Attention Modulationによるテキストからの画像生成アライメントの向上に向けて

中心テーマ
本論文では、拡散モデルを用いたテキストからの画像生成における課題、特に「エンティティのリーク(entity leakage)」と「属性の不整合(attribute misalignment)」に焦点を当て、これらを解決するためのトレーニング不要なアテンション変調メカニズムを提案する。この手法は、自己注意(self-attention)の温度制御、オブジェクトに焦点を当てた交差注意(cross-attention)マスキング、そして生成のフェーズに応じた動的な重み付け再設定を組み合わせたものである。このアプローチにより、大規模なラベル付きデータを必要とせずにアライメント(テキストと画像の一致度)が強化され、複雑なプロンプトに対しても画像とテキストの整合性が向上し、より質の高い画像生成が可能となる。実験では、複数のエンティティや属性の扱いに優れ、既存モデルより計算コストを削減しつつ、最先端の性能を達成することが示されている。
マインドマップ
Q1. 本論文が解決しようとしている問題は何か?それは新しい問題か?
本論文は、テキストからの画像合成タスクにおける「エンティティのリーク」と「属性の不整合」という問題の解決を目指しています。これらの問題は全く新しいものではありませんが、この分野で根強く残る課題です。
Q2. 本論文が検証しようとしている科学的仮説は何か?
本論文は、「トレーニング不要で、生成のフェーズに応じたアテンション制御メカニズムを導入することで、テキストからの画像生成タスクにおけるエンティティのリークと属性の不整合の問題を効果的に解決できる」という仮説の検証を試みています。
Q3. 本論文ではどのような新しいアイデア、手法、モデルが提案されているか?従来の手法と比較した特徴と利点は何か?
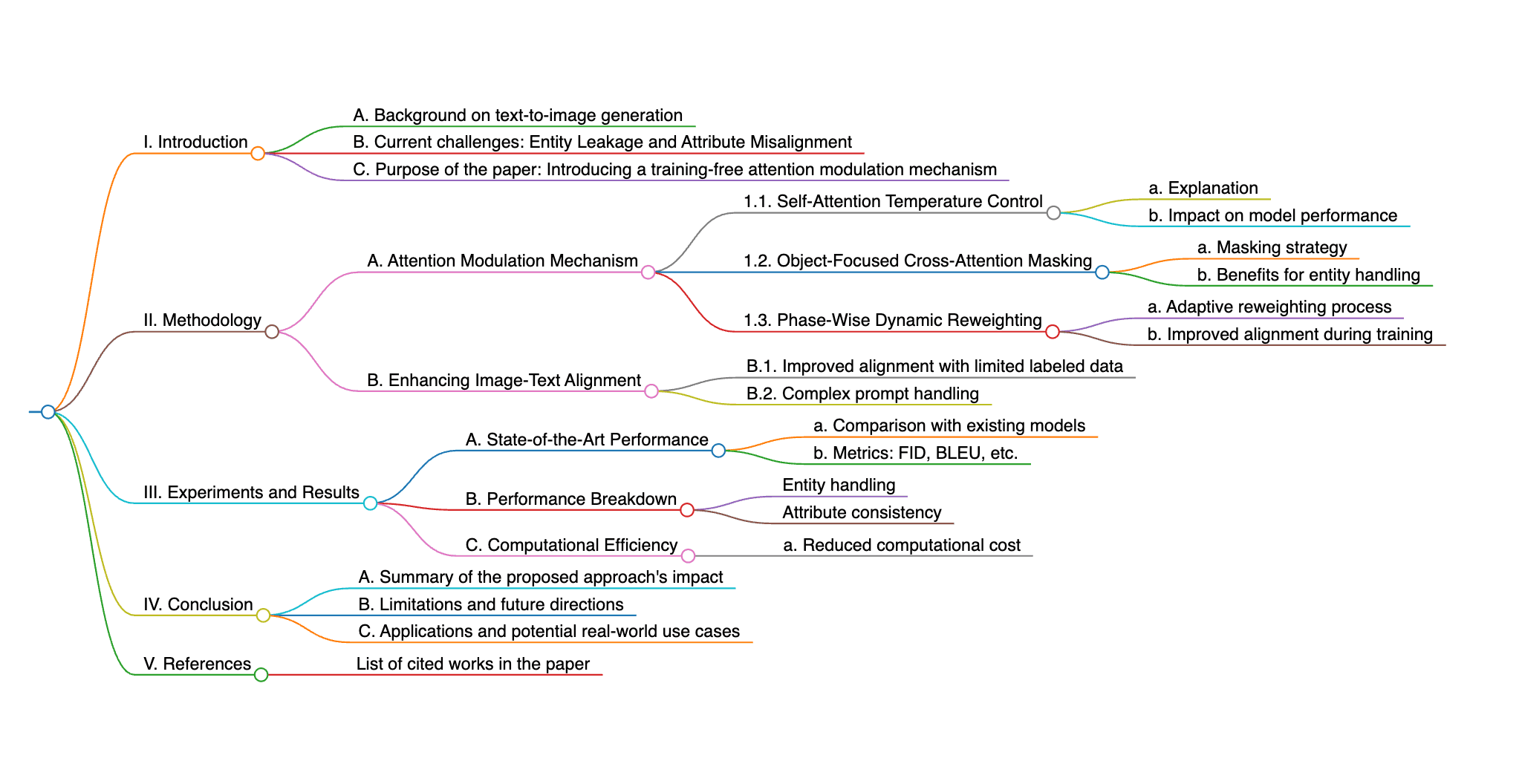
本論文では、テキストからの画像生成タスクにおける課題に対処するため、トレーニング不要でフェーズに応じたアテンション制御パラダイムを通じた「属性フォーカシングメカニズム」を提案しています。このメカニズムは、以下の主要な要素で構成されています。
エンティティのリーク問題を緩和するための、自己注意(self-attention)モジュールにおける温度制御メカニズム。
エンティティ間の意味情報を効果的に識別するための、交差注意(cross-attention)モジュールにおけるオブジェクト焦点マスキング手法。
画像とテキストのアライメントを向上させるための、フェーズに応じた動的重み制御メカニズム。
さらに、本論文は自己注意の温度制御、オブジェクト焦点の交差注意マスク、そしてフェーズに応じた動的重み付け戦略を組み合わせることで、エンティティのリークと属性の不整合を軽減する新たなアプローチを導入しています。これらの手法は、モデルが特定の意味的要素に集中する能力を高め、属性の不整合を減らし、追加の計算コストを最小限に抑えながら画像とテキストの全体的なアライメントを向上させることを目的としています。
従来手法と比較して、本論文が提案する手法にはいくつかの主要な特徴と利点があります。まず、提案された属性フォーカシングメカニズムは、エンティティのリークに対処する自己注意の温度制御、エンティティ間の意味情報を識別するオブジェクト焦点マスキング、そして画像とテキストのアライメントを改善する動的重み制御を統合しています。これらの要素が相乗的に機能することで、モデルは特定の意味的要素に集中する能力を高め、属性の不整合を低減し、最小限の追加計算コストでより良いアライメントを達成します。
さらに、本論文のアプローチは、異なる傾向を持つ曲線によって制御されるマスクに異なる重みを割り当てる動的な重み付け手法を統合しており、モデルのアテンション制御能力を一層強化します。これらのメカニズムを組み合わせることで、モデルはエンティティと画像の背景を効果的に区別し、生成される画像の全体的な品質を向上させることができます。従来手法と比較して、本論文のアプローチは、複数のエンティティと属性を含む複雑なプロンプトのシナリオで優れた性能を発揮します。
具体的には、複数のオブジェクトと属性のペアを含むプロンプトにおいて、本モデルはStructured Diffusionを上回る性能を示します。これは、オブジェクト焦点マスキング手法とフェーズに応じた動的重み制御メカニズムにより、意味情報の帰属をより良く確保し、属性の不整合を低減できるためです。これらの改善は、モデルが特定の意味的要素により良く焦点を合わせ、より正確な画像とテキストのアライメントを達成することを可能にします。
総じて、本論文で提案された手法は、テキストからの画像生成タスクにおけるエンティティのリークや属性の不整合といった課題に対する包括的な解決策を提供します。革新的なアテンション制御メカニズムと動的な重み付け戦略を組み込むことにより、モデルはより良い画像とテキストのアライメントを達成し、忠実度と精度の高い高品質な画像を生成します。
Q4. 関連研究は存在するか?この分野で注目すべき研究者は誰か?論文で言及されている解決策の鍵は何か?
テキストからの画像生成の分野には、いくつかの関連研究が存在します。この分野で注目すべき研究者としては、テキストからの画像生成における人間の好みを評価するためのImageRewardを導入したXuらが挙げられます。また、Fengらは構成的なT2I(Text-to-Image)生成に焦点を当てたStructured Diffusionを提案しました。もう一つの重要な研究は、より良い画像とテキストのアライメントを実現するための属性フォーカシングメカニズムを開発したYihang Wuらによるものです。本論文で言及されている解決策の鍵は、トレーニング不要でフェーズに応じたアテンション制御メカニズムにあります。このメカニズムは、自己注意モジュールでの温度制御を統合してエンティティのリーク問題を緩和し、交差注意モジュールにオブジェクト焦点マスキング手法とフェーズに応じた動的重み制御を組み込むことで、エンティティ間の意味情報の識別を強化します。
Q5. 論文の実験はどのように設計されたか?
本論文の実験は、追加の計算コストを最小限に抑えつつ、様々なアライメントシナリオにおいて提案モデルの性能を検証するように設計されています。この実験は、フェーズに応じた動的重み制御メカニズムとオブジェクト焦点マスキング手法を交差注意モジュールに組み込むことにより、テキストからの画像生成タスクにおけるエンティティのリークと属性の不整合に関連する課題に対処することを目的としていました。これらの実験により、モデルがエンティティ間の意味情報の帰属をより効果的に識別し、より優れた画像とテキストのアライメントを達成したことが実証されました。
Q6. 定量的評価に用いたデータセットは何か?コードはオープンソースか?
定量的評価に使用されたデータセットはCOCO検証セットであり、評価指標にはFID、CLIP Score、ImageReward Scoreが含まれます。コードについては、利用可能な文脈においてオープンソースであるかどうかの情報は提供されていません。コードとその公開状況に関する詳細については、研究に関連する特定の出版物やプロジェクトを参照する必要があるかもしれません。
Q7. 論文の実験と結果は、検証が必要な科学的仮説を十分に裏付けているか?
はい、本論文で示された実験と結果は、検証されるべき科学的仮説を強力に裏付けています。提案されたトレーニング不要でフェーズに応じたアテンション制御パラダイムは、テキストからの画像生成タスクにおけるエンティティのリークと属性の不整合の問題に効果的に対処しています。自己注意の温度制御、オブジェクト焦点マスキング、およびフェーズに応じた動的重み付け戦略の実装を通じて、モデルは最小限の追加計算コストで画像とテキストのアライメントが改善されることを示しました。手法の主要な構成要素に関するアブレーションスタディ(要素別比較検証)は、自己注意制御戦略とオブジェクト焦点マスクがFIDやCLIP Scoreなどの性能指標を向上させる上で有効であることをさらに検証しています。結果は、これらの要素を統合することで、個々の戦略よりも堅牢なパフォーマンスにつながることを示唆しています。
Q8. この論文の貢献は何か?
本論文は、テキストからの画像生成タスクにおけるエンティティのリークと属性の不整合の問題に対処するため、トレーニング不要でフェーズに応じたアテンション制御パラダイムを提案しています。貢献点としては、エンティティのリーク問題を緩和するための自己注意の温度制御メカニズムの実装、そしてエンティティ間の意味情報の帰属を強化するためのオブジェクト焦点マスキング手法とフェーズに応じた動的重み制御メカニズムの交差注意モジュールへの導入が挙げられます。さらに、生成プロセス中にプロンプトの異なる意味的要素への重点を変化させることで属性のアライメントを改善する、フェーズに応じた動的重み付け戦略も導入しています。
Q9. 今後、どのような研究が期待されるか?
この分野における今後の研究としては、テキストからの画像生成タスクにおけるアテンション制御をさらに強化するために、オブジェクト焦点マスキングメカニズムを改良することが考えられます。加えて、様々な段階でプロンプトの異なる構成要素に優先順位を付けるための動的な重み付けメカニズムを探求することも、より深い研究の道筋となるでしょう。
このコンテンツはPowerdrillによって生成されました。要約ページで全文をご覧いただけます。
論文全文へのリンクはこちらです。
powerdrill.aiにログインして、テキストからの画像生成を体験してください。