What You See Is Not Always What You Get: An Empirical Study of Code Comprehension by Large Language Models
Bangshuo Zhu, Jiawen Wen, Huaming Chen·December 11, 2024
Summary
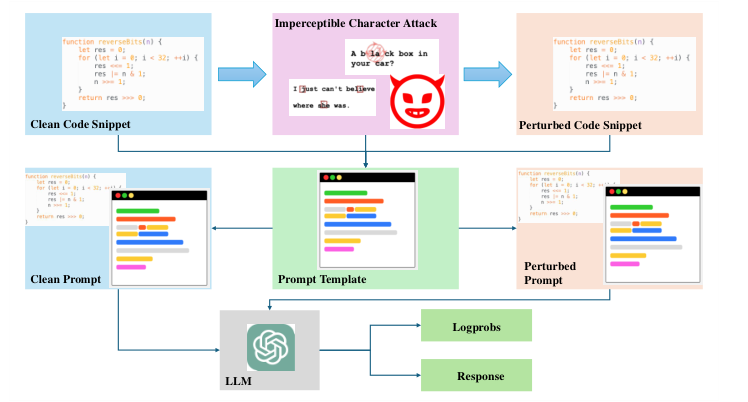
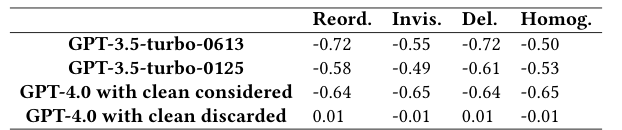
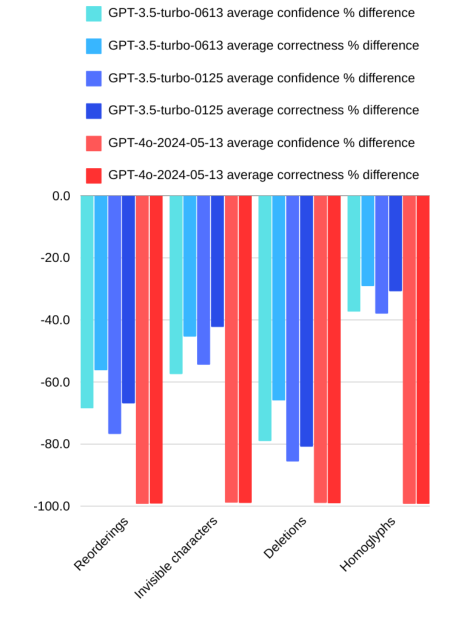
The study investigates large language models' vulnerability to imperceptible character attacks, affecting code analysis and comprehension tasks. It compares two generations of ChatGPT, revealing a strong negative correlation between perturbation and performance outcomes in the recent ChatGPT, suggesting potential improvements in model robustness. The research contributes to understanding LLMs' capabilities and vulnerabilities in coding tasks, highlighting the need for further research on creating LLMs that can handle perturbations without compromising performance.

Advanced features