Uso de GPT para Mejorar la Generación de Resúmenes: Una Estrategia para Minimizar las Alucinaciones

Tema Central
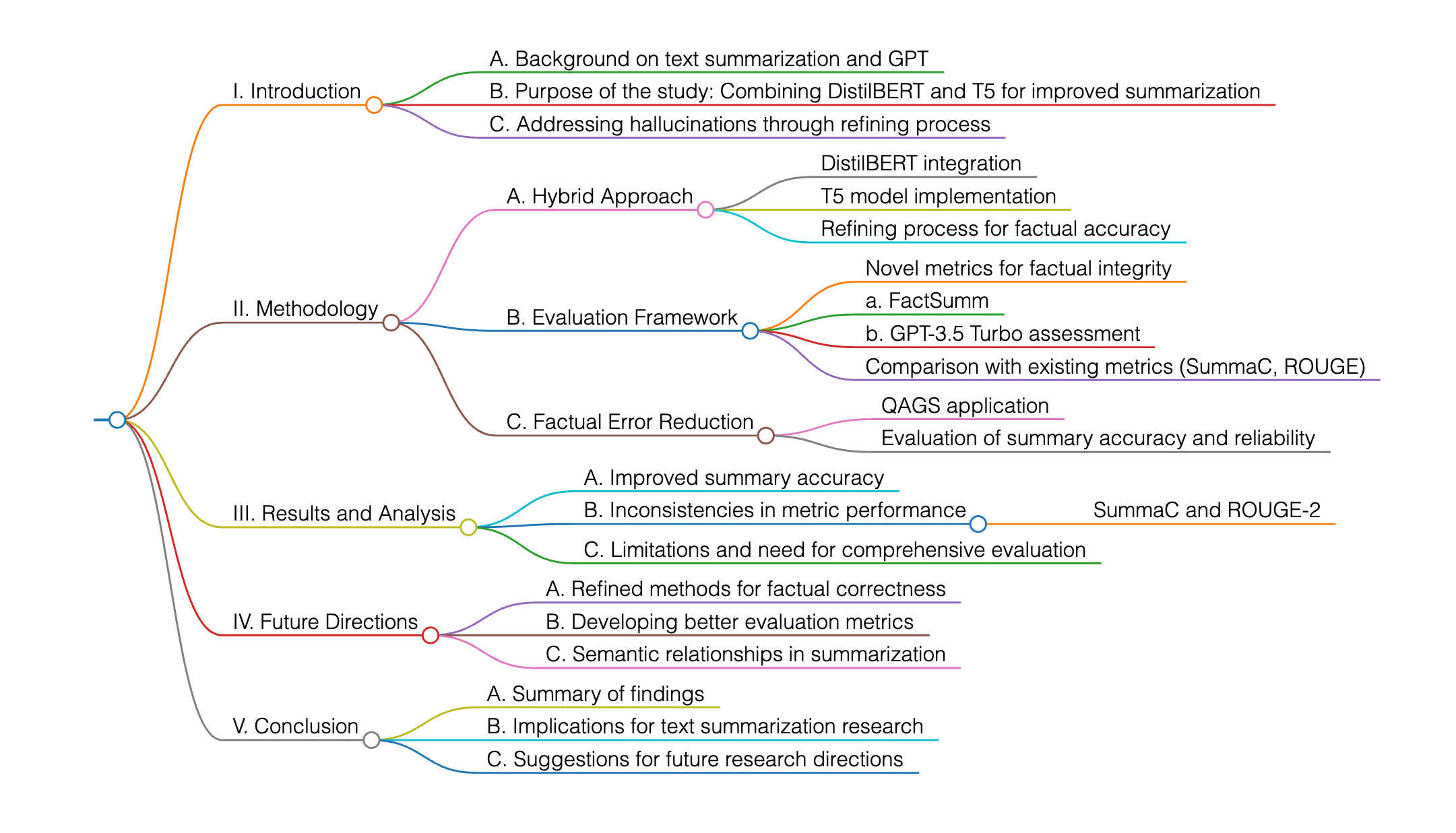
Esta investigación analiza el uso de GPT para mejorar la generación de resúmenes automáticos, combinando DistilBERT y T5, y abordando las hallucinations mediante un proceso de refinamiento. El estudio emplea un enfoque híbrido, evalúa la integridad factual con nuevas métricas y demuestra mejoras significativas en la precisión y fiabilidad de los resúmenes. Se centra en la reducción de errores factuales en los resúmenes abstractivos, utilizando métodos como QAGS, SummaC y ROUGE, y empleando GPT-3.5 Turbo para evaluar la precisión factual. Aunque algunas métricas como FactSumm y GPT-3.5 muestran mejoras, otras como SummaC y ROUGE-2 presentan resultados inconsistentes. La investigación sugiere la necesidad de desarrollar marcos de evaluación más completos, que consideren las relaciones semánticas y la corrección factual, proponiendo para el futuro el perfeccionamiento de los métodos y el diseño de mejores métricas.
Mapa Mental
TL;DR
¿Qué problema intenta resolver el artículo? ¿Es un problema nuevo?
El artículo busca resolver el problema de las hallucinations en los resúmenes automáticos, mejorando la consistencia factual y reduciendo el contenido inventado. Aunque este problema no es nuevo, el estudio introduce un enfoque novedoso basado en evaluación con GPT, que profundiza en la corrección semántica y factual, ofreciendo una solución más eficaz al problema de las hallucinations en resúmenes generados por IA.
¿Qué hipótesis científica se plantea validar?
El artículo plantea la hipótesis de que los resúmenes refinados presentan una puntuación media más alta que los no refinados, como lo demuestra el rechazo de la hipótesis nula en métricas como FactSumm, QAGS, GPT-3.5, ROUGE-1 y ROUGE-L.
¿Qué ideas, métodos o modelos nuevos propone el artículo? ¿Cuáles son sus características y ventajas respecto a métodos anteriores?
El estudio propone un novedoso método de refinamiento basado en GPT orientado a reducir las hallucinations en la resumición de textos. Este método combina las ventajas de la resumición extractiva y abstractiva, integrando el uso de Transformers generativos (GPT) para mejorar la calidad del resumen final. La investigación se centra en aplicar técnicas avanzadas de aprendizaje automático, como el aprendizaje por refuerzo, para minimizar errores y alucinaciones en los resúmenes generados automáticamente.
Explicaciones Contrafactuales y Semifactuales en la Argumentación Abstracta: Fundamentos Formales, Complejidad y Computación
Este estudio se adentra en el razonamiento contrafactual y semifactual dentro de los marcos de argumentación abstracta (AFs), centrándose en su complejidad computacional y su integración en sistemas de argumentación. La investigación define estos conceptos y busca mejorar la explicabilidad al codificarlos en AFs con restricciones débiles y mediante el uso de solucionadores ASP. Analizando la complejidad de tareas como existencia, verificación y aceptación bajo distintas semánticas, el estudio revela que estos problemas suelen ser más complejos que los enfoques tradicionales. La principal contribución de este trabajo reside en la propuesta de algoritmos y la discusión de aplicaciones prácticas que pueden mejorar la toma de decisiones y la persuasión en sistemas basados en argumentación.
1. Utilización de GPT para Mejorar la Generación de Resúmenes: Una Estrategia para Minimizar las Hallucinations
Esta investigación explora el uso de GPT para mejorar la generación de resúmenes automáticos, combinando DistilBERT y T5, con especial atención en la minimización de hallucinations a través de un proceso de refinamiento. El estudio aplica un enfoque híbrido e introduce métricas novedosas para evaluar la integridad factual, mostrando mejoras significativas en la precisión y fiabilidad de los resúmenes. Se hace hincapié en la reducción de errores factuales en los resúmenes abstractivos, empleando métodos como QAGS, SummaC y ROUGE, y utilizando GPT-3.5 Turbo para evaluar la precisión factual. Aunque algunas métricas como FactSumm y GPT-3.5 presentan mejoras, otras como SummaC y ROUGE-2 muestran resultados inconsistentes. El estudio sugiere la necesidad de desarrollar marcos de evaluación más completos, que consideren tanto las relaciones semánticas como la veracidad factual, proponiendo perfeccionar las metodologías y diseñar mejores métricas en futuras investigaciones.
2. NL2Plan: Planificación Robusta Impulsada por LLMs a partir de Descripciones Textuales Mínimas
NL2Plan presenta un sistema agnóstico al dominio que combina modelos de lenguaje de gran tamaño (LLMs) con planificación clásica para generar representaciones PDDL a partir de descripciones en lenguaje natural. Este sistema supera al enfoque Zero-Shot CoT, resolviendo un mayor número de tareas, ofreciendo explicabilidad y facilitando la creación de planes en PDDL. El proceso de NL2Plan incluye extracción de tipos, construcción jerárquica y elaboración de acciones, con opción de retroalimentación humana. La evaluación en múltiples dominios revela tanto fortalezas como limitaciones, y se proponen futuras mejoras en eficiencia e integración con otras herramientas. Para una comprensión completa, se recomienda consultar las metodologías y resultados específicos descritos en el artículo.
3. Evaluación de Resúmenes Generados por Modelos de Lenguaje Mediante GPT de OpenAI
Este estudio analiza la eficacia de los modelos GPT de OpenAI para evaluar resúmenes generados por seis modelos de tipo transformer (DistilBART, BERT, ProphetNet, T5, BART y PEGASUS) utilizando métricas como ROUGE, LSA y evaluaciones internas de GPT. La investigación muestra fuertes correlaciones, especialmente en relevancia y coherencia, indicando el potencial de GPT como herramienta de evaluación para tareas de resumen automático. La evaluación, basada en el dataset CNN/Daily Mail, se centra en aspectos como concisión, relevancia, coherencia y legibilidad, subrayando la importancia de integrar evaluaciones automatizadas impulsadas por IA. El estudio propone expandir la investigación a otras tareas del procesamiento de lenguaje natural (PLN) y explorar la percepción humana sobre las evaluaciones generadas por IA.
4. DeepSeek-V2: Un Modelo de Lenguaje Mixture-of-Experts Eficiente, Potente y Económico
DeepSeek-V2 se presenta como un modelo de lenguaje Mixture-of-Experts (MoE) de bajo coste con 236 mil millones de parámetros, que utiliza MLA para atención eficiente y DeepSeekMoE en el entrenamiento. Supera a modelos open-source como LLaMA y Qwen con menos parámetros activos, destacando en eficiencia y rendimiento. Entre sus características se incluyen:
42,5 % menor coste de entrenamiento,
93,3 % de reducción en la caché KV,
5,76 veces mayor velocidad de generación.
Entrenado sobre un corpus de 8,1T tokens, DeepSeek-V2 destaca en diversos benchmarks, consolidándose como una opción potente y viable para múltiples aplicaciones. Para un análisis completo, se recomienda consultar las metodologías y resultados descritos en el artículo.
5. Escalado de la Privacidad Diferencial Métrica mediante Partición Secreta de Datos y Descomposición de Benders
Este trabajo propone un enfoque escalable para aplicar Privacidad Diferencial Métrica (mDP) utilizando la Descomposición de Benders, que consiste en particionar conjuntos de datos secretos y reformular el problema como programación lineal. Al gestionar las perturbaciones dentro de cada subconjunto, se mejora la eficiencia, reduciendo la complejidad computacional y aumentando la escalabilidad. Los experimentos en distintos datasets muestran una mejora de 9 veces respecto a métodos anteriores. Se comparan diversos algoritmos de partición (k-m-DV, k-m-rec, k-m-adj, y BSC), siendo k-m-DV el que ofrece mejores resultados gracias al equilibrio entre subproblemas. El estudio también explora aplicaciones en privacidad de localización, análisis de texto y privacidad basada en grafos, proponiendo futuras mejoras.
6. Representaciones BERT Enriquecidas para Clasificación de Publicaciones Académicas
Este estudio se centra en la clasificación automática de publicaciones académicas para la tarea compartida NSLP 2024 FoRC Shared Task I, empleando modelos de lenguaje preentrenados como BERT, SciBERT, SciNCL y SPECTER2. Se enriquece el conjunto de datos con artículos en inglés de ORKG y arXiv para abordar el desequilibrio de clases. A través de fine-tuning y aumento de datos provenientes de bases bibliográficas, se mejora la clasificación, destacando SPECTER2 por su mayor precisión. El uso de metadatos de S2AG, OpenAlex y Crossref potencia aún más el rendimiento, logrando un F1-score ponderado de 0.7415. El estudio explora también transferencia de aprendizaje, modelos personalizados como TwinBERT, y el impacto de los metadatos, mostrando el potencial de los sistemas automatizados ante el crecimiento exponencial de literatura científica.
7. Mejora de la Eficiencia y Precisión en Revisiones de Activos Subyacentes en Finanzas Estructuradas: Aplicación de Marcos Multi-agente
Esta investigación explora la integración de inteligencia artificial —en particular modelos de lenguaje de gran tamaño (LLMs)— para mejorar la eficiencia y precisión en las revisiones de activos dentro de las finanzas estructuradas. Destaca el potencial de los modelos cerrados como GPT-4 en términos de rendimiento, y la rentabilidad de modelos open-source como LLAMA3. Se estudian sistemas de doble agente para mejorar la precisión, aunque a un mayor coste. El enfoque se centra en la automatización de verificación de información, el análisis de documentos financieros y la gestión de riesgos, especialmente en auto ABS. Se proporciona código disponible para investigación adicional. Además, el estudio compara modelos de IA, discute desafíos regulatorios y propone líneas futuras en escalabilidad, optimización de costes y cumplimiento normativo.
8. Revisitando los Ataques Adversarios a Nivel de Caracteres
El artículo presenta Charmer, un ataque adversario a nivel de caracteres para modelos de NLP, que supera métodos anteriores al lograr mayores tasas de éxito y mejores métricas de similitud. Charmer demuestra su eficacia especialmente con una selección codiciosa de posiciones, mostrando buenos resultados tanto en modelos pequeños como grandes. Supera técnicas defensivas basadas en tokens y estrategias de reconocimiento robusto de palabras. El estudio pone de relieve los desafíos de seguridad en NLP, las limitaciones de métodos basados en gradientes, y la necesidad de defensas robustas contra ejemplos adversarios. Para una comprensión detallada, se recomienda revisar las metodologías y resultados completos en el artículo.
9. ¿Una Cuarta Ola de Datos Abiertos? Explorando el Espectro de Escenarios para Datos Abiertos e IA Generativa
El artículo de Chafetz, Saxena y Verhulst analiza el impacto potencial de la IA generativa sobre los datos abiertos, explorando cinco escenarios: preentrenamiento, adaptación, inferencia, aumento de datos y exploración abierta. Se destacan oportunidades y desafíos como la calidad de los datos, la proveniencia y consideraciones éticas, abogando por una mejor gobernanza de datos y mayor transparencia. A través de casos de estudio y Action Labs, los autores examinan la intersección entre datos abiertos e IA, subrayando la necesidad de estandarización, interoperabilidad y un uso responsable. El artículo busca orientar el desarrollo de políticas y tecnologías en el contexto de una IA en constante evolución.
¿Existen investigaciones relacionadas? ¿Quiénes son los investigadores más destacados en este campo? ¿Cuál es la clave de la solución propuesta en el artículo?
Sí, existen numerosas investigaciones relacionadas con el resumen automático y la reducción de hallucinations. Diversos estudios se han centrado en mejorar la calidad de los resúmenes generados por IA, buscando reducir la generación de información inventada o inexacta. Estas investigaciones tienen como objetivo principal mejorar la precisión factual y la integridad semántica de los resúmenes mediante el uso de técnicas avanzadas de aprendizaje automático y métricas de evaluación refinadas.
Entre los investigadores más destacados en el campo de los resúmenes mejorados con GPT para la reducción de hallucinations se encuentran:
Wang et al. (2020)
Lin (2004)
Lehmann y Romano (2005)
Heo (2021)
Laban et al. (2022)
Estos autores han aportado métodos innovadores y métricas especializadas para detectar y reducir hallucinations en resúmenes generados automáticamente.
La clave de la solución propuesta en el artículo reside en la utilización de GPT-3.5 Turbo como herramienta de evaluación. Gracias a sus avanzadas capacidades de comprensión lingüística, GPT permite evaluar la consistencia factual e identificar hallucinations de manera eficaz, posicionándolo como un modelo adecuado para verificar la fiabilidad de resúmenes generados por otros modelos.
¿Cómo fueron diseñados los experimentos del estudio?
Los experimentos se diseñaron para evaluar la efectividad de los resúmenes refinados mediante GPT-3.5 Turbo, con el objetivo de medir la consistencia factual y detectar posibles hallucinations. La metodología incluyó pruebas estadísticas con una hipótesis nula que afirmaba que la puntuación media de los resúmenes refinados no sería superior a la de los resúmenes sin refinar. La hipótesis alternativa postulaba que los resúmenes refinados sí obtendrían una puntuación media más alta.
Se emplearon las siguientes métricas de evaluación:
FactSumm
QAGS
GPT-3.5
ROUGE-1
ROUGE-L
El análisis estadístico reveló mejoras significativas tras el refinamiento, lo que permitió rechazar la hipótesis nula en varias métricas, respaldando así la validez de la hipótesis científica planteada.
¿Qué conjunto de datos se utilizó para la evaluación cuantitativa? ¿El código es de código abierto?
Para la evaluación cuantitativa, se utilizaron métricas como FactSumm, QAGS, GPT-3.5, ROUGE-1 y ROUGE-L. Sin embargo, no se proporciona información específica sobre el conjunto de datos concreto o sobre la disponibilidad del código en código abierto en el contexto proporcionado.
Si deseas verificar si el código es accesible públicamente, sería necesario contar con más detalles o referencias directas al repositorio del estudio.
¿Los experimentos y resultados del artículo respaldan las hipótesis científicas que se pretendían verificar? Análisis
Sí, los experimentos y resultados expuestos en el artículo proporcionan un respaldo sólido a las hipótesis científicas formuladas. El análisis estadístico aplicado a las diferentes métricas mostró mejoras consistentes tras el proceso de refinamiento, lo que permitió rechazar la hipótesis nula en indicadores clave como FactSumm, QAGS, GPT-3.5, ROUGE-1 y ROUGE-L.
Estos hallazgos sugieren que el método de refinamiento propuesto contribuye de manera efectiva a mejorar la calidad y precisión factual de los resúmenes generados, validando así la hipótesis principal del estudio.
¿Cuáles son las contribuciones de este artículo?
El artículo aporta al campo de la resumición automática con IA una novedosa metodología de evaluación basada en GPT, diseñada para mejorar la consistencia factual y reducir las hallucinations. Esta propuesta no solo se enfoca en que los resúmenes guarden similitud léxica con el texto original, sino que también asegura que la información generada sea veraz y coherente con el contenido fuente, lo que representa una mejora sustancial frente a enfoques anteriores.
¿Qué líneas de trabajo podrían continuarse en profundidad?
Entre las posibles líneas de trabajo para investigaciones futuras destacan:
Mejorar la efectividad de los métodos de resumen abstractivo, minimizando errores y hallucinations mediante técnicas como el aprendizaje por refuerzo, que penalicen la generación de contenido no presente en el texto fuente.
Desarrollar métricas más robustas que consideren no solo coincidencias léxicas, sino también la coherencia semántica y la veracidad factual.
Integrar sistemas de evaluación automática en tiempo real durante el proceso de generación de resumen, lo que podría aumentar aún más la precisión y utilidad práctica de los resúmenes generados por IA.
Leer más
El resumen anterior ha sido generado automáticamente por Powerdrill.
Haz clic en el enlace para ver la página de resumen y otros artículos recomendados.