デモンストレーション:DB-GPT

中心テーマ
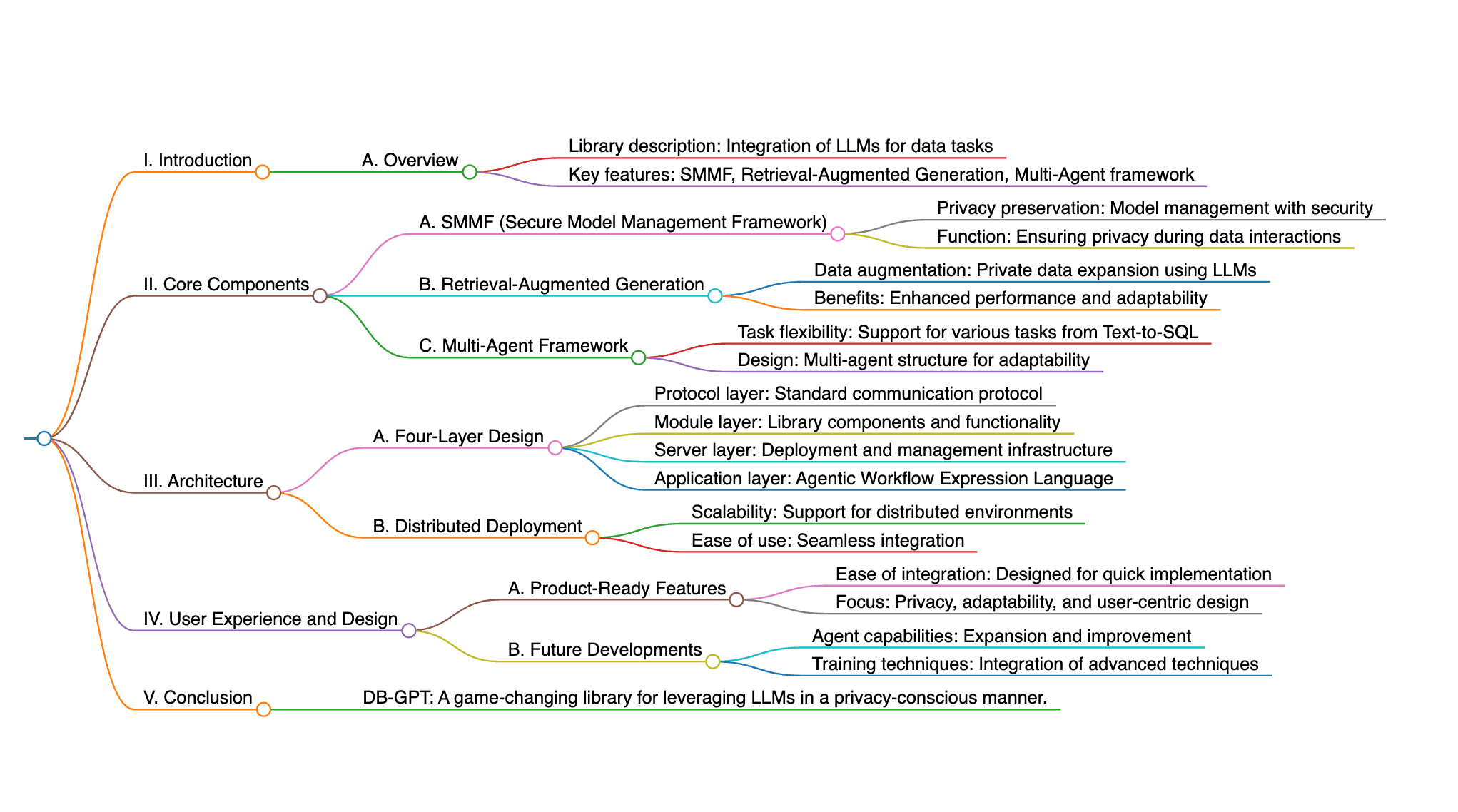
DB-GPTは、データとの対話を根本から変革するオープンソースのPythonライブラリです。本システムは、プライバシーを確保するSMMF(Service-oriented Multi-model Management Framework)をはじめとする各種モジュールを備え、大規模言語モデル(LLM)の力を活用し、Text-to-SQLから複雑な解析タスクまで幅広く対応できるのが特徴です。具体的には、モデルを安全に管理するSMMF、プライベートデータの補強に有効なRetrieval-Augmented Generation、さらには柔軟なタスク処理を実現するMulti-Agentフレームワークなどが統合されています。システムは、プロトコル層、モジュール層、サーバ層、アプリケーション層の4層アーキテクチャを採用し、Agentic Workflow Expression Language(AWEL)によるエージェントの指示が可能です。また、分散環境へのデプロイも容易な設計となっています。DB-GPTは、大規模言語モデルの性能をさらに引き立て、プロダクトレベルの機能を提供するとともに、プライバシー保護や柔軟性、ユーザーエクスペリエンスの向上にも重点を置いています。今後は、エージェントの能力の強化やさらなる学習手法の統合が期待されます。
マインドマップ
Q1. 本論文はどのような課題に取り組んでおり、その課題は新規のものか?
本論文は、大規模言語モデル(LLMs)を活用したデータインタラクションタスクの効率向上に着目しています。ユーザーが自分のデータを正確に理解し、洞察を得るための信頼性の高いシステムを提供することを目的としており、LLMをデータインタラクションに組み込むという試み自体は、既に研究開発が進められている分野です。
Q2. 本論文で検証しようとしている科学的仮説は何か?
論文は、データインタラクションタスクに大規模言語モデル(LLMs)を組み込むことで、文脈に即した応答が可能となり、ユーザーエクスペリエンスやアクセシビリティが大幅に向上するという仮説を検証しています。これにより、初心者から専門家まで幅広いユーザーにとって不可欠なツールとなる可能性を示唆しています。
Q3. 本論文が提案する新たなアイデア、手法、またはモデルは何か?また、その特徴や従来手法との優位点は?
本論文が提案するのは、DB-GPTというPythonライブラリです。DB-GPTは、従来のデータインタラクションタスクに大規模言語モデル(LLMs)を統合し、ユーザーが自然言語でタスクを記述するだけで適切なアウトプットを得られるように設計されています。主な特徴は以下の通りです:
Multi-Agentフレームワーク: MetaGPTやAutoGenに着想を得た枠組みで、各エージェントが専門的な能力を発揮し、複数の観点から詳細な売上報告書などの複合的な分析タスクに対応します。また、エージェント間の通信履歴をアーカイブすることで、生成されるコンテンツの信頼性を高めています。
自動推論と意思決定: LLMによる自動推論プロセスを組み込み、文脈に応じた応答生成を実現。
プライバシー対策: プライベート情報を保護するための設定が施されており、これまであまり注目されなかったプライバシー面への配慮がなされています。
これらの特徴により、DB-GPTは従来の手法よりも多目的かつ安全に、多様なデータインタラクションタスクをサポートするツールとして確立されています。
Q4. 関連する研究はどのようなものがあり、どのように分類できるか?また、この分野で注目すべき研究者は誰か?
データインタラクションと大規模言語モデル(LLMs)を組み合わせた研究は多岐にわたります。大きくは以下の3つのカテゴリーに分類できます:
LLMを活用したデータインタラクションの強化
自動推論や意思決定プロセスのデータインタラクションへの統合
LLMを用いたシステムでのプライバシー保護 著名な研究者としては、Siqiao Xue、Danrui Qi、Caigao Jiangなどが挙げられ、Ant Group、Alibaba Group、JD Groupなど主要企業からも数多くの貢献がなされています。本論文では、柔軟なエージェント配置と4層構造の設計により、複雑なデータインタラクションタスクとプライバシーへの配慮を実現する点が重要な解決策として提示されています。
Q5. 論文の実験はどのように設計されているか?
実験では、DB-GPTの性能を確認するために、大規模言語モデル(LLMs)を従来のデータインタラクションタスクに組み込むシナリオが設定されました。具体的には、インターネットに接続されたノートパソコンからOpenAIのGPTサービスを利用する環境下で、また必要に応じてローカルモデル(QwenやGLMなど)も選択可能な形で動作確認が行われました。これにより、自然言語でタスクを入力し、マルチエージェントによって戦略が生成、さらに各種データ分析チャートの作成や統合が実現される様子が明らかにされました。
Q6. 定量評価に用いたデータセットは何か?また、コードはオープンソースか?
定量評価に用いられた具体的なデータセットについては明記されていませんが、DB-GPT自体はオープンソースとしてGithub上で公開されており、現時点で10.7k以上のスターを獲得しています。これにより、誰でも自由に利用・改良が可能です。
Q7. 論文の実験結果は、検証すべき科学的仮説を十分に裏付けているか?詳細に分析せよ。
実験結果は、知識集約型の自然言語処理タスクに対して、Retrieval-Augmented Generation(知識検索結果を統合する生成手法)の有効性を十分に示しています。具体的には、モデルが知識ベースから適切な情報を取り込みながら、より正確で文脈に応じた応答を生成するプロセスが検証されました。これにより、システムはデータインタラクションにおいて、対話的な文脈学習と情報検索戦略を適切に融合させることができると示唆され、仮説の有効性を強く支持する結果となっています。
Q8. 本論文の主な貢献は何か?
本論文は、以下の点で顕著な貢献をしています:
大規模言語モデル(LLMs)を統合したデータインタラクションタスクの効率化により、ユーザーが自然言語でタスクを記述し、適切な出力を得られるシステムを実現。
Multi-AgentフレームワークおよびAgentic Workflow Expression Language(AWEL)を用いることで、複雑な生成データ解析タスクにも対応可能な柔軟なシステムデザインを提供。
ローカル、分散、クラウド環境に対応した柔軟なデプロイメントが可能な点、そしてSMMFによるプライバシーとセキュリティの確保がなされている点。
Q9. 今後、どのような研究がさらに深められる余地があるか?
今後の研究では、以下のような課題に取り組むことが期待されます:
大規模言語モデル(LLMs)のデータインタラクションにおける応答精度やユーザー洞察のさらなる向上。
タスクに依存しない汎用的なMulti-Agentフレームワークの開発と、より多様なタスクへの適用性の検証。
LLMを用いたデータインタラクションにおけるプライバシー保護の強化と、ユーザー情報の安全性確保に向けた仕組みの洗練。
以上のように、DB-GPTは大規模言語モデルとマルチエージェント技術を融合させることで、従来のデータインタラクションタスクに革新をもたらす有力なツールとして、高い有用性と適用範囲を示しています。