Excelからのデータレポート作成をAIツールで自動化する方法

はじめに
Excelからデータレポートを手作業で作成するのは、非常に手間と時間がかかり、フラストレーションのたまる作業です。多くの場合、大量のデータセットを処理し、反復的な計算を行い、表やグラフを細部まで注意深くフォーマットする必要があります。これらの作業は単調であるだけでなく、人的ミスを招きやすく、意思決定に悪影響を与える可能性もあります。
AIの進歩により、データレポート作成は大きく変革され、ユーザーは手作業ではなく、洞察を得ることに集中できるようになりました。このガイドでは、PowerdrillがいかにワンクリックでExcelファイルからのデータレポート作成を簡素化するかを探ります。
データレポートの自動化を理解する
データレポートの自動化とは?
データレポートの自動化とは、人工知能(AI)や機械学習などの先進技術を活用し、生データから構造化された洞察に満ちたレポートを作成するプロセスを効率化することを指します。手作業による計算や書式設定に大きく依存していた従来のレポート作成方法とは異なり、自動化は組織に以下のことを可能にします。
時間短縮: レポートを数分で生成し、手作業にかかる時間を削減します。
精度向上: 計算やデータ解釈における人的ミスのリスクを最小限に抑えます。
一貫性の確保: レポートの構造と形式に統一性を保ちます。
洞察の獲得: AIを活用して、見過ごされがちな傾向、パターン、異常を発見します。
自然言語処理と機械学習を統合することで、自動レポート作成ツールは複雑なデータセットを解釈し、最適な視覚化を推奨し、特定のニーズに合わせてレポートをカスタマイズすることもできます。これにより、効率と意思決定の改善を目指す企業にとって、かけがえのない資産となります。
人気のデータレポート自動化ツール
Powerdrill: 包括的なAI駆動型データ分析およびレポート機能を提供します。
Tableau: 対話型ビジュアライゼーションに焦点を当てていますが、手動での設定が必要です。
Microsoft Power BI: 強力なレポート機能を提供しますが、自動化には学習曲線がある場合があります。
Powerdrillでデータレポートを自動化するためのステップバイステップガイド
すべての情報が誰でも閲覧できるように、WorldBankの公開データセットを使用します。データセットは以下のリンクからダウンロードできます: https://datacatalog.worldbank.org/search/dataset/0038015?version=10
または、ディスカバーチャンネルを訪れるだけで、テストプロセスを効率化できます。この方法を選択する場合、以下の手順を実行する必要はなく、「データレポートを生成」ボタンをクリックするだけです。
ステップ1. Excelデータをアップロードする
Powerdrillにサインインした後、AIデータレポートジェネレーターエージェントを見つけ、「始める」をクリックして、Excelファイルをアップロードします。
一度に最大10個のExcel/CSV/TSVファイルをアップロードできます。このデータセットの例では、5つのファイルをアップロードします。
ステップ2. レポートの完了を待つ
1〜2分お待ちください。データレポートの準備が整います。

よくある質問と追加リソース
よくある質問
Powerdrillを複数のファイルで使用できますか? はい、Powerdrillは最大10個のExcel/CSV/TSVファイルを同時にアップロードすることをサポートしています。
どのような種類の洞察を生成できますか? Powerdrillは、データセットに合わせてトレンド、分布、主要な指標に関する洞察を提供します。
このツールは非技術系ユーザーに適していますか? もちろんです!Powerdrillの直感的なインターフェースとAIによる自動化は、誰にとっても使いやすいです。
関連情報
AIを使ってExcelデータを分析する方法(たった2ステップで): このブログでは、AIを使ってExcelファイルのデータを理解し、分析し、視覚化する方法をたった2ステップで説明しています。
Powerdrill AIでデータをクリーンアップする方法: Powerdrillは、データクリーニングを高速で手間のかからない、正確なプロセスに変え、Excelユーザーから非技術系の初心者まで、誰でもアクセスできるようにします。
最後に
PowerdrillのAI駆動型機能は、生データを実用的な洞察へ楽々変換することを可能にします。データレポートを自動化することで、手作業をなくし、エラーを減らし、意思決定に集中できます。今日からPowerdrillを使い始め、データレポートの扱い方を革新しましょう!
レポートの詳細に興味がある場合は、以下の添付ファイルをご覧ください。
添付: 国際債務と経済指標の包括的概要
以下は、レポートから要約された内容です。
IDS_Country-SeriesMetaData.csvデータセットにおいて、各国コードに最もよく関連するシリーズコードは何ですか?
シリーズコードの分析
データグループ化: データセットは「国コード」と「シリーズコード」でグループ化され、出現回数がカウントされました。
最も一般的なシリーズ: 各国コードについて、最も頻繁なシリーズコードが特定されました。
視覚化による洞察
棒グラフ表現: 棒グラフは、各国におけるシリーズコードの頻度を視覚化します。
支配的なシリーズコード: このグラフは、異なる国々で最も一般的なシリーズコードを強調しています。
結論と洞察
共通シリーズコード: 「人口、合計 (Population, total)」がすべての国で最も一般的なシリーズコードです。
主要指標: 人口データは、データセット全体で一貫して収集されている主要な指標であり、世界のデータ収集努力におけるその重要性を示しています。
IDS_CountryMetaData_table_0.csvデータセットにおいて、所得グループの分布は地域間でどのように異なりますか?
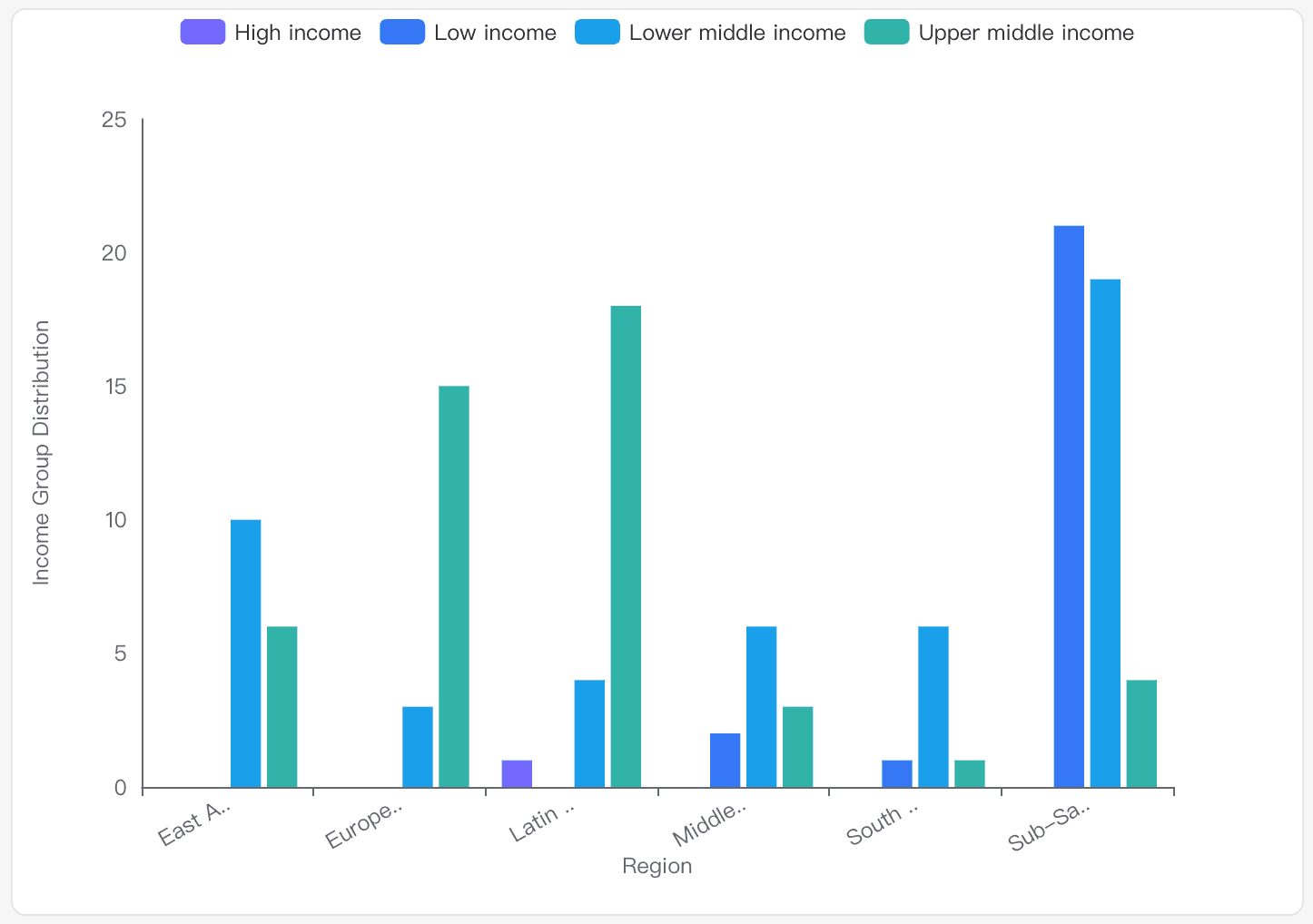
概要
低所得: 主にサハラ以南アフリカと南アジアに集中しています。このグループはサハラ以南アフリカで21件と最も多くを占めます。
低中所得: すべての地域に広がっており、南アジア、サハラ以南アフリカ、東アジア・太平洋でかなりの割合を占めます。
高中所得: ヨーロッパ・中央アジア、ラテンアメリカ・カリブ海、東アジア・太平洋で一般的です。
高所得: 最も数が少なく、主にラテンアメリカ・カリブ海で出現します。
視覚的表現
棒グラフは分布を示しており、サハラ以南アフリカのような地域での低所得グループの優勢と、ヨーロッパ・中央アジアでの高中所得の普及を強調しています。
詳細分析
南アジア: 主に低中所得国です。
ヨーロッパ・中央アジア: 主に高中所得国です。
中東・北アフリカ: 低所得と高中所得が混在しています。
サハラ以南アフリカ: 低所得国の集中度が高いです。
東アジア・太平洋: 低所得と高中所得が混在しています。
ラテンアメリカ・カリブ海: ほとんどが高中所得国で、一部高所得国もあります。
結論と洞察
地域差: 所得グループの分布は地域によって大きく異なり、特定の地域では特定の所得グループの集中度が高いです。
経済多様性: データセットは経済的多様性を反映しており、サハラ以南アフリカのような地域にはより多くの低所得国があり、ヨーロッパ・中央アジアやラテンアメリカ・カリブ海にはより多くの高中所得国があります。
各国の「最新の人口センサス」と「最新の貿易データ」のタイミングに影響を与える可能性のある要因を分析してください。これらの要因は、これら2つの変数の相関関係にどのように影響する可能性がありますか?
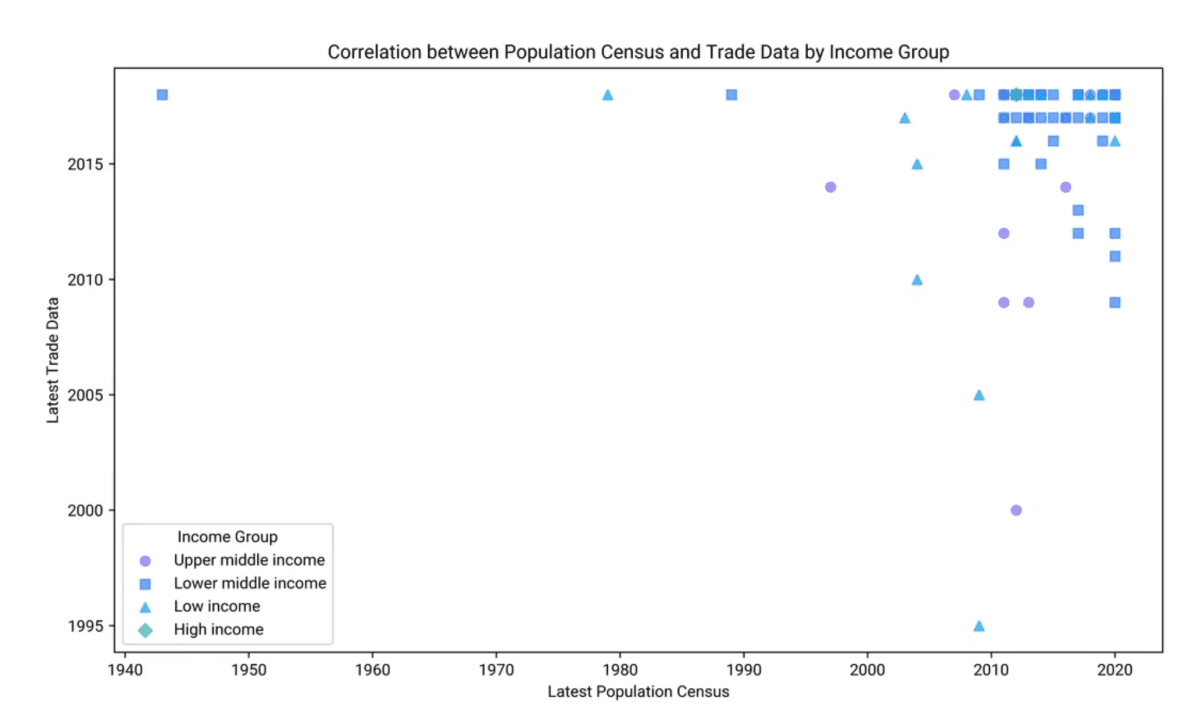
最新の人口センサスのタイミングに影響を与える要因
経済的資源: 資源の豊富な国はより頻繁にセンサスを実施できますが、資源の少ない国は不定期なスケジュールに直面する可能性があります。
政治的安定性: 安定は定期的なセンサスを可能にしますが、紛争は遅延を引き起こす可能性があります。
技術的能力: 高度な技術は、より効率的で頻繁なセンサスを可能にします。
政策とガバナンス: 政府の優先順位がセンサスの定期性を決定する可能性があります。
国際支援: 組織からのガイドラインや支援は、特に開発途上国におけるタイミングに影響を与える可能性があります。
最新の貿易データのタイミングに影響を与える要因
経済活動: 高い貿易活動は、頻繁なデータ更新を必要とします。
データ収集インフラ: 強固なシステムは、より最新のデータを可能にします。
規制環境: 貿易協定の順守がデータの頻度に影響を与える可能性があります。
グローバル経済統合: グローバル経済への統合は、より頻繁なデータ収集につながる可能性があります。
統計能力: 各国の統計機関がデータを管理する能力がタイミングに影響します。
人口センサスと貿易データタイミングの相関関係
資源配分: より多くの資源があれば、センサスと貿易データの両方で頻繁な更新が可能になり、正の相関が生まれます。
政策の優先順位付け: データ駆動型の政策を優先する国は、データ収集の取り組みを同期させる可能性があります。
技術的進歩: 両方のデータタイプを効率的に管理することで、タイミングが相関する可能性があります。
外部からの影響: 国際的な要件により、両方のデータ収集プロセスが改善される可能性があります。
経済発展段階: 先進国はより定期的な更新を行う可能性がありますが、開発途上国はそうではないかもしれません。
結論と洞察
資源と政策の影響: 経済的資源と政策の優先順位は、データ更新の頻度と相関を決定する上で重要です。
技術的および外部的要因: 高度な技術と国際的な影響は、データ収集の取り組みの同期を強化することができます。
IDS_Country-SeriesMetaData.csvデータセットにおいて、異なる国々における「対外債務残高、合計」シリーズコードの経時的な傾向はどうなっていますか?
データソースと推定
国別報告と推定: 多くの国の2023年のデータは、国の報告書または世界銀行のスタッフ推定に基づいています。例えば、アフガニスタンのデータには世界銀行のスタッフ推定が含まれており、アンゴラのデータはアンゴラ国立銀行からのものです。
含まれる債務の種類
債務カテゴリ: データセットは、長期公的・公的保証債務、長期民間無保証債務、短期債務を区別しています。例えば、アルゼンチンのデータには、長期公的債務と民間無保証債務の両方が含まれています。
歴史的背景と調整
債務再編と軽減: ブルンジのパリクラブ合意やHIPCおよびMDRI債務軽減など、一部の国では債務再編合意による歴史的な調整があります。
債務軽減イニシアチブへの参加
債務返済停止イニシアチブ(DSSI): いくつかの国は2020年と2021年にDSSIに参加し、報告された債務水準に影響を与えました。
地域別および経済グループ別トレンド
所得グループの変動: トレンドは地域や所得グループによって大きく異なり、低所得国がより多くの債務軽減イニシアチブに関与していることがよくあります。
特定の国のトレンド
中国とエチオピア: 中国のデータは世界銀行の推定と国別報告に依存しており、エチオピアのデータはHIPCとMDRI軽減による債務削減を反映しています。
データ制限と除外
不完全なデータ: 一部の国には不完全なデータや除外があり、例えばイラクには長期民間無保証債務のデータが欠落しています。
結論と洞察
多様なデータソース: トレンドは、国別報告、世界銀行の推定、国際債務軽減イニシアチブへの依存が混在していることを示しています。
地域間の変動: 経済状況と歴史的合意の影響を受け、異なる地域や所得グループ間で対外債務のトレンドに significant な変動があります。
IDS_CountryMetaData_table_0.csvデータセットにおいて、「所得グループ」の分布は異なる「融資カテゴリー」間でどのように異なりますか?
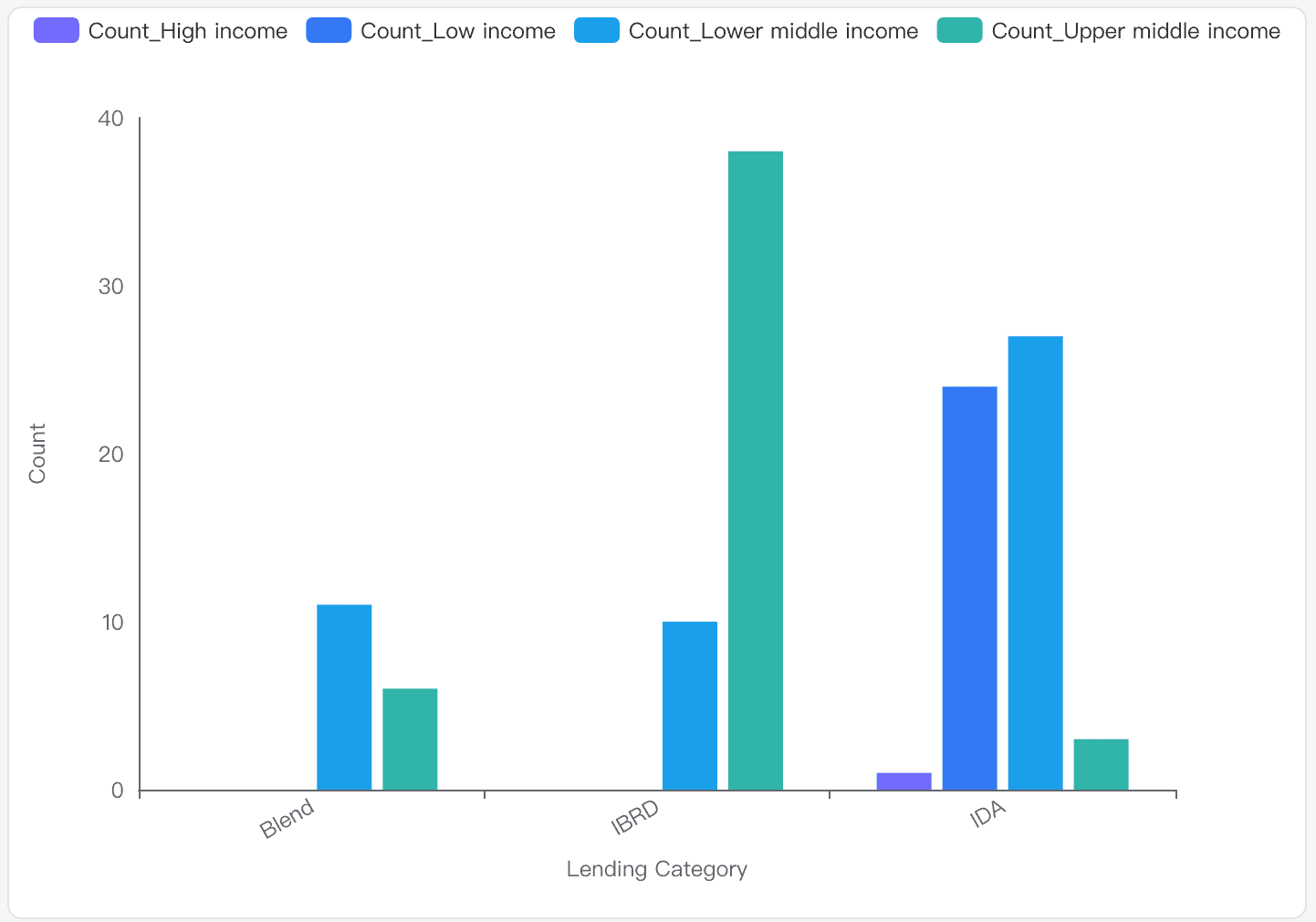
データ分析
所得グループ: データセットには、「高所得」「低所得」「低中所得」「高中所得」が含まれます。
融資カテゴリー: カテゴリーは「IDA」「ブレンド」「IBRD」です。
カウント統計: カウントは1から38の範囲で、平均は15です。
視覚化による洞察
IDA: 主に「低所得」と「低中所得」グループで構成されます。
IBRD: 主に「高中所得」国が含まれます。
ブレンド: 「低中所得」と「高中所得」グループが混在しています。
詳細な分布
IDA:
低所得: 24
低中所得: 27
高中所得: 3
高所得: 1
IBRD:
低所得: 0
低中所得: 10
高中所得: 38
高所得: 0
ブレンド:
低所得: 0
低中所得: 11
高中所得: 6
高所得: 0
結論と洞察
IDAカテゴリー: 主に「低所得」国と「低中所得」国を対象としています。
IBRDカテゴリー: 「高中所得」国が大部分を占めます。
ブレンドカテゴリー: 「低中所得」グループと「高中所得」グループがバランスよく混在しています。
IDS_CountryMetaData_table_0.csvデータセットにおいて、異なる地域の国々が使用する「国民経済計算体系(System of National Accounts)」の方法論に顕著な違いはありますか?
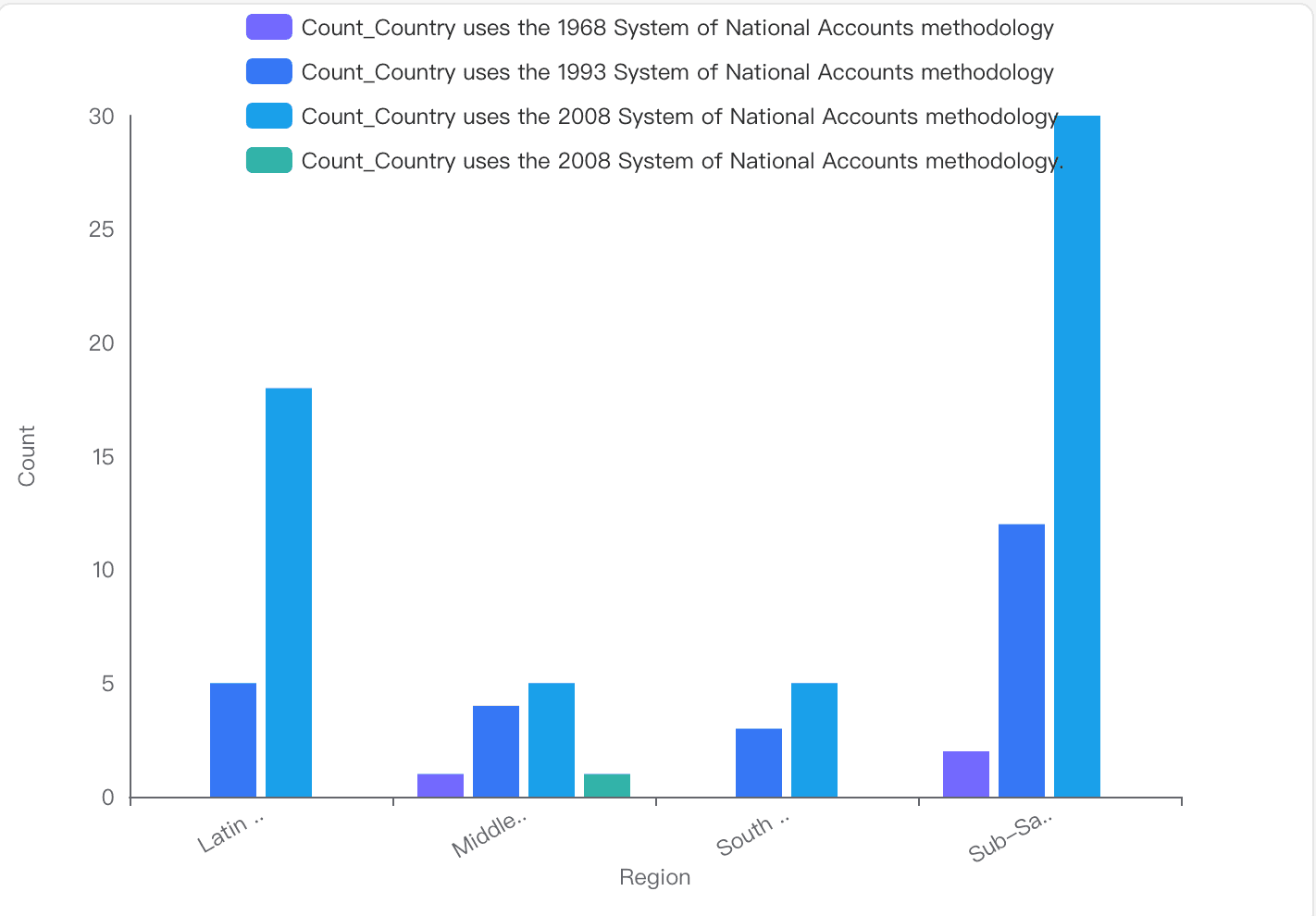
方法論の分布
1993年国民経済計算体系: 南アジア、サハラ以南アフリカ、東アジア・太平洋など、様々な地域の国々で使用されています。
2008年国民経済計算体系: 主にヨーロッパ・中央アジア、ラテンアメリカ・カリブ海、東アジア・太平洋で使用されています。
1968年国民経済計算体系: 比較的まれですが、中東・北アフリカなどの地域で依然として使用されています。
視覚化による洞察
サハラ以南アフリカ: 2008年SNAを使用している国が相当数見られますが、一部では1993年版や1968年版もまだ使用されています。
ラテンアメリカ・カリブ海: 主に2008年SNAを使用しており、最新の方法論がより均一に採用されていることを示しています。
中東・北アフリカ: 混合型であり、一部の国では1968年SNAのような古い方法論がまだ使用されています。
結論と洞察
多様な採用状況: SNAの方法論の採用には地域間で顕著な違いがあり、経済発展と統計能力のレベルの多様性を反映しています。
2008年SNAの優位性: 2008年SNAは広く採用されていますが、1993年版や1968年版のような古いバージョンは特定の地域で依然として使用されており、統計システムを世界的に更新することの課題を浮き彫りにしています。
IDS_SeriesMetaData_table_0.csvデータセットにおいて、「集計方法」は異なる「トピック」間でどのように異なりますか?
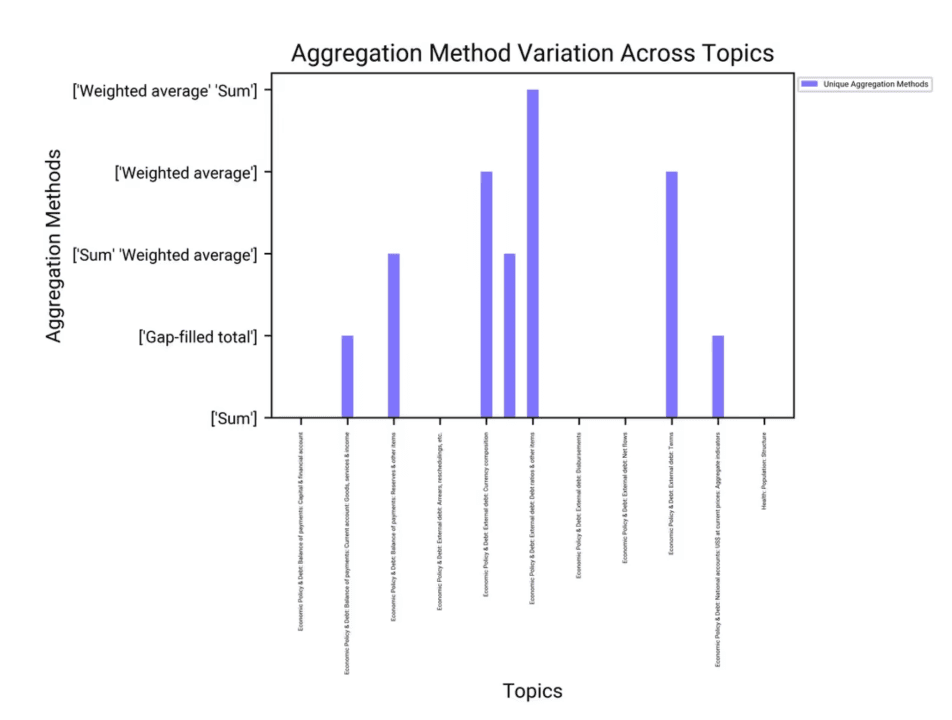
集計方法の分析
合計(Sum): これは、経済政策や債務関連のトピックを含む、様々なトピックで最も一般的に使用される集計方法です。
加重平均(Weighted Average): 対外債務や通貨構成などの特定のトピックで使用されます。
ギャップフィルされた合計(Gap-filled Total): 国際収支や国民経済計算に関連するトピックに適用されます。
視覚化による洞察
分布: 棒グラフは、「合計」方法がほとんどのトピックで普及しており、その一般的な適用性を示していることを示しています。
特定の方法: 対外債務や通貨構成のような特定のトピックでは「加重平均」が利用されており、これらの分野ではよりニュアンスのある集計が必要であることを強調しています。
結論と洞察
「合計」の優位性: 「合計」方法は広く使用されており、多くの経済および健康関連のトピックでデータを集計するのに適していることを示唆しています。
専門的な方法: 特定のトピックにおける「加重平均」や「ギャップフィルされた合計」の使用は、それらの分野のデータの独特な性質を反映した、データ集計への調整されたアプローチを示しています。