Una revisión de la literatura y un marco para la evaluación humana de modelos de lenguaje generativos de gran escala en el cuidado de la salud

Tema Central
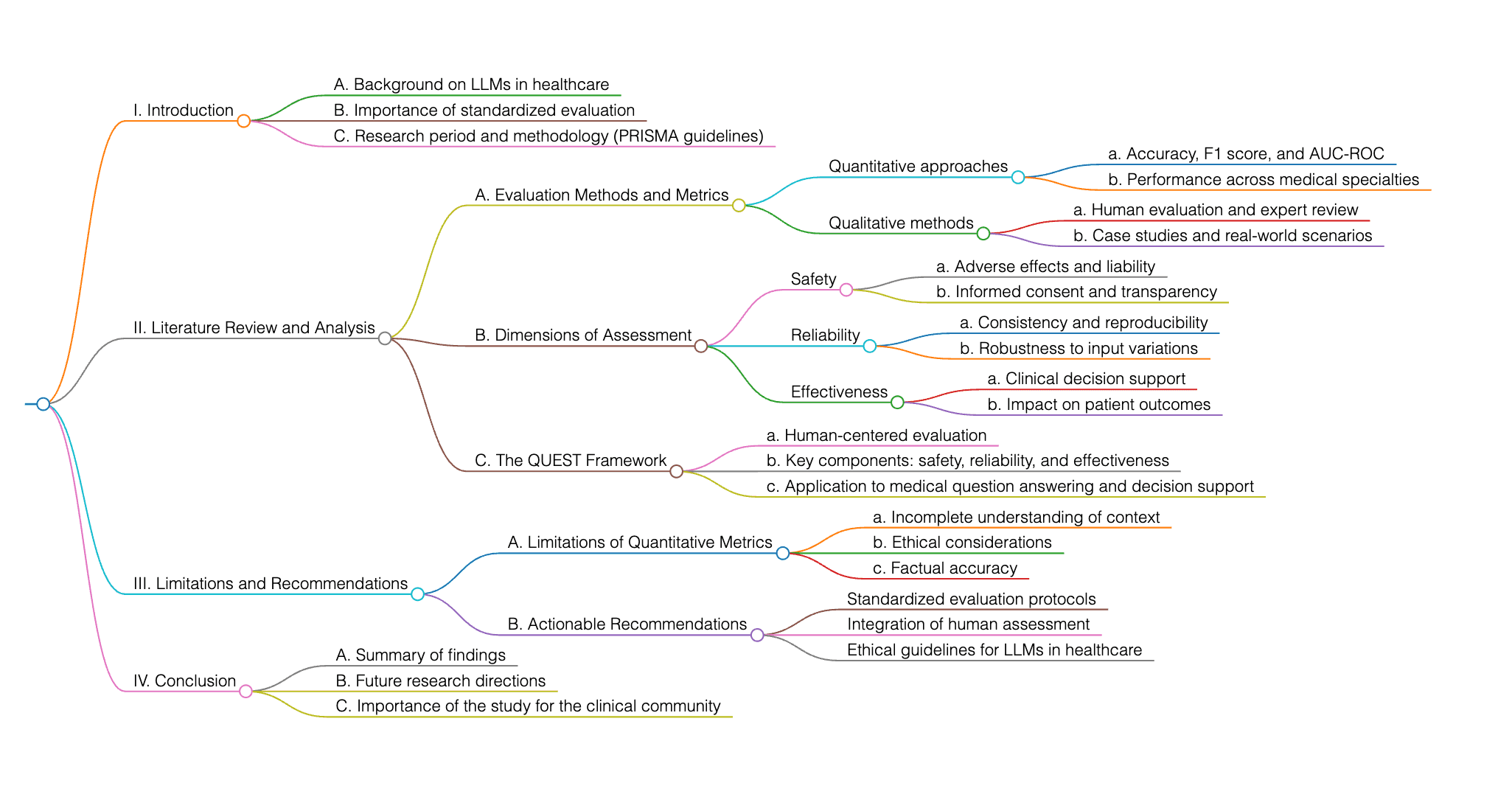
Este estudio examina la evaluación de grandes modelos de lenguaje (LLMs) en el cuidado de la salud, con un enfoque en enfoques estandarizados debido a la complejidad de evaluar contenido médico generado por IA. Los investigadores realizaron una revisión integral desde 2018 hasta 2024, utilizando las directrices PRISMA, para analizar métodos de evaluación, métricas y dimensiones en diversas especialidades médicas. El marco propuesto QUEST destaca la necesidad de una evaluación humana para garantizar la seguridad, la fiabilidad y la efectividad, particularmente en áreas como la respuesta a preguntas médicas y el apoyo a la decisión. El estudio tiene como objetivo proporcionar un marco para la evaluación estandarizada, abordar las lagunas en la investigación actual y ofrecer recomendaciones prácticas para la comunidad clínica para mejorar la confiabilidad de los LLMs en las aplicaciones de salud. También se discuten las limitaciones de las métricas cuantitativas y la importancia de la evaluación humana para garantizar la precisión fáctica y las consideraciones éticas.
Mapa Mental
Resumen
¿Qué problema intenta resolver el documento? ¿Es este un problema nuevo?
El documento busca abordar la limitación de depender únicamente de métricas de evaluación cuantitativas, como la precisión y las puntuaciones F-1, que pueden no validar completamente la precisión del texto generado y pueden no capturar el entendimiento detallado necesario para una evaluación rigurosa en la práctica clínica. Enfatiza la importancia de las evaluaciones cualitativas por parte de evaluadores humanos como el estándar de oro para garantizar que las salidas del modelo de lenguaje cumplan con los estándares de fiabilidad, precisión fáctica, seguridad y cumplimiento ético. Para determinar si esto es un problema nuevo, necesitamos más contexto o información específica relacionada con el problema al que te refieres.
¿Qué hipótesis científica busca validar este documento?
Este documento tiene como objetivo validar la hipótesis relacionada con la significancia estadística de las diferencias observadas entre el rendimiento de un LLM y un punto de referencia, que normalmente se evalúa utilizando el valor P.
¿Qué nuevas ideas, métodos o modelos propone el documento? ¿Cuáles son las características y ventajas en comparación con métodos anteriores?
El documento propone directrices para la evaluación humana de grandes modelos de lenguaje (LLMs) para abordar los desafíos en la evaluación de estos modelos, incluidas las limitaciones en la escala, el tamaño de muestra y las medidas de evaluación. Además, el estudio busca cerrar la brecha entre las promesas de los LLMs y los requisitos en la atención sanitaria proponiendo un marco integral para la evaluación humana. Estoy feliz de ayudar con tu pregunta. Sin embargo, necesito información o contexto más específico sobre el documento al que te refieres para poder proporcionar un análisis detallado. Por favor, proporcióname el título del documento, el autor o un breve resumen del contenido para que pueda asistirte mejor.
El marco propuesto para la evaluación humana de grandes modelos de lenguaje (LLMs) enfatiza la importancia de las evaluaciones cualitativas por parte de evaluadores humanos, que son consideradas el estándar de oro para garantizar la fiabilidad, la precisión fáctica, la seguridad y el cumplimiento ético en las salidas de los LLM. Este enfoque contrasta con el uso predominante de métricas automatizadas en la literatura actual, destacando la necesidad de un análisis más completo de las metodologías de evaluación humana en aplicaciones sanitarias. El marco tiene como objetivo abordar las limitaciones de las métricas de evaluación cuantitativa al centrarse en las evaluaciones cualitativas, que son esenciales para una evaluación rigurosa en la práctica clínica.
¿Existen investigaciones relacionadas? ¿Quiénes son los investigadores destacados en este campo? ¿Cuál es la clave para la solución mencionada en el documento?
Sí, existen varios estudios de investigación relacionados disponibles en el campo. Se han realizado estudios para evaluar el rendimiento de modelos de lenguaje como ChatGPT en varias especialidades médicas, incluyendo propuestas diagnósticas y determinaciones clínicas. Estos estudios han empleado pruebas estadísticas como pruebas T, exámenes de chi-cuadrado y pruebas de McNemar para evaluar la precisión y fiabilidad de la evidencia médica compilada por modelos de IA en comparación con los profesionales de la salud. Además, hay discusiones sobre las mejores prácticas en el diseño y la monitorización de evaluaciones humanas, limitaciones y estudios de caso en diferentes especialidades médicas. Investigadores destacados en este campo incluyen a Sinha, R. K., Roy, A. D., Kumar, N., Mondal, H. y Sinha, R. quienes exploraron la aplicabilidad de ChatGPT para ayudar a resolver problemas de orden superior en patología. Además, Ayers et al. realizaron un estudio comparando las respuestas de ChatGPT con las proporcionadas por médicos en los hilos de "Ask Doctors" en Reddit, centrándose en la calidad y relevancia del consejo. Estos investigadores han contribuido significativamente a la evaluación y aplicación de modelos de IA en entornos de salud. La clave de la solución mencionada en el documento radica en el desarrollo de marcos de evaluación apropiados que se alineen con los valores humanos, especialmente en el contexto de las aplicaciones de modelos de lenguaje (LLM) en medicina.
¿Cómo se diseñaron los experimentos en el documento?
Los experimentos en el documento se diseñaron comparando las respuestas de ChatGPT con las proporcionadas por médicos en los hilos de "Ask Doctors" en Reddit, utilizando pruebas de chi-cuadrado para determinar diferencias en la calidad y relevancia del consejo. Los estudios también consideraron probar modelos de lenguaje (LLMs) en escenarios controlados y del mundo real para evaluar su rendimiento.
¿Cuál es el conjunto de datos utilizado para evaluación cuantitativa? ¿El código es de código abierto?
El conjunto de datos utilizado para evaluación cuantitativa en aplicaciones de salud a menudo incluye métricas como la precisión, las puntuaciones F-1 y el área bajo la curva de la característica operativa del receptor (AUCROC). Estas métricas se emplean comúnmente para evaluar el rendimiento de los modelos de lenguaje (LLMs) en varios contextos médicos, pero pueden no capturar completamente la comprensión matizada requerida para una evaluación rigurosa en la práctica clínica. El código no es de código abierto, ya que se menciona que modelos de código abierto como Llama de Meta no se encuentran entre los modelos principales utilizados en los estudios revisados.
¿Proporcionan los experimentos y resultados del documento un buen soporte para las hipótesis científicas que necesitan ser verificadas? Por favor analiza.
Los documentos de investigación presentan una variedad de experimentos y resultados relacionados con modelos de lenguaje en el ámbito sanitario. Por ejemplo, Tang et al. emplearon una prueba T para comparar la corrección de la evidencia médica compilada por ChatGPT contra los profesionales de salud. Además, Ayers et al. compararon las respuestas de ChatGPT con las proporcionadas por médicos en los hilos de "Ask Doctors" en Reddit usando pruebas de chi-cuadrado para evaluar la calidad y relevancia del consejo. Estos experimentos tenían como objetivo evaluar el rendimiento y las capacidades de los modelos de lenguaje en contextos médicos. Las hipótesis científicas presentadas en documentos de investigación pueden variar según el enfoque y los objetivos del estudio. Por ejemplo, algunos estudios pueden buscar evaluar el rendimiento de los modelos de lenguaje (LLMs) en tareas o escenarios específicos, probando la significancia estadística en las diferencias observadas. Otros pueden comparar las respuestas de los LLM con las de expertos humanos para evaluar la calidad y relevancia, utilizando pruebas estadísticas como chi-cuadrado para identificar diferencias notables. Además, la investigación puede investigar la fiabilidad y utilidad de las respuestas generadas por LLM en varios dominios, como la investigación científica o las aplicaciones clínicas. Para proporcionar un análisis preciso, necesitaría más información específica sobre el documento, como el título, autores, pregunta de investigación, metodología y hallazgos clave. Esta información me ayudaría a evaluar la calidad de los experimentos y resultados en relación con las hipótesis científicas que se están probando. No dudes en proporcionar más detalles para que pueda asistirte más.
¿Cuáles son las contribuciones de este documento?
Las contribuciones de este documento incluyen conceptualizar, diseñar y organizar el estudio, analizar los resultados y escribir, revisar y revisar el documento por T.Y.C.T. y S.S. Además, S.K., A.V.S., K.P., K.R.M., H.O. y X.W. contribuyeron analizando los resultados y escribiendo, revisando y revisando el documento. Además, S.V., S.F., P.M., G.C., C.S. y Y.P. participaron en la redacción, revisión y revisión del documento.
¿Qué trabajo se puede continuar en profundidad?
Se puede realizar un trabajo más profundo en varias áreas, como explorar dimensiones de evaluación humana en diferentes especialidades médicas, discutir las mejores prácticas en el diseño y la monitorización de evaluaciones humanas, abordar limitaciones y métodos para superarlas, y proporcionar estudios de caso en diversas tareas y especialidades médicas.
Leer Más
El resumen anterior fue generado automáticamente por Powerdrill.
Haga clic en el enlace para ver la página de resumen y otros documentos recomendados.