Hacia una mejor alineación de generación de texto a imagen mediante modulación de atención

Tema Central
El documento aborda los desafíos en la generación de imágenes a partir de texto utilizando modelos de difusión, particularmente la filtración de entidades y la desalineación de atributos, al introducir un mecanismo de modulación de atención sin entrenamiento. Este método implica control de temperatura de autoatención, enmascaramiento de atención cruzada enfocado en objetos y reponderación dinámica por fases. El enfoque mejora la alineación sin necesidad de grandes cantidades de datos etiquetados, resultando en una mejor alineación entre imagen y texto y mejores imágenes generadas, incluso con solicitudes complejas. Los experimentos demuestran un rendimiento de vanguardia, mostrando un manejo superior de múltiples entidades y atributos, y un costo computacional reducido en comparación con los modelos existentes.
Mapa Mental
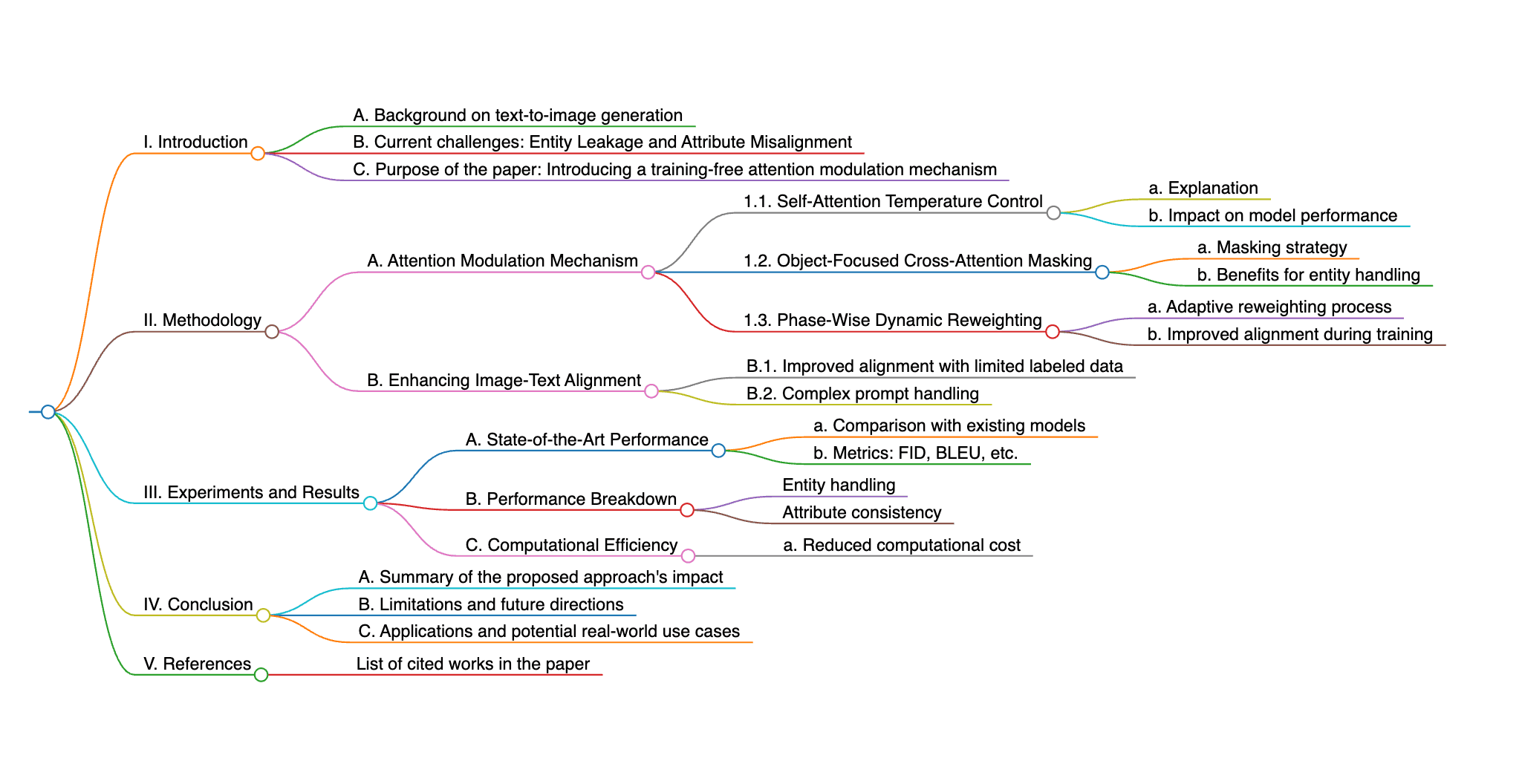
Resumen
Q1. ¿Qué problema intenta resolver el documento? ¿Es este un problema nuevo?
El documento tiene como objetivo abordar los problemas de filtración de entidades y desalineación de atributos en las tareas de síntesis de texto a imagen. Estos problemas no son totalmente nuevos, pero han sido desafíos persistentes en el campo.
Q2. ¿Qué hipótesis científica busca validar este documento?
El documento busca validar la hipótesis de que un mecanismo de control de atención por fases y sin entrenamiento puede abordar de manera efectiva los problemas de filtración de entidades y desalineación de atributos en tareas de generación de texto a imagen.
Q3. ¿Qué nuevas ideas, métodos o modelos propone el documento? ¿Cuáles son las características y ventajas en comparación con métodos anteriores?
El documento propone un mecanismo de enfoque de atribuciones a través de un paradigma de control de atención por fases y sin entrenamiento para abordar desafíos en las tareas de generación de texto a imagen. Este mecanismo implica varios componentes clave: un mecanismo de control de temperatura en módulos de autoatención para mitigar problemas de filtración de entidades, un esquema de enmascaramiento enfocado en objetos en módulos de atención cruzada para discernir efectivamente la información semántica entre entidades, y un mecanismo de control dinámico de peso por fases para mejorar la alineación entre imagen y texto.
Además, el documento introduce un enfoque novedoso que combina el control de temperatura de autoatención, la máscara de atención cruzada enfocada en objetos y la estrategia de reponderación dinámica por fases para aliviar la filtración de entidades y la desalineación de atributos. Estos métodos buscan mejorar la capacidad del modelo para centrarse en componentes semánticos específicos, reducir la desalineación de atributos y mejorar la alineación general de imagen y texto con un costo computacional adicional mínimo.
El documento presenta varias características y ventajas clave en comparación con métodos anteriores en tareas de generación de texto a imagen. En primer lugar, el mecanismo de enfoque de atribuciones propuesto incorpora un mecanismo de control de temperatura en módulos de autoatención para abordar problemas de filtración de entidades y un esquema de enmascaramiento enfocado en objetos en módulos de atención cruzada para discernir efectivamente la información semántica entre entidades, y un mecanismo de control dinámico de peso por fases para mejorar la alineación entre imagen y texto. Estos componentes trabajan sinérgicamente para mejorar la capacidad del modelo para enfocarse en componentes semánticos específicos y reducir la desalineación de atributos, llevando a una mejor alineación entre imagen y texto con un costo computacional adicional mínimo.
Además, el enfoque del documento integra un método de reponderación dinámica que asigna diferentes pesos a las máscaras controladas por curvas con diferentes tendencias, mejorando aún más las capacidades de control de atención del modelo. Al combinar estos mecanismos, el modelo puede distinguir efectivamente entre entidades y fondos de imagen, mejorando la calidad general de las imágenes generadas. En comparación con métodos anteriores, el enfoque del documento demuestra un rendimiento superior en escenarios que involucran solicitudes complejas con múltiples entidades y atributos.
Específicamente, el modelo supera la Difusión Estructurada en escenarios con múltiples pares de objeto-atributo, donde la solicitud contiene múltiples entidades y atributos, al garantizar una mejor afiliación de información semántica y reducir la desalineación de atributos. Esta mejora se atribuye al esquema de enmascaramiento enfocado en objetos y al mecanismo de control dinámico de peso por fases, que permiten al modelo centrarse mejor en componentes semánticos específicos y lograr una alineación de imagen y texto más precisa.
En general, los métodos propuestos por el documento ofrecen una solución integral para abordar desafíos como la filtración de entidades y la desalineación de atributos en tareas de generación de texto a imagen. Al incorporar mecanismos innovadores de control de atención y estrategias de reponderación dinámica, el modelo logra una mejor alineación de imagen y texto y genera imágenes de alta calidad con una fidelidad y precisión mejoradas.
Q4. ¿Existen investigaciones relacionadas? ¿Quiénes son los investigadores destacados en este tema en este campo? ¿Cuál es la clave de la solución mencionada en el documento?
En el campo de la generación de texto a imagen, existen varios trabajos de investigación relacionados. Investigadores notables en esta área incluyen a Xu et al., quienes introdujeron ImageReward para evaluar las preferencias humanas en la generación de texto a imagen. Feng et al. propusieron la Difusión Estructurada, centrándose en la generación compuesta de T2I. Otro trabajo significativo es el de Yihang Wu et al., quienes desarrollaron un mecanismo de enfoque de atribuciones para una mejor alineación entre imagen y texto. La clave de la solución mencionada en el documento involucra un mecanismo de control de atención por fases y sin entrenamiento. Este mecanismo integra el control de temperatura en el módulo de autoatención para mitigar problemas de filtración de entidades e incorpora un esquema de enmascaramiento enfocado en objetos y control dinámico de peso por fases en el módulo de atención cruzada para mejorar el discernimiento de la información semántica entre entidades.
Q5. ¿Cómo se diseñaron los experimentos en el documento?
Los experimentos en el documento se diseñaron para poner a prueba el rendimiento del modelo propuesto en varios escenarios de alineación, centrándose en la alineación entre imagen y texto con un costo computacional adicional mínimo. Los experimentos tenían como objetivo abordar desafíos relacionados con la filtración de entidades y la desalineación de atributos en tareas de generación de texto a imagen, incorporando un mecanismo de control dinámico de peso por fases y un esquema de enmascaramiento enfocado en objetos en los módulos de atención cruzada. Estos experimentos demostraron que el modelo logró una mejor alineación entre imagen y texto al discernir la afiliación de la información semántica entre entidades de manera más efectiva.
Q6. ¿Cuál es el conjunto de datos utilizado para la evaluación cuantitativa? ¿Es el código de código abierto?
El conjunto de datos utilizado para la evaluación cuantitativa incluye el conjunto de validación de COCO, y los criterios de evaluación implican FID, puntaje CLIP y puntaje ImageReward. En cuanto al código, la información sobre su disponibilidad como código abierto no se proporciona en los contextos disponibles. Para obtener más detalles sobre el código y su disponibilidad, es posible que necesite consultar la publicación o proyecto específico relacionado con la investigación.
Q7. ¿Proporcionan los experimentos y resultados en el documento un buen apoyo a las hipótesis científicas que deben verificarse?
Por favor, análisis. Los experimentos y resultados presentados en el documento proporcionan un fuerte apoyo a las hipótesis científicas que necesitaban verificación. El paradigma de control de atención por fases y sin entrenamiento propuesto aborda de manera efectiva los problemas de filtración de entidades y desalineación de atributos en tareas de generación de texto a imagen. A través de la implementación de control de temperatura de autoatención, enmascaramiento enfocado en objetos y estrategias de reponderación dinámica por fases, el modelo demuestra una mejor alineación entre imagen y texto con un costo computacional adicional mínimo. Los estudios de ablación realizados sobre los componentes clave del método validan aún más la efectividad de la estrategia de control de autoatención y el enmascaramiento enfocado en objetos para mejorar métricas de rendimiento como FID y puntaje CLIP. Los resultados indican que la integración de estos componentes conduce a un rendimiento más robusto en comparación con estrategias individuales.
Q8. ¿Cuáles son las contribuciones de este documento?
El documento propone un paradigma de control de atención por fases y sin entrenamiento para abordar cuestiones de filtración de entidades y desalineación de atributos en tareas de generación de texto a imagen. Las contribuciones incluyen la implementación de un mecanismo de control de temperatura de autoatención para mitigar problemas de filtración de entidades y la introducción de un esquema de enmascaramiento enfocado en objetos y un mecanismo de control dinámico de peso por fases en los módulos de atención cruzada para mejorar la afiliación de información semántica entre entidades. Además, el documento introduce una estrategia de reponderación dinámica por fases para mejorar la alineación de atributos al variar la énfasis en diferentes componentes semánticos de la solicitud durante el proceso de generación.
Q9. ¿Qué trabajo se puede continuar en profundidad?
El trabajo futuro en esta área podría centrarse en refinar el mecanismo de enmascaramiento enfocado en objetos para mejorar el control de atención en tareas de generación de texto a imagen. Además, explorar mecanismos de reponderación dinámica para priorizar diferentes componentes de la solicitud en varias etapas podría ser una avenida para una investigación más profunda.
El contenido es producido por Powerdrill, haga clic en el enlace para ver la página de resumen.
Para obtener un enlace completo del documento haga clic aquí.
Inicie sesión en powerdrill.ai para experimentar la generación de texto a imagen.