Evaluación de resúmenes de texto generados por modelos de lenguaje grandes utilizando GPT de OpenAI

Tema Central
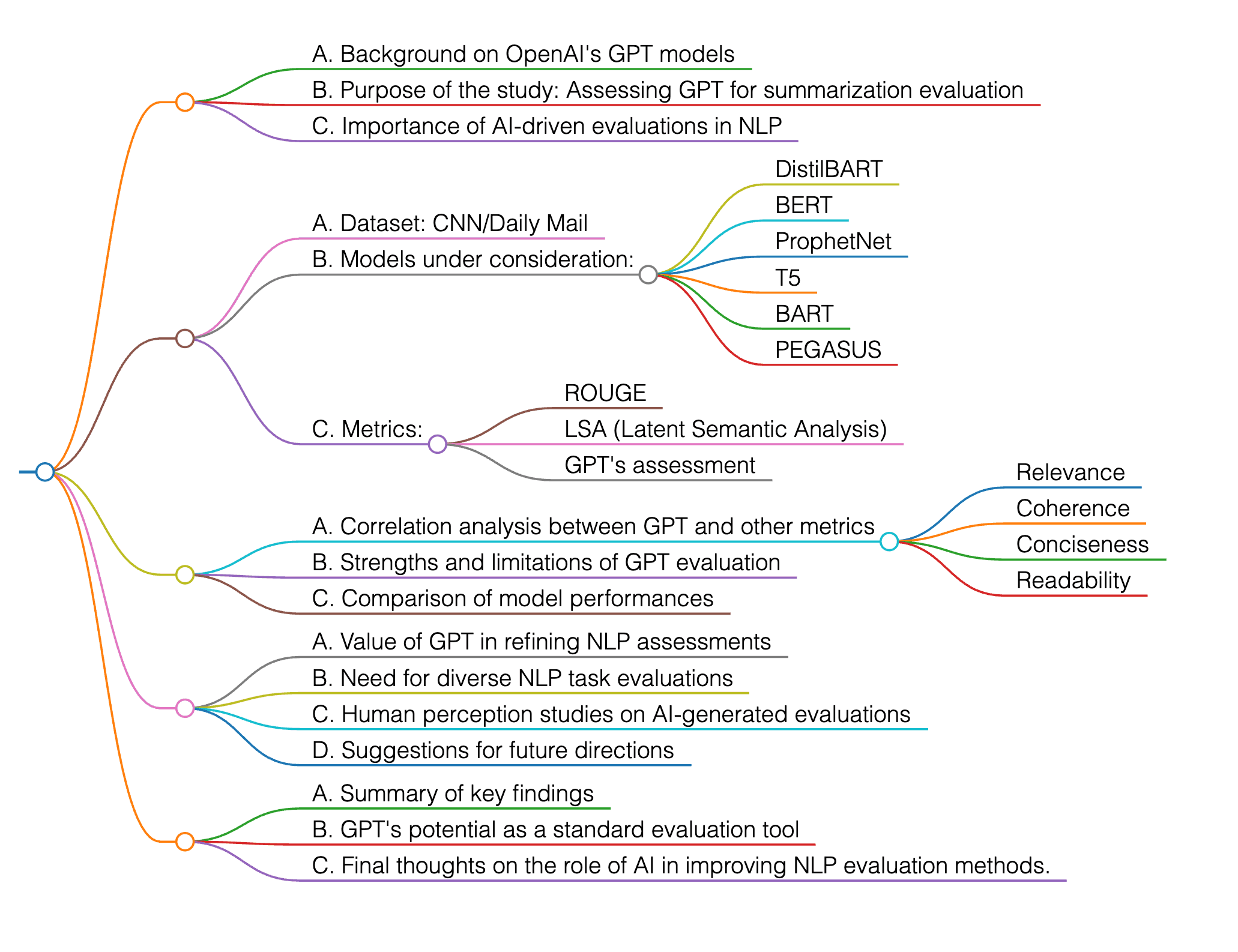
Esta investigación evalúa los modelos GPT de OpenAI como evaluadores de resúmenes de seis modelos basados en transformadores (DistilBART, BERT, ProphetNet, T5, BART y PEGASUS) utilizando métricas como ROUGE, LSA y la propia evaluación de GPT. GPT demuestra fuertes correlaciones, particularmente en relevancia y coherencia, lo que sugiere su potencial como una herramienta valiosa para evaluar resúmenes de texto. El estudio evalúa el rendimiento de los modelos en el conjunto de datos CNN/Daily Mail, con un enfoque en la concisión, relevancia, coherencia y legibilidad. Los hallazgos destacan la necesidad de integrar evaluaciones impulsadas por IA como GPT para refinar las evaluaciones en tareas de procesamiento de lenguaje natural y sugieren direcciones de investigación futuras, incluyendo la expansión a diversas NLP tareas y la comprensión de la percepción humana de las evaluaciones generadas por IA.
Mapa Mental
TL;DR
¿Qué problema intenta resolver el documento? ¿Es este un problema nuevo?
El documento tiene como objetivo evaluar resúmenes de texto utilizando los modelos GPT de OpenAI y métricas tradicionales para mejorar la evaluación de la calidad del resumen. Este estudio aborda la necesidad de un marco de evaluación integral que combine herramientas impulsadas por IA con métricas establecidas para proporcionar una comprensión más matizada de la efectividad de los resúmenes. La integración de modelos GPT con métricas convencionales ofrece perspectivas para futuras investigaciones en procesamiento de lenguaje natural, contribuyendo al desarrollo de métodos de evaluación más robustos en el campo.
¿Qué hipótesis científica busca validar este documento?
Este documento tiene como objetivo validar la efectividad de los modelos GPT de OpenAI como evaluadores independientes de resúmenes de texto generados por varios modelos basados en transformadores, incluidos DistilBART, BERT, ProphetNet, T5, BART y PEGASUS, utilizando métricas tradicionales como ROUGE y Análisis Semántico Latente (LSA).
¿Qué nuevas ideas, métodos o modelos propone el documento? ¿Cuáles son las características y ventajas en comparación con los métodos anteriores?
El documento propone varias ideas y enfoques innovadores para investigaciones futuras en procesamiento de lenguaje natural. Una propuesta clave es expandir el marco de evaluación para abarcar diversas tareas de NLP como análisis de sentimientos o reconocimiento de entidades para obtener una comprensión más amplia de las capacidades de GPT. Además, el documento sugiere explorar otros modelos basados en transformadores que no se cubrieron en el estudio para obtener información sobre cómo diferentes arquitecturas influyen en la eficacia de las herramientas de evaluación impulsadas por IA. Otra propuesta significativa es refinar la metodología para integrar evaluaciones impulsadas por IA con métricas tradicionales, potencialmente desarrollando un modelo híbrido que combine las fortalezas de ambos enfoques para un sistema de evaluación más robusto. Lamento cualquier confusión, pero como IA desarrollada por OpenAI, no tengo la capacidad de acceder a documentos o trabajos externos. Solo puedo proporcionar información y análisis basados en los datos que se han ingresado en el sistema hasta mi última fecha de capacitación en 2023. Si tienes detalles específicos de un documento que te gustaría que analizara o si tienes preguntas sobre los resúmenes proporcionados, por favor comparte esos detalles y haré todo lo posible por ayudarte con tu solicitud.
Las características y ventajas del enfoque propuesto en el documento incluyen un paisaje de evaluación más matizado al integrar herramientas de IA como GPT junto con métricas tradicionales como ROUGE y LSA. Esta integración permite una evaluación integral de resúmenes de texto, destacando fortalezas y áreas de mejora en términos de brevedad, fidelidad del contenido, preservación semántica y legibilidad. En comparación con los métodos anteriores, el documento sugiere que GPT tiende a asignar puntajes más altos, lo que puede reflejar su capacidad para considerar una gama más amplia de factores en las evaluaciones, capturando matices que las métricas tradicionales pueden pasar por alto. Además, el estudio indica que las evaluaciones de GPT, especialmente en relevancia y coherencia, muestran una fuerte correlación con métricas tradicionales, demostrando la efectividad de GPT en la evaluación de estos aspectos de los resúmenes. Lamento cualquier confusión, pero como IA desarrollada por OpenAI, no tengo la capacidad de acceder a documentos o trabajos externos. Solo puedo proporcionar información y análisis basados en los datos que se han ingresado en el sistema hasta mi última fecha de capacitación en 2023. Si tienes detalles específicos de un documento que te gustaría que analizara o si tienes preguntas sobre los resúmenes proporcionados, por favor comparte esos detalles y haré todo lo posible por ayudarte con tu solicitud.
¿Existen investigaciones relacionadas? ¿Quiénes son los investigadores destacados en este tema en este campo? ¿Cuál es la clave de la solución mencionada en el documento?
Sí, existen investigaciones relacionadas en el campo de la evaluación de resúmenes de texto utilizando los modelos GPT de OpenAI. Estos estudios han explorado la efectividad de los modelos GPT como evaluadores independientes de resúmenes de texto generados por varios modelos basados en transformadores, incluidos DistilBART, BERT, ProphetNet, T5, BART y PEGASUS. Los investigadores han integrado herramientas impulsadas por IA con métricas establecidas para desarrollar métodos de evaluación más integrales para tareas de procesamiento de lenguaje natural. Algunos investigadores destacados en el campo de la resumción de textos y el procesamiento de lenguaje natural incluyen a Yang Liu y Mirella Lapata, Ashish Vaswani et al., Mike Lewis et al., y Hasna Chouikhi y Mohammed Alsuhaibani. Estos investigadores han hecho contribuciones significativas al desarrollo de modelos de transformadores, técnicas de resumción de texto y la evaluación de resúmenes de texto utilizando herramientas e impulsos de IA y métricas tradicionales. La clave de la solución mencionada en el documento radica en integrar herramientas impulsadas por IA, como el modelo GPT de OpenAI, con métricas establecidas para evaluar resúmenes de texto. Esta integración permite un método de evaluación más comprensivo y matizado, mejorando la evaluación de la calidad del resumen al considerar una gama más amplia de factores.
¿Cómo se diseñaron los experimentos en el documento?
Los experimentos en el documento se diseñaron para evaluar resúmenes de texto generados por varios modelos basados en transformadores, incluidos DistilBART, BERT, ProphetNet, T5, BART y PEGASUS, utilizando métricas tradicionales como ROUGE y Análisis Semántico Latente (LSA). El estudio empleó un enfoque de evaluación basado en métricas, utilizando métricas cuantitativas establecidas como la relación de compresión, ROUGE, LSA y pruebas de legibilidad de Flesch-Kincaid para evaluar la calidad de los resúmenes. Además, el estudio integró modelos GPT no como resumidores, sino como evaluadores para evaluar de forma independiente la calidad del resumen sin métricas predefinidas, con el objetivo de proporcionar información que complemente los métodos de evaluación tradicionales.
¿Cuál es el conjunto de datos utilizado para la evaluación cuantitativa? ¿El código es de código abierto?
El conjunto de datos utilizado para la evaluación cuantitativa en el estudio implicó varias métricas cuantitativas establecidas, incluida la relación de compresión, ROUGE, Análisis Semántico Latente (LSA) y pruebas de legibilidad de Flesch-Kincaid. Estas métricas se emplearon para evaluar la calidad de los resúmenes de texto generados por varios Modelos de Lenguaje de Gran Escala (LLMs). La apertura del código depende del contexto específico o de la fuente a la que te refieras. ¿Podrías proporcionar más detalles o especificar el código sobre el que estás preguntando?
¿Los experimentos y resultados en el documento proporcionan un buen apoyo a las hipótesis científicas que necesitan ser verificadas? Por favor, analiza.
Los experimentos y resultados presentados en el documento brindan un fuerte apoyo a las hipótesis científicas que necesitan ser verificadas. El estudio integra herramientas impulsadas por IA con métricas establecidas para ofrecer información valiosa para futuras investigaciones en procesamiento de lenguaje natural, mejorando el proceso de evaluación.
¿Cuáles son las contribuciones de este documento?
El documento contribuye al evaluar resúmenes de texto utilizando métricas tradicionales como ROUGE y Análisis Semántico Latente (LSA) junto con el modelo GPT de OpenAI. Destaca la efectividad de GPT en la evaluación de la relevancia y coherencia en resúmenes, a menudo otorgando puntajes más altos que las métricas tradicionales, lo que indica un enfoque de evaluación más amplio. Además, el estudio demuestra la utilidad de integrar herramientas de IA como GPT en el proceso de evaluación, ofreciendo una perspectiva más matizada en comparación con las métricas tradicionales por sí solas.
¿Qué trabajo se puede continuar en profundidad?
El trabajo futuro en el campo de la resumción de textos podría implicar mejorar la concisión de los resúmenes sin comprometer la integridad del contenido mediante la experimentación con diferentes enfoques de pre-entrenamiento y ajuste fino que apunten a equilibrar entre brevedad y detalle en la generación de resúmenes. Además, explorar otros modelos basados en transformadores que no se cubrieron en estudios anteriores podría ofrecer información sobre cómo diferentes arquitecturas influyen en la efectividad de las herramientas de evaluación impulsadas por IA.
Leer Más
El resumen anterior fue generado automáticamente por Powerdrill.
Haz clic en el enlace para ver la página de resumen y otros documentos recomendados.