ChatBI:自然言語から複雑なビジネスインテリジェンスSQLへのアプローチ

中心テーマ
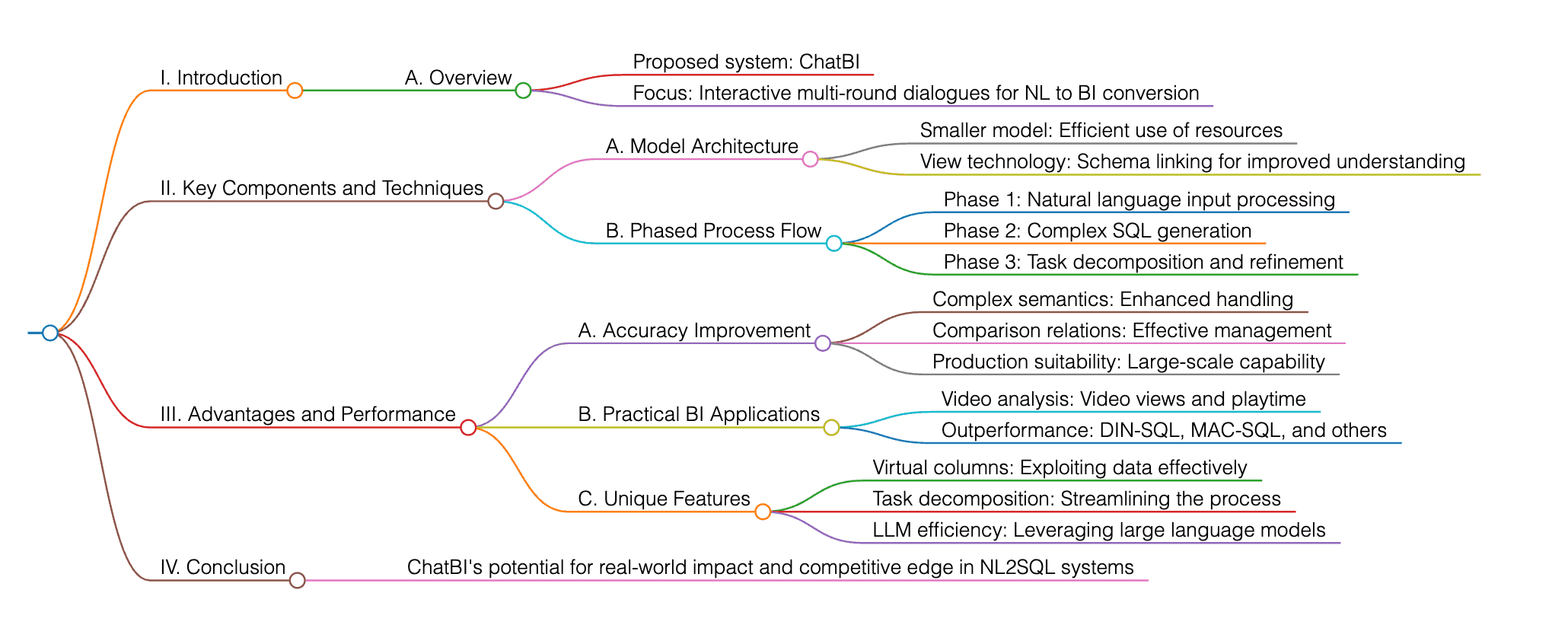
ChatBIとは、インタラクティブでマルチラウンドの対話に焦点を当てて自然言語からビジネスインテリジェンス(NL2BI)を向上させる新たなAIシステムです。このシステムは、自然言語を複雑なSQLに変換する際の課題に対処するために、より小さなモデルやビュー技術によるスキーマリンク、そして段階的なプロセスフローを採用しています。このようなアプローチにより、複雑な意味構造や比較関係の処理精度が向上し、大規模な実運用環境にも適応できるようになります。既存の自然言語からSQLへの変換(NL2SQL)手法と比較して、動画視聴回数や再生時間の分析といった現実的なBIシナリオにおいても優れた性能を発揮します。ChatBIは仮想カラムの活用、タスクの分解、LLM(大規模言語モデル)の効率的利用を通じて、DIN-SQLやMAC-SQLといったベースラインよりも有効な実行精度を達成しています。
マインドマップ
問題定義:本論文は何を解決しようとしているのか?これは新しい問題か?
本論文では、自然言語からビジネスインテリジェンス(NL2BI)における課題に対して、問題を段階的に分解するプロセスフローを導入することで対処しています。この問題自体は新しいものではなく、従来の手法ではBIシナリオにおける複雑な意味構造や計算関係、比較関係の処理に苦慮してきました。
科学的仮説:本論文が検証しようとしている科学的仮説は何か?
本論文では、段階的なプロセスフローによってBIシナリオ内の複雑な意味構造、計算関係、比較関係を効果的に扱うことができるという仮説を検証しています。
提案された新アイデア・方法・モデル:どのような新規性があるのか?既存手法との違いや利点は?
本論文では、自然言語をビジネスインテリジェンスに変換するための包括的かつ効率的な技術であるChatBIを提案しています。ChatBIは、NL2BI問題を段階的に分解するプロセスフローを導入しており、特に複雑な意味構造、計算関係、比較関係を効果的に処理することを目的としています。また、データベース分野での既存のビュー技術を組み合わせることで、スキーマリンクの課題に対処しています。具体的には、問題を「単一ビュー選択問題」に分解し、より小さな機械学習モデルをスキーマリンクに使用しています。
ChatBIの特徴と利点:
段階的なプロセスフロー
NL2BI問題を管理可能なステップに分解することで、複雑な意味構造、計算関係、比較関係を効果的に処理できます。スキーマリンクの改善
データベースコミュニティの既存のビュー技術を活用し、問題を「単一ビュー選択問題」に分解することで、スキーマリンクの精度と効率を向上させます。効率性
段階的なプロセスフローやスキーマリンク技術により、全体的な処理効率が向上します。複雑な意味構造の処理能力
自然言語クエリに含まれる複雑な意味構造を正確に解釈・処理することが可能です。精度の向上
段階的な処理とスキーマリンクの組み合わせにより、ビジネスインテリジェンスの洞察生成における精度が高まります。
関連研究:類似研究はあるか?注目すべき研究者や団体は?
自然言語からSQLへの変換(NL2SQL)に関する研究は多数存在します。主なアプローチとしては、事前学習+教師ありファインチューニング(SFT)、プロンプトエンジニアリングに基づくLLM、NL2SQL専用に訓練されたLLMがあります。DIN-SQL、C3、SQL-PaLMなどの手法は、プロンプトエンジニアリングを用いて自然言語からのSQL生成精度を向上させてきました。また、NeurIPSなどでも関連研究が進められています。
注目すべき研究者は、Google、Microsoft、Amazon、Meta、Oracle、Snowflake、Databricks、Baidu、Alibabaなどの企業所属者が挙げられます。
解決策の鍵:論文中で述べられている解決策の要諦は何か?
段階的なプロセスフローを設計し、NL2BI問題を分解することで、BIシナリオにおける複雑な意味構造、計算関係、比較関係を効果的に処理することです。
実験デザイン:論文の実験はどのように設計されているか?
実験は以下の3つのカテゴリに基づいて設計されています:
事前学習+教師ありファインチューニング(SFT)
プロンプトエンジニアリングに基づくLLM
NL2SQL専用に訓練されたLLM
これらのアプローチは、自然言語をSQLに変換するさまざまな手法を網羅しており、特にBIシナリオにおける現実的な分析タスクでの性能評価が行われています。
定量評価に使われたデータセットとコード公開状況:
定量評価にはSRDデータセットが使用されています。また、Qwen-72Bモデルについてはオープンソースとなっています。
実験結果の妥当性:論文の実験と結果は科学的仮説の検証に十分な裏付けを提供しているか?
実験結果は、段階的なプロセスフローと仮想カラムが複雑な意味構造、計算、比較関係を処理する上で有効であることを示しており、仮説の検証に十分な裏付けを提供しています。
論文の貢献:
BIシナリオにおける複雑な意味構造、比較、計算関係を処理する新たなプロセスフローの提案。
SQLクエリ実行精度を評価する新たな指標「有用性(usefulness)」の導入。
プロンプトとレスポンストークンに基づく経済的コスト評価に関する知見の提供。
スキーマリンクの最適化とデータ分析におけるトークン数削減のために、小型で安価なモデルの重要性について議論。
今後の研究課題:
LLMのNL2SQLタスクにおける精度向上のための効果的なプロンプティング技法の探求。
LLMによって生成される仮想カラムを用いたキャッシュの促進と計算速度の向上。
特にマルチラウンド対話(MRD)シナリオに焦点を当てたNL2BI技術の実際の生産システムにおける応用。
さらに詳しく知りたい場合:
上記の要約はPowerdrillによって自動生成されたものです。
詳細については、以下のリンクをご覧ください:
要約ページへ