医療分野における生成AI・大規模言語モデルの人間による評価に関する文献レビューとフレームワーク

研究概要
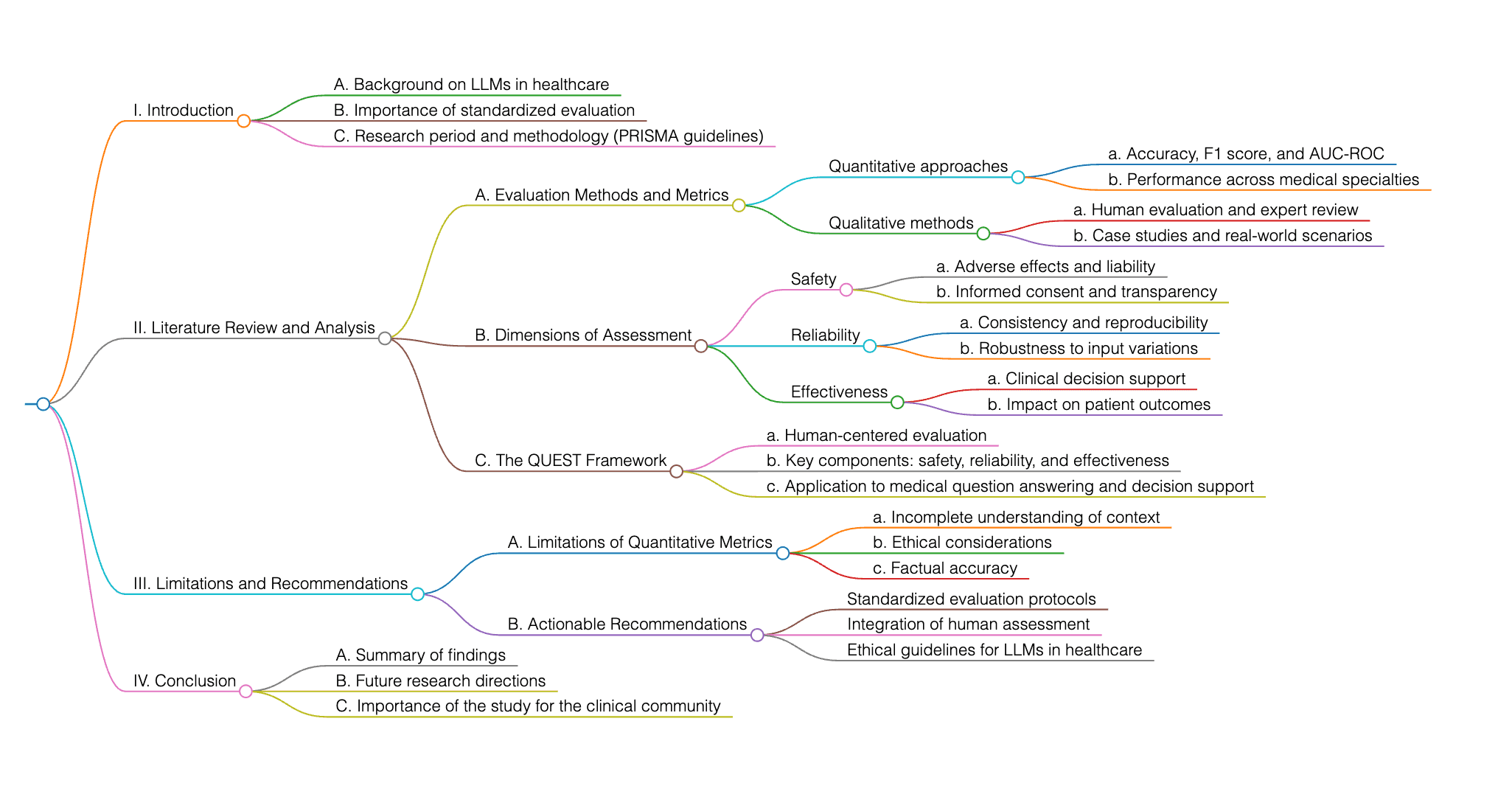
本研究では、医療分野における大規模言語モデル(LLM)の評価について考察します。特に、AIが生成する医療コンテンツの評価は複雑であるため、標準化されたアプローチに焦点を当てています。研究者らは、PRISMAガイドラインを用い、2018年から2024年までの文献を包括的にレビューし、様々な専門医療分野における評価手法、指標、評価軸を分析しました。本稿で提案するQUESTフレームワークは、特に医療に関する質疑応答や意思決定支援などの領域において、安全性、信頼性、有効性を確保するための人間による評価の必要性を強調するものです。本研究は、標準化された評価のためのフレームワークを提供し、現在の研究におけるギャップを埋め、臨床コミュニティが医療応用におけるLLMの信頼性を向上させるための実用的な提言を行うことを目的としています。また、定量的指標の限界や、事実の正確性および倫理的配慮を確保する上での人間による評価の重要性についても論じています。
マインドマップ
本論文はどのような問題の解決を試みていますか? また、これは新しい問題ですか?
本論文は、正解率やF1スコアといった定量的な評価指標のみに依存することの限界に対処しようとしています。これらの指標は、生成されたテキストの正確性を完全に検証するものではなく、臨床現場での厳格な評価に求められる詳細な理解を捉えきれない可能性があるためです。本稿は、言語モデルの出力が信頼性、事実の正確性、安全性、倫理的コンプライアンスの基準を満たしていることを保証するためのゴールドスタンダード(最も信頼性の高い基準)として、人間の評価者による定性的評価の重要性を強調しています。これが新しい問題であるかどうかを判断するには、言及されている問題に関連するより多くの文脈や特定の情報が必要です。
本論文が検証しようとしている科学的仮説は何ですか?
本論文は、LLMの性能とベンチマークとの間に観測された差の統計的有意性に関する仮説の検証を目指しており、これは通常P値を用いて評価されます。
本論文では、どのような新しいアイデア、手法、またはモデルが提案されていますか? 従来の手法と比較した際の特徴や利点は何ですか?
本論文は、評価の規模、サンプルサイズ、評価基準における限界など、大規模言語モデル(LLM)の評価における課題に対処するため、人間による評価のガイドラインを提案しています。さらに、本研究は、人間による評価のための包括的なフレームワークを提案することで、LLMに寄せられる期待と医療現場での要件との間のギャップを埋めることを目指しています。
提案されている人間による評価フレームワークは、人間の評価者による定性的評価の重要性を強調しており、これはLLMの出力における信頼性、事実の正確性、安全性、倫理的コンプライアンスを保証するためのゴールドスタンダードと見なされています。このアプローチは、現在の文献で主流となっている自動化された指標の使用とは対照的であり、医療応用における人間による評価方法論のより包括的な分析の必要性を浮き彫りにしています。このフレームワークは、臨床現場での厳格な評価に不可欠な定性的評価に焦点を当てることで、定量的評価指標の限界に対処することを目指しています。
関連研究は存在しますか? この分野で注目すべき研究者は誰ですか? 論文で言及されている解決策の鍵は何ですか?
はい、この分野では複数の関連研究が存在します。診断提案や臨床判断を含む様々な専門医療分野において、ChatGPTのような言語モデルの性能を評価するための研究が行われています。これらの研究では、T検定、カイ二乗検定、マクネマー検定などの統計的検定を用いて、AIモデルによって収集された医療情報の正確性と信頼性を医療従事者のものと比較しています。さらに、人間による評価の設計とモニタリングにおけるベストプラクティス、限界、そして様々な専門医療分野でのケーススタディに関する議論も行われています。
この分野で注目すべき研究者には、病理学における高次の問題解決を支援するChatGPTの適用可能性を探求したSinha, R. K.氏、Roy, A. D.氏、Kumar, N.氏、Mondal, H.氏、Sinha, R.氏などがいます。また、Ayers氏らは、Redditの「Ask Doctors」スレッドにおけるChatGPTの回答と医師が提供した回答を比較し、アドバイスの質と関連性に焦点を当てた研究を実施しました。これらの研究者は、医療現場におけるAIモデルの評価と応用において大きな貢献をしています。
論文で言及されている解決策の鍵は、特に医療における言語モデル(LLM)の応用という文脈において、人間の価値観と整合する適切な評価フレームワークを開発することにあります。
論文中の実験はどのように設計されましたか?
論文中の実験は、Redditの「Ask Doctors」スレッドにおけるChatGPTからの回答と医師が提供した回答を比較し、カイ二乗検定を用いてアドバイスの質と関連性の差を判断することによって設計されました。また、これらの研究では、言語モデル(LLM)の性能を評価するために、管理された環境と実世界のシナリオの両方でテストすることも考慮されています。
定量的評価にはどのようなデータセットが使用されていますか? コードはオープンソースですか?
医療応用における定量的評価に使用されるデータセットには、多くの場合、正解率、F1スコア、受信者動作特性曲線下面積(AUCROC)などの指標が含まれます。これらの指標は、様々な医療文脈で言語モデル(LLM)の性能を評価するために一般的に用いられますが、臨床現場での厳格な評価に求められる微妙なニュアンスの理解を完全には捉えきれない可能性があります。
レビューされた研究で最も使用されているモデルの中にMeta社のLlamaのようなオープンソースモデルは含まれていないと述べられているため、コードはオープンソースではありません。
論文中の実験と結果は、検証が必要な科学的仮説を十分に裏付けていますか? 分析してください。
これらの研究論文は、医療における言語モデルに関連する様々な実験と結果を提示しています。例えば、Tang氏らはT検定を用いて、ChatGPTが収集した医療情報の正しさを医療従事者のものと比較しました。また、Ayers氏らはカイ二乗検定を用いて、Redditの「Ask Doctors」スレッドにおけるChatGPTの回答と医師が提供した回答を比較し、アドバイスの質と関連性を評価しました。これらの実験は、医療文脈における言語モデルの性能と能力を評価することを目的としています。
研究論文で提示される科学的仮説は、研究の焦点や目的によって様々です。例えば、特定のタスクやシナリオにおける言語モデル(LLM)の性能を評価し、観測された差の統計的有意性を検証することを目的とする研究もあれば、LLMの回答と人間の専門家の回答を比較して質と関連性を評価し、カイ二乗検定のような統計的検定を用いて顕著な差を特定する研究もあります。さらに、科学研究や臨床応用など、様々な領域におけるLLMが生成した回答の信頼性や有用性を調査する研究も存在します。
この論文の貢献(執筆者ごとの役割)は何ですか?
本論文の貢献には、T.Y.C.T.氏とS.S.氏による研究の構想、設計、構成、結果の分析、そして論文の執筆、レビュー、改訂が含まれます。さらに、S.K.氏、A.V.S.氏、K.P.氏、K.R.M.氏、H.O.氏、X.W.氏が結果の分析、論文の執筆、レビュー、改訂で貢献しました。加えて、S.V.氏、S.F.氏、P.M.氏、G.C.氏、C.S.氏、Y.P.氏が論文の執筆、レビュー、改訂に関与しました。
今後、どのような研究を深めることができますか?
今後、様々な専門医療分野における人間による評価の評価軸の探求、人間による評価の設計とモニタリングにおけるベストプラクティスの議論、限界とそれを克服するための手法への対処、そして様々な医療タスクや専門分野におけるケーススタディの提供など、多岐にわたる分野でさらに深い研究を行うことができます。
続きを読む
上記の要約はPowerdrillによって自動生成されました。
こちらのリンクから、要約ページやその他のおすすめ論文をご覧いただけます。