AquaticCLIP: A Vision-Language Foundation Model for Underwater Scene Analysis
Basit Alawode, Iyyakutti Iyappan Ganapathi, Sajid Javed, Naoufel Werghi, Mohammed Bennamoun, Arif Mahmood·February 03, 2025
Summary
A novel vision-language model, AquaticCLIP, addresses aquatic biodiversity preservation through unsupervised learning for tasks like segmentation, classification, detection, and counting without ground-truth annotations. It features a prompt-guided vision encoder and a vision-guided language mechanism, optimized through contrastive pre-training. AquaticCLIP outperforms existing methods in robustness and interpretability for underwater computer vision tasks, setting a new benchmark.
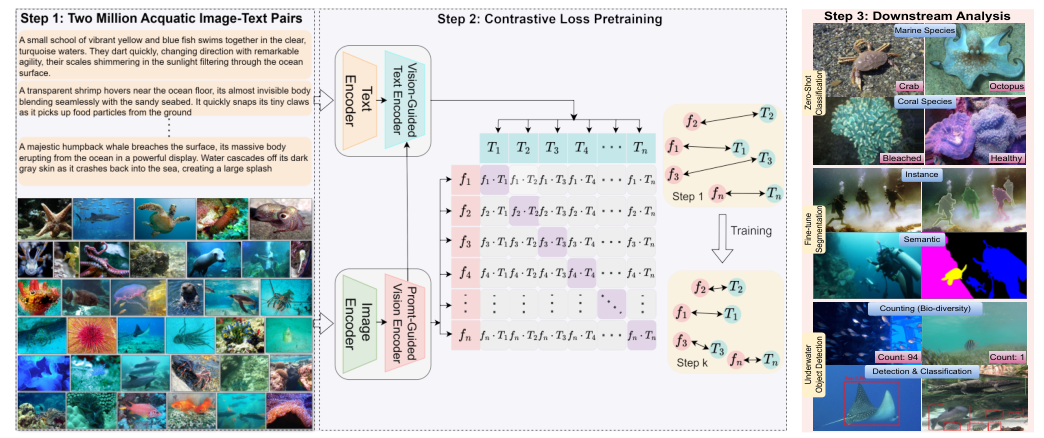
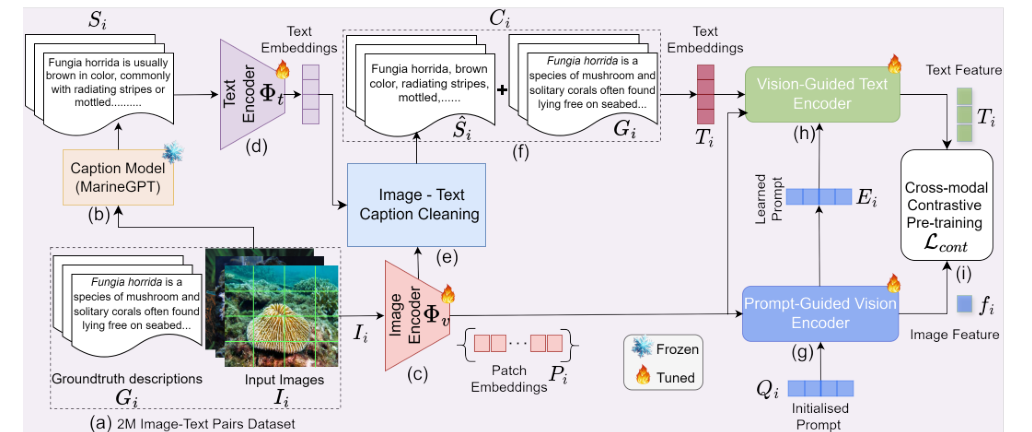
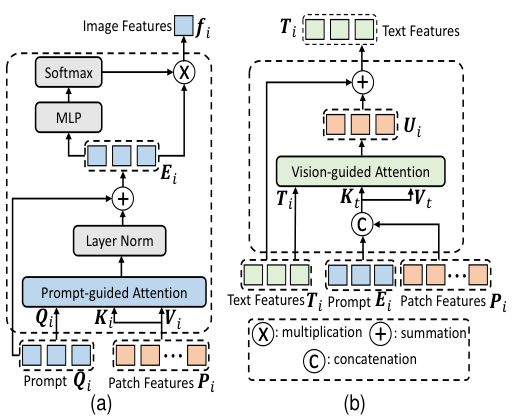







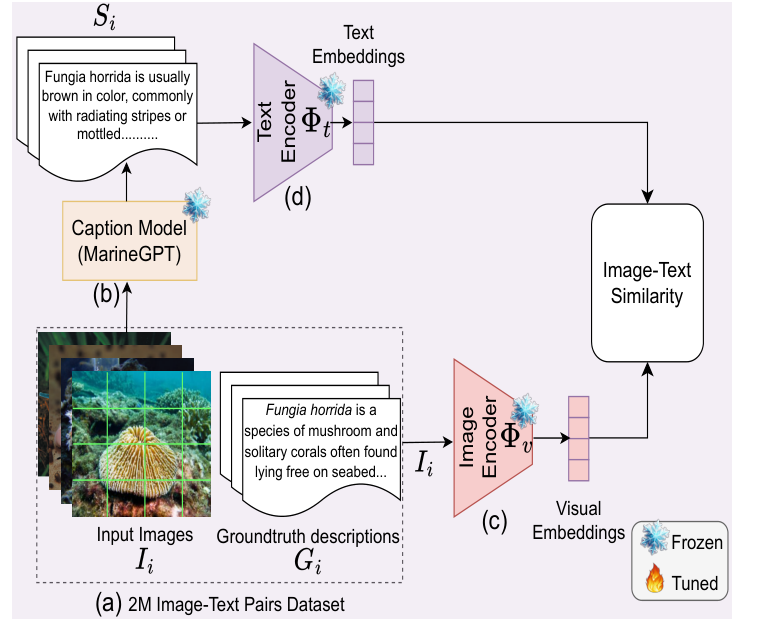
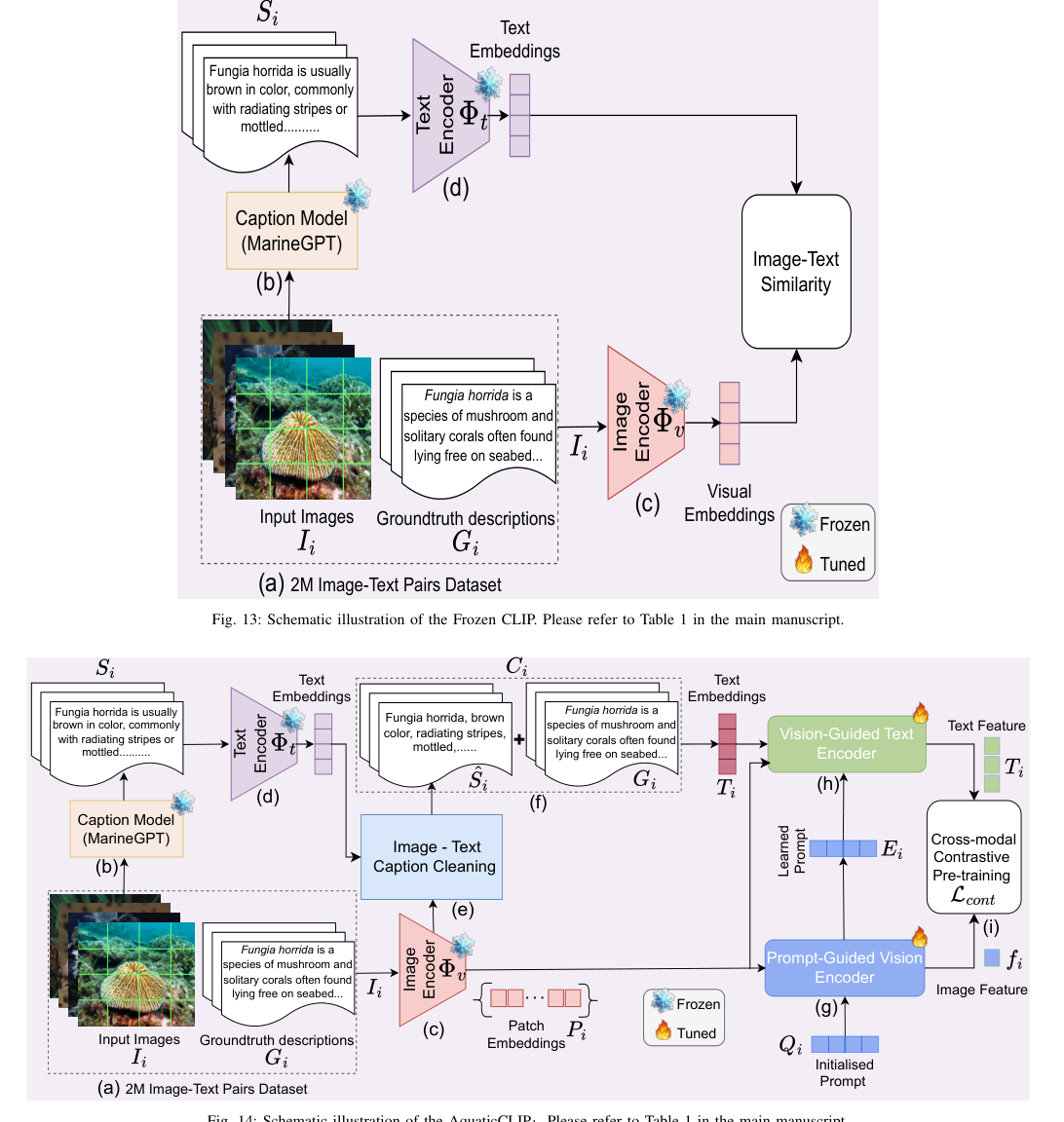
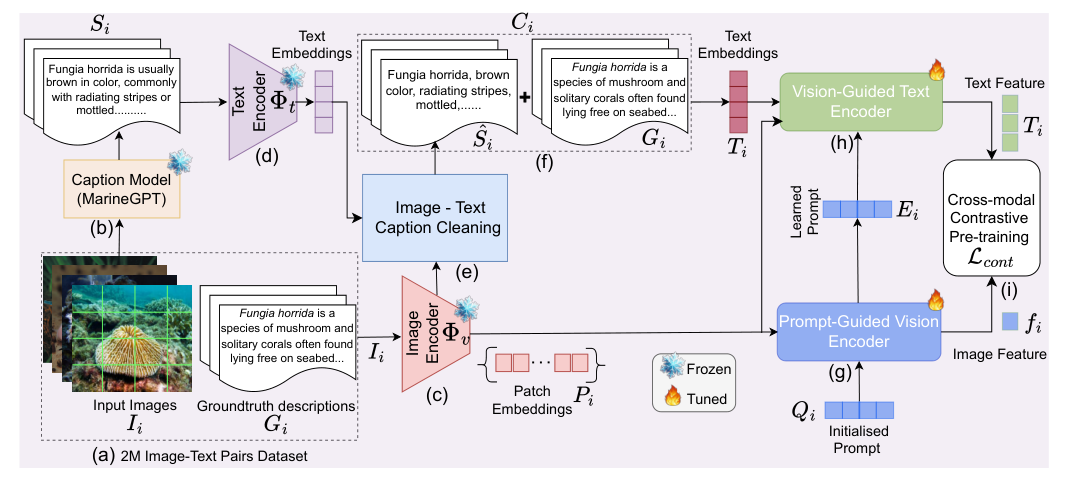
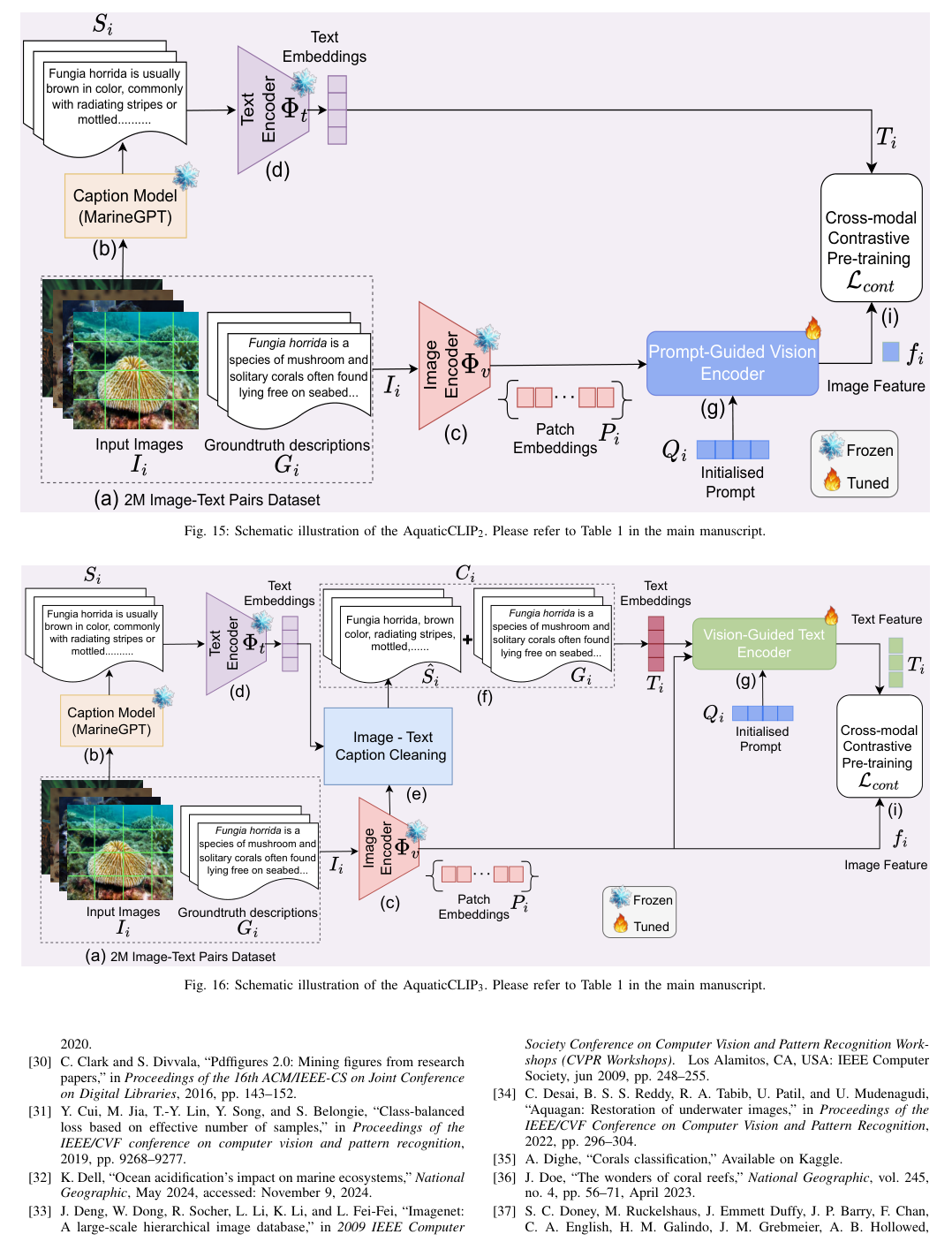
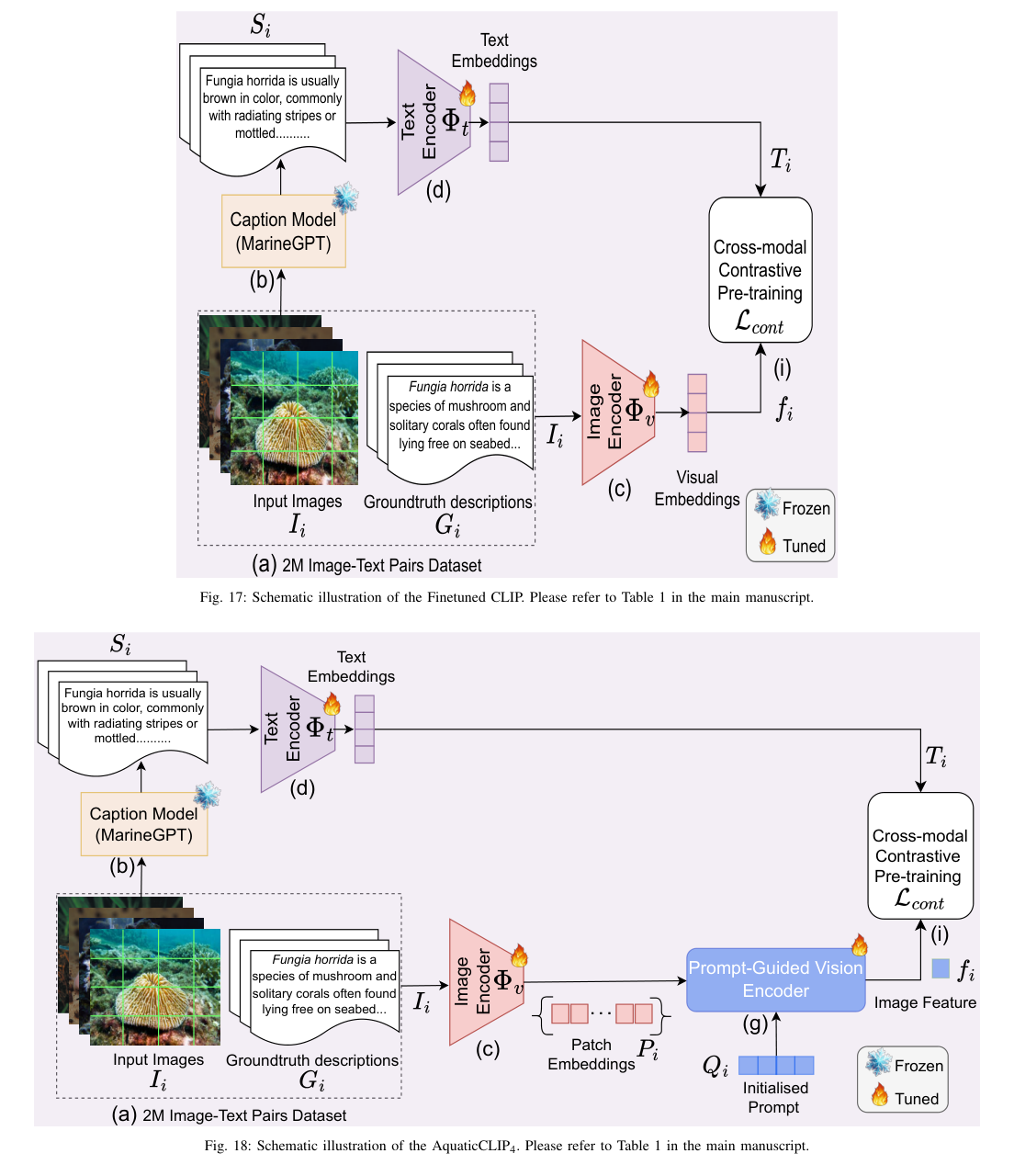
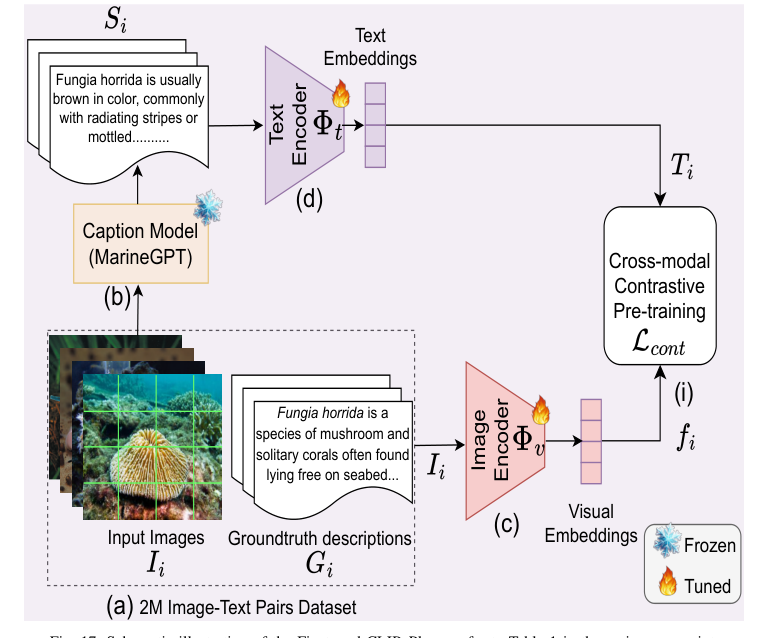
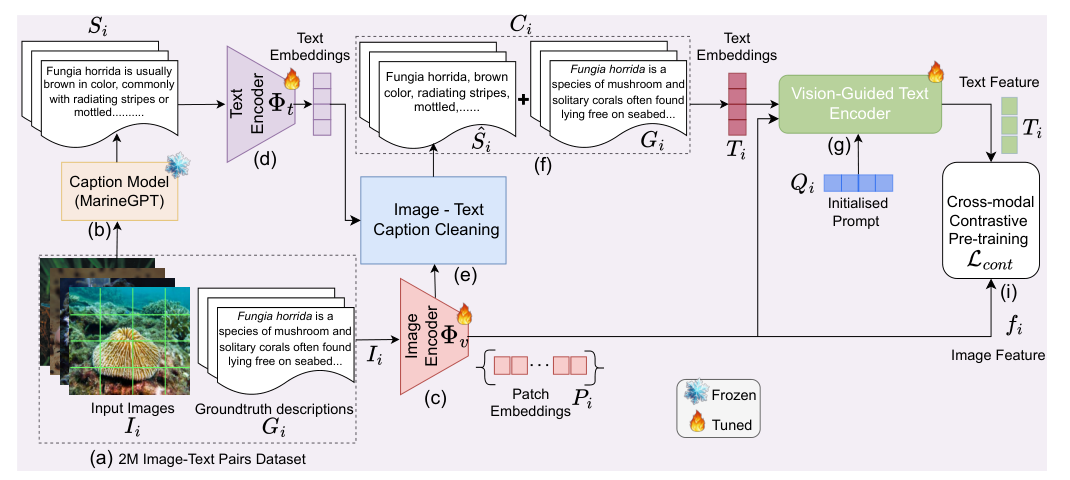

Introduction
Background
Overview of aquatic biodiversity and its importance
Challenges in underwater computer vision
Current limitations of existing vision-language models
Objective
To introduce AquaticCLIP, a novel vision-language model designed for aquatic biodiversity preservation
Highlighting its unsupervised learning capabilities for tasks such as segmentation, classification, detection, and counting without ground-truth annotations
Method
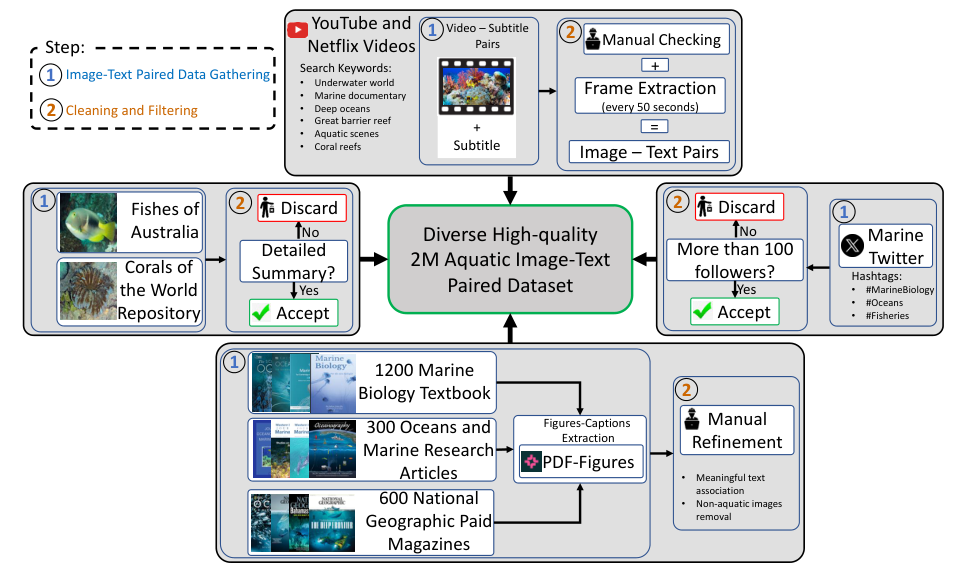
Data Collection
Sources of underwater data for training and testing
Characteristics of the collected data
Data Preprocessing
Techniques used for data cleaning and augmentation
Handling of missing or noisy data
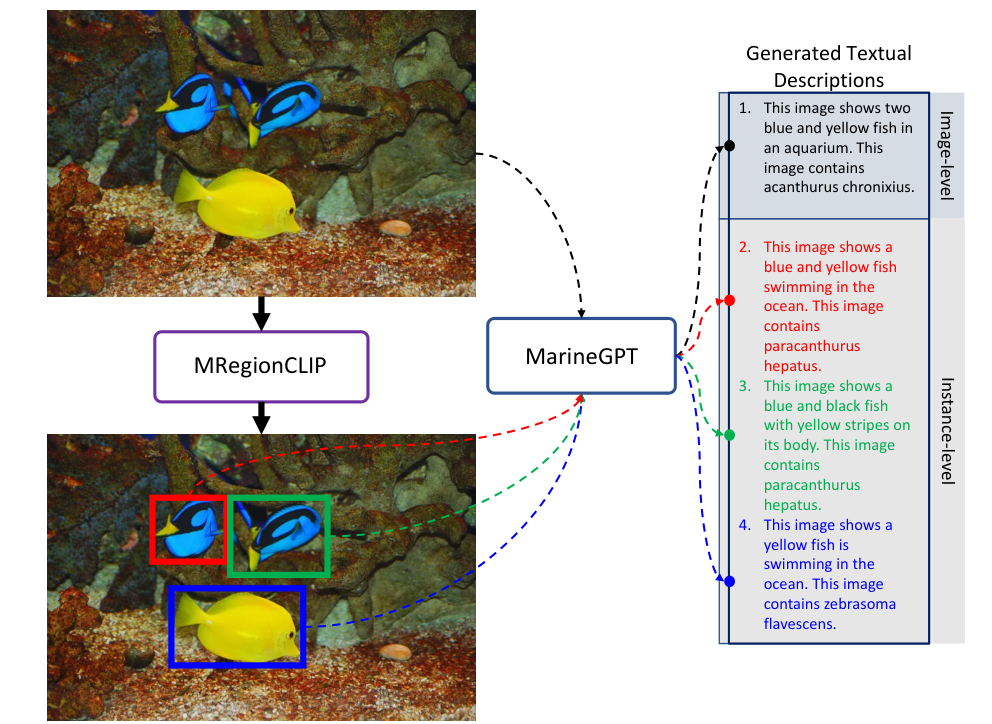
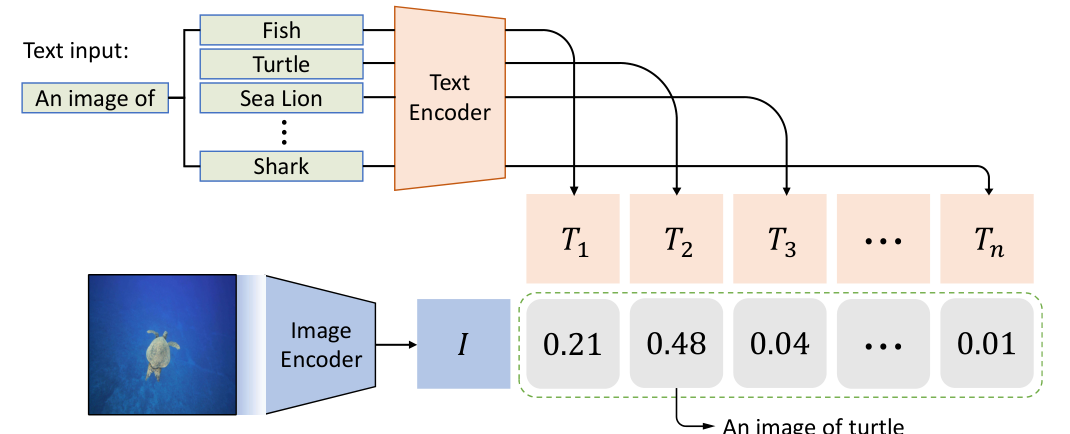
Model Architecture
Description of the prompt-guided vision encoder
Explanation of the vision-guided language mechanism
Contrastive Pre-Training
Overview of the pre-training process
Benefits of contrastive learning in enhancing model performance
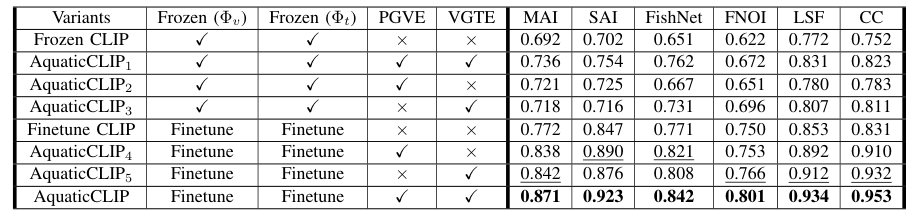
Results
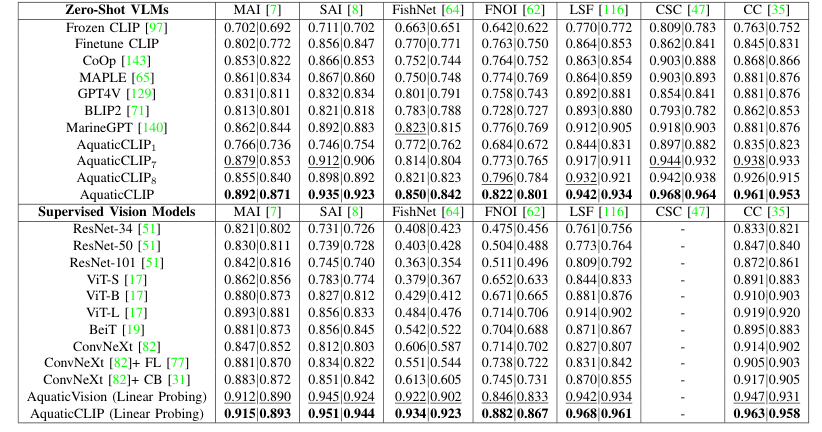
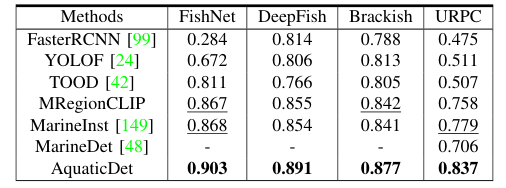
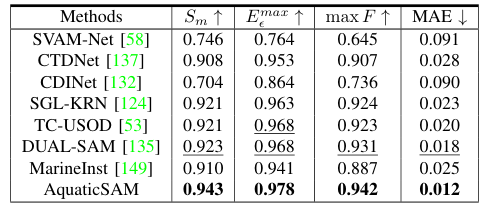
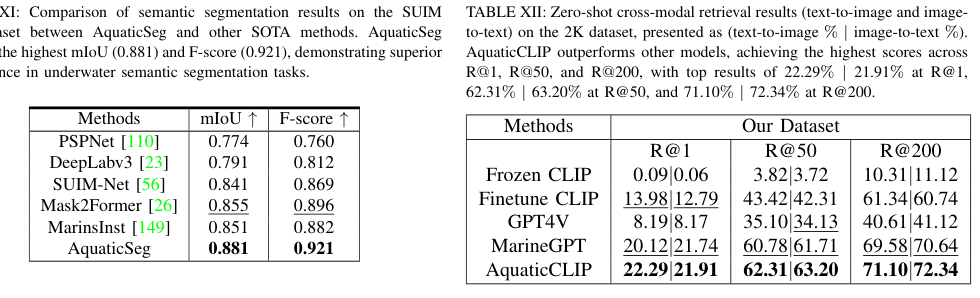
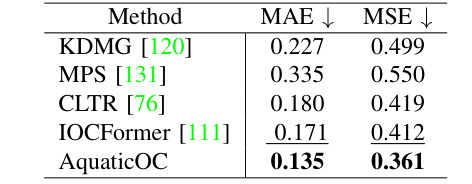
Performance Evaluation
Comparison with existing methods in terms of robustness and interpretability
Metrics used for underwater computer vision tasks
Benchmark Setting
Discussion on how AquaticCLIP sets a new benchmark for underwater computer vision
Conclusion
Future Directions
Potential improvements and extensions of AquaticCLIP
Impact on Aquatic Biodiversity Preservation
Expected outcomes and implications for conservation efforts
Summary
Recap of AquaticCLIP's contributions to the field of underwater computer vision
Basic info
papers
computer vision and pattern recognition
artificial intelligence
Advanced features