Contextual Knowledge Sharing in Multi-Agent Reinforcement Learning with Decentralized Communication and Coordination
Hung Du, Srikanth Thudumu, Hy Nguyen, Rajesh Vasa, Kon Mouzakis·January 26, 2025
Summary
A Decentralized Multi-Agent Reinforcement Learning framework integrates goal and time awareness for efficient exploration and knowledge sharing in complex tasks. It enables agents to exclude irrelevant peers, retrieve relevant observations, and share knowledge based on goals, enhancing performance in fully decentralized settings. Evaluated in a grid world with dynamic obstacles, the approach significantly improves agents' performance.
Introduction
Background
Overview of multi-agent systems
Challenges in decentralized environments
Importance of goal and time awareness in reinforcement learning
Objective
To present a novel decentralized multi-agent reinforcement learning framework that integrates goal and time awareness for efficient exploration and knowledge sharing
Method
Data Collection
Techniques for gathering data in decentralized settings
Data Preprocessing
Methods for processing data to enhance learning efficiency
Agent Interaction and Learning
Mechanisms for agents to communicate and learn from each other
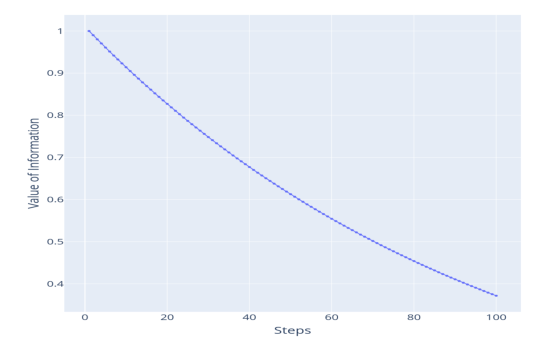
Integration of goal and time awareness in learning algorithms
Evaluation
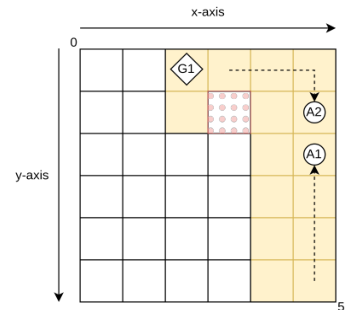
Experimental setup in a grid world with dynamic obstacles
Metrics for assessing performance improvement
Results
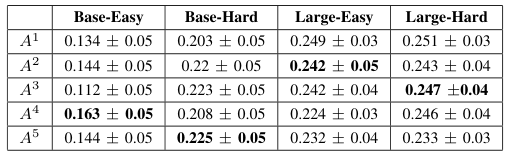
Performance Metrics
Comparison of performance with and without the proposed framework
Observations and Insights
Detailed analysis of agent behavior and learning outcomes
Conclusion
Summary of Contributions
Recap of the framework's unique features and benefits
Future Work
Potential extensions and applications of the framework
Implications
Impact on multi-agent systems and reinforcement learning research
Basic info
papers
artificial intelligence
multiagent systems
Advanced features