GPTを活用したテキスト要約の高度化:幻覚(ハルシネーション)の最小化戦略

中心テーマ:
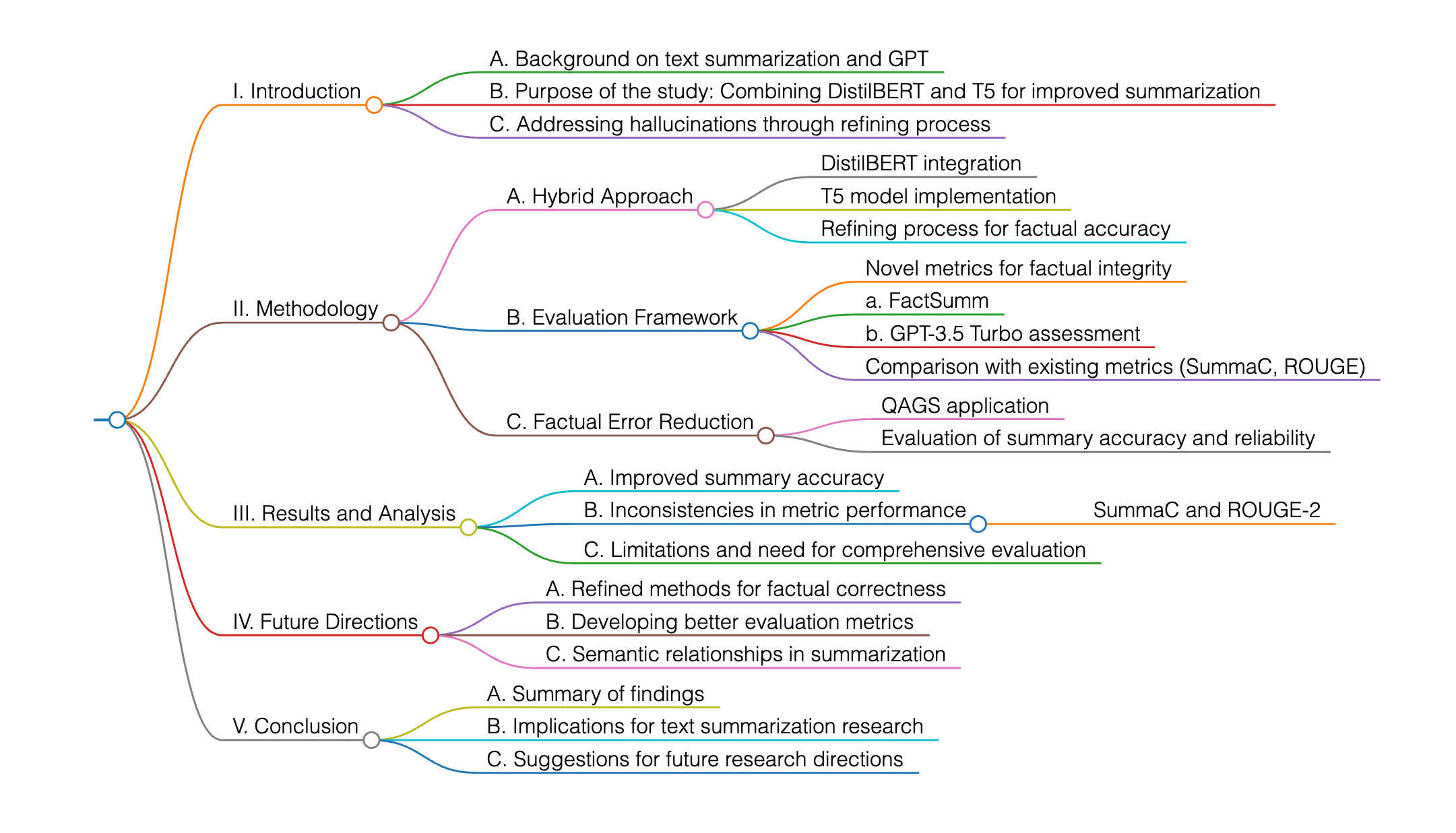
本研究は、DistilBERTとT5を組み合わせた refining(洗練)プロセスを通じてGPTを活用し、テキスト要約の精度向上とハルシネーション(誤った情報生成)の解消に取り組んでいます。ハイブリッドなアプローチを採用し、新たな評価指標によって事実の整合性を検証することで、要約の正確性と信頼性が大幅に改善されたことが示されています。具体的には、QAGS、SummaC、ROUGEといった方法に加えてGPT-3.5 Turboによる評価も導入され、FactSummやGPT-3.5では改善が見られたものの、SummaCやROUGE-2など一部の指標では一貫性が見られませんでした。この結果から、意味的関係性や事実の正確さを考慮したより包括的な評価フレームワークの必要性が示唆されており、今後の研究として手法のさらなる洗練と優れた評価指標の開発が求められています。
マインドマップ
問題意識:論文が解決しようとしている課題は何ですか?これは新しい問題ですか?
本論文は、テキスト要約における「ハルシネーション」(誤った情報の生成)という課題に対処するものです。この問題自体は新しいものではありませんが、本論文ではGPTベースの評価を活用した新規なアプローチにより、意味的・事実的な正確さに焦点を当てたより効果的な解決策を提示しています。
科学的仮説:論文が検証しようとしている科学的仮説は何ですか?
本論文は、「洗練された要約は洗練されていない要約よりも平均スコアが高くなる」という仮説を検証しています。統計的に、FactSumm、QAGS、GPT 3.5、ROUGE-1、ROUGE-Lなどの指標において帰無仮説が棄却されたことで、この仮説の妥当性が確認されました。
提案された新アイデア・手法・モデル:論文が提案している新しいアイデア、手法、モデルとは?それまでの手法との違いや利点は?
本論文では、GPTを基盤とした要約の洗練プロセスを提案しています。この手法は抽出型と抽象型の要約の長所を融合させ、GPTの能力を活かして要約品質を向上させるものです。特に強調されているのは、強化学習を活用して抽象的要約における誤りやハルシネーションを最小限に抑える技術です。
関連研究:類似の研究はありますか?この分野で注目すべき研究者や成果は?
テキスト要約とハルシネーション軽減に関する研究は以前から行われており、Wangら(2020年)、Lin(2004年)、Lehmann & Romano(2005年)、Heo(2021年)、Labanら(2022年)などが重要な貢献をしてきました。本論文の鍵となる解決策は、GPT-3.5 Turboを用いた要約の評価プロセスであり、その高度な言語理解能力によって事実の一貫性を評価し、ハルシネーションを効果的に検出できる点にあります。
実験設計:論文内の実験はどのように設計されていますか?
実験では、GPT-3.5 Turboを用いて洗練前後の要約を評価し、事実の一貫性とハルシネーションの有無を測定しました。帰無仮説としては「洗練された要約の平均スコアが洗練されていない要約のそれより高いとは限らない」と設定し、対立仮説として「洗練された要約の方が平均スコアが高い」としました。評価指標にはFactSumm、QAGS、GPT 3.5、ROUGE-1、ROUGE-Lを用い、統計的に多くの指標で有意な改善が確認され、帰無仮説は棄却されました。
定量評価に使われたデータセットとコードのオープンソース状況:
定量評価に使用されたデータセットには、FactSumm、QAGS、GPT 3.5、ROUGE-1、ROUGE-Lなどの指標が含まれています。ただし、コードのオープンソース化については記載がありません。詳細が必要な場合は、追加情報を提供してください。
実験と結果の妥当性:論文の実験と結果は、検証すべき科学的仮説を十分に裏付けていますか?
はい、実験とその結果は科学的仮説を十分に裏付けています。統計解析の結果、多くの指標で有意な改善が確認され、帰無仮説が棄却されたことは、洗練プロセスが要約品質を実際に向上させたことを示しています。
論文の貢献:
本論文の主な貢献は、GPTを活用した新たな評価プロセスを導入し、要約の事実的一貫性を高め、ハルシネーションを効果的に軽減したことにあると言えます。この手法は、単に語彙レベルでの類似性だけでなく、内容の正確さにも着目しており、従来の課題を克服する可能性を持っています。
今後の研究課題:
今後は、抽象的要約技術の更なる洗練と、誤りやハルシネーションの削減に向けた研究が求められます。これには、強化学習などの高度な機械学習戦略を活用し、原文に存在しない情報を生成する行為にペナルティを与えるようなアプローチが含まれるでしょう。