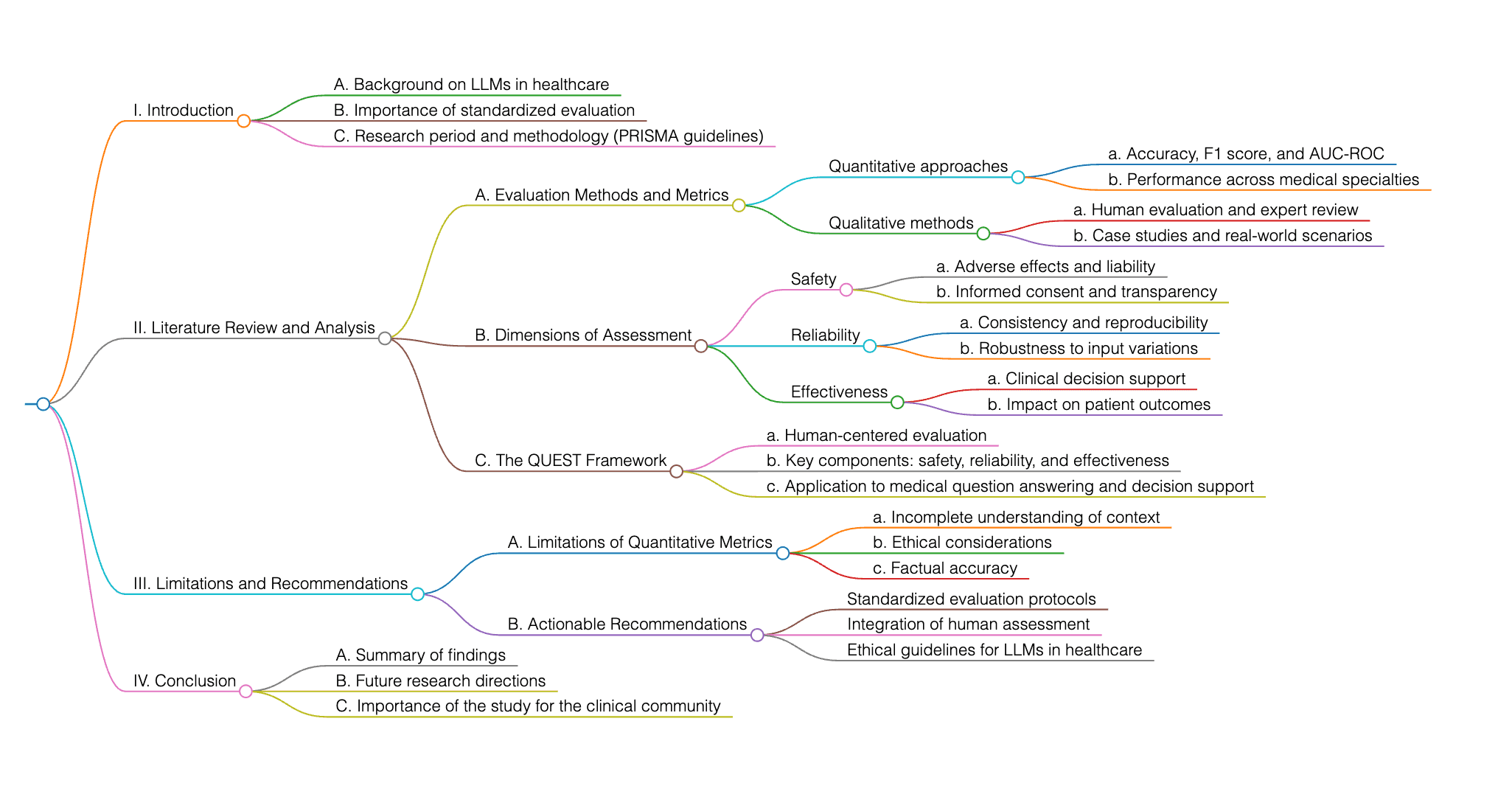
This study examines the evaluation of large language models (LLMs) in healthcare, with a focus on standardized approaches due to the complexity of assessing AI-generated medical content. Researchers conducted a comprehensive review from 2018 to 2024, using PRISMA guidelines, to analyze evaluation methods, metrics, and dimensions across various medical specialties. The proposed QUEST framework highlights the need for human evaluation in ensuring safety, reliability, and effectiveness, particularly in areas like medical question answering and decision support. The study aims to provide a framework for standardized evaluation, address gaps in current research, and offer actionable recommendations for the clinical community to improve LLMs' trustworthiness in healthcare applications. It also discusses the limitations of quantitative metrics and the importance of human assessment in ensuring factual accuracy and ethical considerations.
Mind Map
TL;DR
What problem does the paper attempt to solve? Is this a new problem?
The paper aims to address the limitation of relying solely on quantitative evaluation metrics, like accuracy and F-1 scores, which may not fully validate the accuracy of generated text and may not capture the detailed understanding required for rigorous assessment in clinical practice. It emphasizes the importance of qualitative evaluations by human evaluators as the gold standard to ensure that Language Model outputs meet standards for reliability, factual accuracy, safety, and ethical compliance. o determine if this is a new problem, we need more context or specific information related to the issue you are referring to.
What scientific hypothesis does this paper seek to validate?
This paper aims to validate the hypothesis related to the statistical significance of differences observed between an LLM's performance and a benchmark, which is typically assessed using the P-Value.
What new ideas, methods, or models does the paper propose? What are the characteristics and advantages compared to previous methods?
The paper proposes guidelines for human evaluation of Large Language Models (LLMs) to address challenges in assessing these models, including limitations in scale, sample size, and evaluation measures. Additionally, the study aims to bridge the gap between the promises of LLMs and the requirements in healthcare by proposing a comprehensive framework for human evaluation. 'm happy to help with your question. However, I need more specific information or context about the paper you are referring to in order to provide a detailed analysis. Please provide me with the title of the paper, the author, or a brief summary of the content so I can assist you better.
The proposed human evaluation framework for Large Language Models (LLMs) emphasizes the importance of qualitative assessments by human evaluators, which are considered the gold standard for ensuring reliability, factual accuracy, safety, and ethical compliance in LLM outputs. This approach contrasts with the predominant use of automated metrics in current literature, highlighting the need for a more comprehensive analysis of human evaluation methodologies in healthcare applications. The framework aims to address the limitations of quantitative evaluation metrics by focusing on qualitative assessments, which are essential for rigorous evaluation in clinical practice.
Do any related researches exist? Who are the noteworthy researchers on this topic in this field?What is the key to the solution mentioned in the paper?
Yes, there are several related research studies available in the field. Studies have been conducted to evaluate the performance of language models like ChatGPT in various medical specialties, including diagnostic proposals and clinical determinations. These studies have employed statistical tests like T-tests, Chi-square examinations, and McNemar tests to assess the accuracy and reliability of medical evidence compiled by AI models compared to healthcare practitioners. Additionally, there are discussions on best practices in human evaluation design and monitoring, limitations, and case studies in different medical specialties. Noteworthy researchers in this field include Sinha, R. K., Roy, A. D., Kumar, N., Mondal, H., and Sinha, R. who explored the applicability of ChatGPT in assisting to solve higher order problems in pathology. Additionally, Ayers et al. conducted a study comparing responses from ChatGPT to those supplied by physicians on Reddit's "Ask Doctors" threads, focusing on advice quality and relevance. These researchers have contributed significantly to the evaluation and application of AI models in healthcare settings.The key to the solution mentioned in the paper lies in the development of appropriate evaluation frameworks that align with human values, especially in the context of Language Model (LLM) applications in medicine.
How were the experiments in the paper designed?
The experiments in the paper were designed by comparing responses from ChatGPT to those provided by physicians on Reddit's "Ask Doctors" threads, utilizing chi-square tests to determine differences in advice quality and relevance. The studies also considered testing Language Models (LLMs) in both controlled and real-world scenarios to assess their performance.
What is the dataset used for quantitative evaluation? Is the code open source?
The dataset used for quantitative evaluation in healthcare applications often includes metrics such as accuracy, F-1 scores, and Area Under the Curve of the Receiver Operating Characteristic (AUCROC). These metrics are commonly employed to assess the performance of Language Model Models (LLMs) in various medical contexts, but they may not fully capture the nuanced understanding required for rigorous assessment in clinical practice. he code is not open source, as it is mentioned that open source models like Llama by Meta are not among the top models used in the studies reviewed.
Do the experiments and results in the paper provide good support for the scientific hypotheses that need to be verified? Please analyze.
The research papers present a variety of experiments and results related to language models in healthcare. For example, Tang et al. employed a T-test to compare the correctness of medical evidence compiled by ChatGPT against healthcare practitioners. Additionally, Ayers et al. compared responses from ChatGPT to those supplied by physicians on Reddit's "Ask Doctors" threads using chi-square tests to assess advice quality and relevance. These experiments aimed to evaluate the performance and capabilities of language models in medical contexts.Scientific hypotheses presented in research papers can vary based on the study's focus and objectives. For example, some studies may aim to evaluate the performance of Language Models (LLMs) in specific tasks or scenarios, testing for statistical significance in differences observed. Others may compare LLM responses to those of human experts to assess quality and relevance, utilizing statistical tests like chi-square to identify notable differences. Additionally, research may investigate the reliability and usefulness of LLM-generated responses in various domains, such as scientific research or clinical applications. o provide an accurate analysis, I would need more specific information about the paper, such as the title, authors, research question, methodology, and key findings. This information will help me assess the quality of the experiments and results in relation to the scientific hypotheses being tested. Feel free to provide more details so I can assist you further.
What are the contributions of this paper?
The contributions of this paper include conceptualizing, designing, and organizing the study, analyzing the results, and writing, reviewing, and revising the paper by T.Y.C.T. and S.S.. Additionally, S.K., A.V.S., K.P., K.R.M., H.O., and X.W. contributed by analyzing the results, and writing, reviewing, and revising the paper. Moreover, S.V., S.F., P.M., G.C., C.S., and Y.P. were involved in writing, reviewing, and revising the paper.
What work can be continued in depth?
Further in-depth work can be conducted in various areas such as exploring human evaluation dimensions across different medical specialties, discussing best practices in designing and monitoring human evaluations, addressing limitations and methods to overcome them, and providing case studies in various medical tasks and specialties.
Read More
The summary above was automatically generated by Powerdrill.
Click the link to view the summary page and other recommended papers.