Demostración de DB-GPT

Tema Central
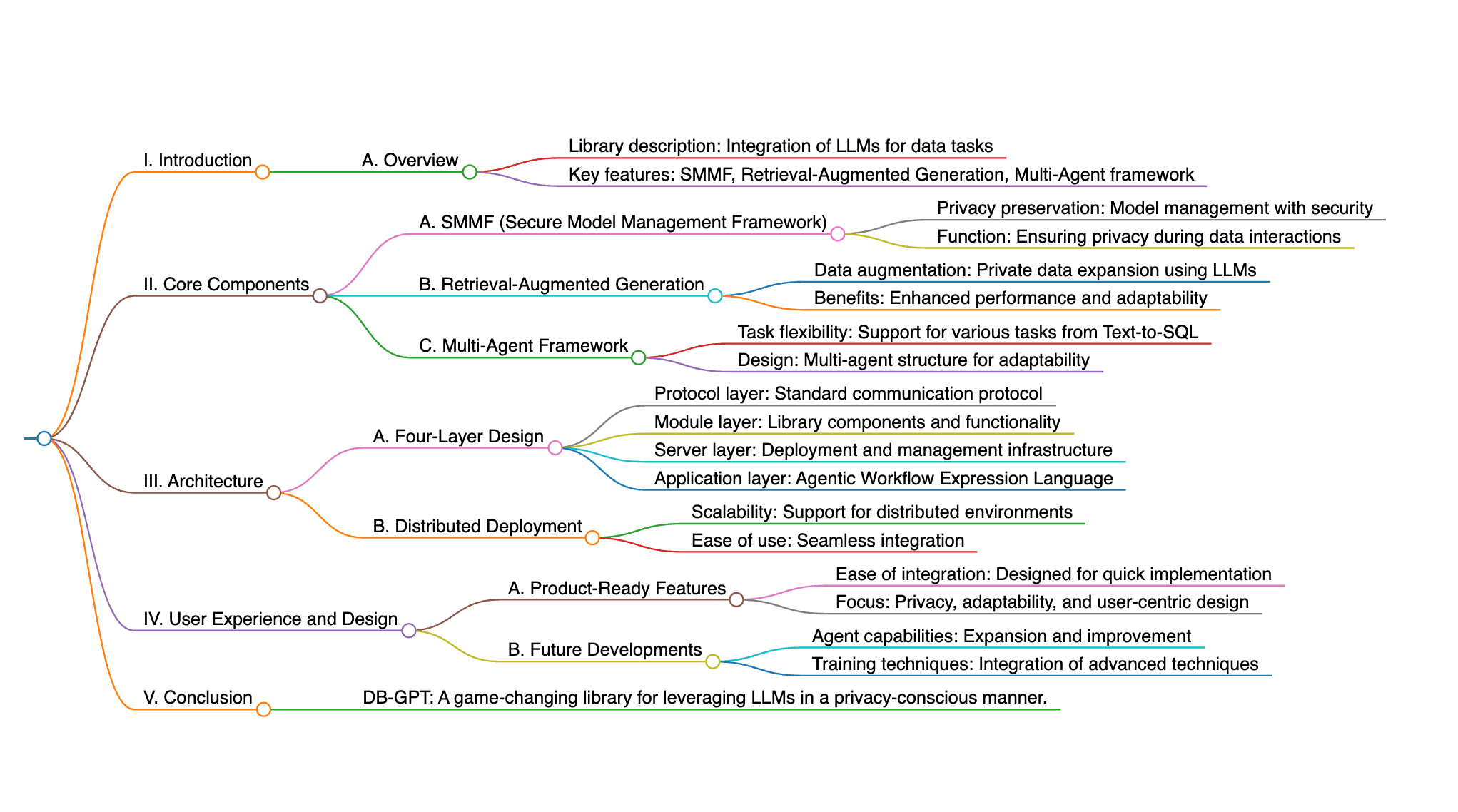
DB-GPT es una biblioteca de Python de código abierto que revoluciona la interacción con los datos al integrar modelos de lenguaje grandes en tareas, asegurando la privacidad con el SMMF y apoyando tareas desde texto a SQL hasta análisis complejos. Los componentes clave incluyen el SMMF para la gestión de modelos, Generación Aumentada por Recuperación para la augmentación de datos privados, y un marco de Multi-Agentes para la flexibilidad de tareas. La biblioteca presenta una arquitectura de cuatro capas (Protocolo, Módulo, Servidor, Aplicación) con el Lenguaje de Expresión de Flujo de Trabajo Agente, y soporta despliegue en entornos distribuidos. DB-GPT mejora los LLMs, ofrece características listas para el producto, y está diseñado para una fácil integración, con un enfoque en la privacidad, adaptabilidad y experiencia del usuario. Los desarrollos futuros ampliarán las capacidades de los agentes e integrarán más técnicas de capacitación.
Mapa Mental
Resumen
Q1. ¿Qué problema intenta resolver el documento? ¿Es este un problema nuevo?
El documento tiene como objetivo abordar el desafío de mejorar las tareas de interacción con datos utilizando Modelos de Lenguaje Grandes (LLMs) para proporcionar a los usuarios un entendimiento e insights confiables sobre sus datos. Este no es un problema nuevo, ya que la integración de LLMs en tareas de interacción de datos ha sido un área de investigación y desarrollo en curso.
Q2. ¿Qué hipótesis científica busca validar este documento?
El documento busca validar la hipótesis de que integrar modelos de lenguaje grandes (LLMs) en tareas de interacción con datos puede mejorar la experiencia del usuario y la accesibilidad al proporcionar respuestas contextuales informadas por LLMs, convirtiéndolo en una herramienta indispensable para usuarios desde principiantes hasta expertos.
Q3. ¿Qué nuevas ideas, métodos o modelos propone el documento?
¿Cuáles son las características y ventajas en comparación con métodos anteriores? El documento propone DB-GPT, una biblioteca de Python que integra modelos de lenguaje grandes (LLMs) en tareas tradicionales de interacción con datos para mejorar la experiencia del usuario y la accesibilidad. Introduce un marco de Multi-Agentes inspirado en MetaGPT y AutoGen para abordar tareas desafiantes de interacción con datos como el análisis de datos generativo. Este marco aprovecha múltiples agentes con capacidades especializadas para manejar desafíos multifacéticos, como la construcción de informes de ventas detallados desde diferentes dimensiones. Además, el marco de Multi-Agentes de DB-GPT archiva el historial de comunicación entre los agentes, mejorando la confiabilidad del contenido generado. El documento también discute la importancia de incorporar razonamiento automatizado impulsado por LLM y procesos de decisión en tareas de interacción de datos. Hace hincapié en la necesidad de marcos de multi-agentes agnósticos a la tarea para atender efectivamente diversas tareas de interacción con datos. Además, el documento destaca la importancia de configuraciones sensibles a la privacidad para interacciones de datos potenciadas por LLM, un aspecto que ha sido poco investigado en esfuerzos anteriores. El documento esboza varias características y ventajas de DB-GPT en comparación con métodos anteriores. DB-GPT integra modelos de lenguaje grandes (LLMs) en tareas de interacción con datos, proporcionando respuestas informadas por LLMs, mejorando la experiencia del usuario y la accesibilidad. Ofrece un marco de Multi-Agentes que aprovecha las capacidades especializadas de múltiples agentes para abordar efectivamente desafíos multifacéticos en el análisis de datos generativo. A diferencia de marcos anteriores, el marco de Multi-Agentes de DB-GPT archiva todo el historial de comunicación entre los agentes, mejorando significativamente la confiabilidad del contenido generado. Además, DB-GPT incorpora medidas de privacidad para proteger la información privada, asegurando interacciones de datos seguras. El documento enfatiza la importancia de marcos de multi-agentes agnósticos a la tarea para atender efectivamente una amplia gama de tareas de interacción con datos, una característica que distingue a DB-GPT de métodos anteriores. Además, DB-GPT aborda la necesidad de configuraciones sensibles a la privacidad en interacciones de datos potenciadas por LLM, un aspecto que ha sido poco investigado en esfuerzos previos. Estas características en conjunto posicionan a DB-GPT como una herramienta versátil y segura para mejorar las tareas de interacción con datos mediante la integración de LLMs y marcos de multi-agentes.
Q4. ¿Qué investigaciones relacionadas existen? ¿Cómo pueden ser categorizadas? ¿Quiénes son los investigadores notables en este campo sobre este tema?
¿Cuál es la clave de la solución mencionada en el documento? La investigación relacionada con las tareas de interacción de datos con modelos de lenguaje grandes (LLMs) ha sido explorada extensamente. Esta investigación puede ser categorizada en áreas como la mejora de las tareas de interacción con datos utilizando LLMs, la incorporación de razonamiento automatizado y procesos de decisión en interacciones de datos, y abordar preocupaciones de privacidad en interacciones de datos potenciadas por LLM. Investigadores notables en este campo incluyen a Siqiao Xue, Danrui Qi, Caigao Jiang, y otros colaboradores de diversas organizaciones como Ant Group, Alibaba Group, y JD Group. La solución clave propuesta en el documento implica el desarrollo de una biblioteca de Python de código abierto llamada DB-GPT, que apoya la interacción de datos mediante multi-agentes con arreglos flexibles y un diseño de sistema de cuatro capas para manejar tareas de interacción de datos complejas con consideraciones de privacidad.
Q5. ¿Cómo fueron diseñados los experimentos en el documento?
Los experimentos en el documento fueron diseñados para mostrar las capacidades de DB-GPT, una biblioteca de Python que integra modelos de lenguaje grandes (LLMs) en tareas tradicionales de interacción con datos. La configuración involucró utilizar una laptop conectada a Internet para acceder a DB-GPT de manera fluida con el servicio GPT de OpenAI, con opciones para modelos locales como Qwen y GLM. Los experimentos demostraron la capacidad de DB-GPT para realizar análisis de datos generativos al iniciar tareas a través de entradas en lenguaje natural, utilizando un marco de Multi-Agentes para generar estrategias y agentes especializados para tareas como crear gráficos de análisis de datos y agregarlos para la interacción del usuario.
Q6. ¿Cuál es el conjunto de datos utilizado para la evaluación cuantitativa? ¿Es el código de código abierto?
El conjunto de datos utilizado para la evaluación cuantitativa en el sistema DB-GPT no se menciona explícitamente en los contextos proporcionados. Sin embargo, el código para DB-GPT es de código abierto y está disponible en Github con más de 10.7k estrellas, permitiendo a los usuarios acceder y utilizarlo para sus propios propósitos.
Q7. ¿Proporcionan los experimentos y resultados en el documento un buen apoyo a las hipótesis científicas que deben ser verificadas? Por favor, analiza tanto como sea posible.
Los experimentos y resultados presentados en el documento proporcionan un apoyo sustancial a las hipótesis científicas que deben ser verificadas. El documento demuestra un enfoque de generación aumentada por recuperación para tareas de PLN intensivas en conocimiento, mostrando la efectividad del método propuesto. Al aprovechar la generación aumentada por recuperación, el sistema mejora la generación de respuestas al integrar resultados de recuperación de conocimiento durante el proceso de inferencia. Este enfoque mejora significativamente el proceso de generación de respuestas al incorporar información relevante recuperada de la base de conocimiento. Los resultados sugieren que el sistema integra efectivamente estrategias de recuperación y aprendizaje contextual interactivo para mejorar las respuestas generadas por el modelo de lenguaje. En general, los experimentos y resultados proporcionan evidencia sólida que apoya la efectividad del enfoque propuesto en abordar tareas de PLN intensivas en conocimiento.
Q8. ¿Cuáles son las contribuciones de este documento?
El documento presenta DB-GPT, una biblioteca de Python que integra modelos de lenguaje grandes (LLMs) en tareas de interacción con datos, mejorando la experiencia del usuario y la accesibilidad. Ofrece respuestas informadas por LLMs, permitiendo a los usuarios describir tareas en lenguaje natural y recibir salidas relevantes. Además, DB-GPT puede manejar tareas complejas como el análisis de datos generativos a través de un marco de Multi-Agentes y el Lenguaje de Expresión de Flujo de Trabajo Agente (AWEL). El diseño del sistema soporta el despliegue en entornos locales, distribuidos y en la nube, asegurando la privacidad y seguridad de los datos con el Marco de Gestión de Multi-modelos Orientado a Servicios (SMMF).
Q9. ¿Qué trabajo se puede continuar en profundidad?
Se puede realizar más investigación para mejorar las capacidades de los modelos de lenguaje grandes (LLMs) en tareas de interacción con datos, enfocándose particularmente en mejorar la comprensión y los insights proporcionados a los usuarios. Además, explorar el desarrollo de marcos de multi-agentes más agnósticos a la tarea para ampliar la gama de tareas que pueden manejar de manera efectiva sería beneficioso. Además, investigar y refinar la configuración sensible a la privacidad para la interacción de datos potenciados por LLM para garantizar la seguridad de los datos del usuario podría ser un área para trabajo continuado.