Timeline and Boundary Guided Diffusion Network for Video Shadow Detection
Haipeng Zhou, Honqiu Wang, Tian Ye, Zhaohu Xing, Jun Ma, Ping Li, Qiong Wang, Lei Zhu·August 21, 2024
Summary
The paper introduces the Timeline and Boundary Guided Diffusion (TBGDiff) network for Video Shadow Detection (VSD), addressing inefficiencies in temporal learning and the lack of shadow characteristic consideration in existing methods. TBGDiff features a Dual Scale Aggregation (DSA) module for improved temporal understanding, a Shadow Boundary Aware Attention (SBAA) module to utilize edge contexts, and a Space-Time Encoded Embedding (STEE) for temporal guidance in the Diffusion model. These components enable the model to capture both temporal information and shadow properties, outperforming state-of-the-art methods in extensive experiments. The authors release the codes, weights, and results on GitHub.
TBGDiff utilizes Diffusion models for the first time in video shadow detection, addressing complex real-world scenarios by incorporating temporal information and boundary contexts. It proposes a Dual Scale Aggregation (DSA) module to aggregate temporal features, a Shadow Boundary-Aware Attention (SBAA) to guide the model towards shadow characteristics, and three different temporal guidance strategies for Diffusion models. The Space-Time Encoded Embedding (STEE) enables the model to capture representation from a timeline sequence, enhancing its performance. TBGDiff outperforms state-of-the-art methods, demonstrating the effectiveness of the approach.
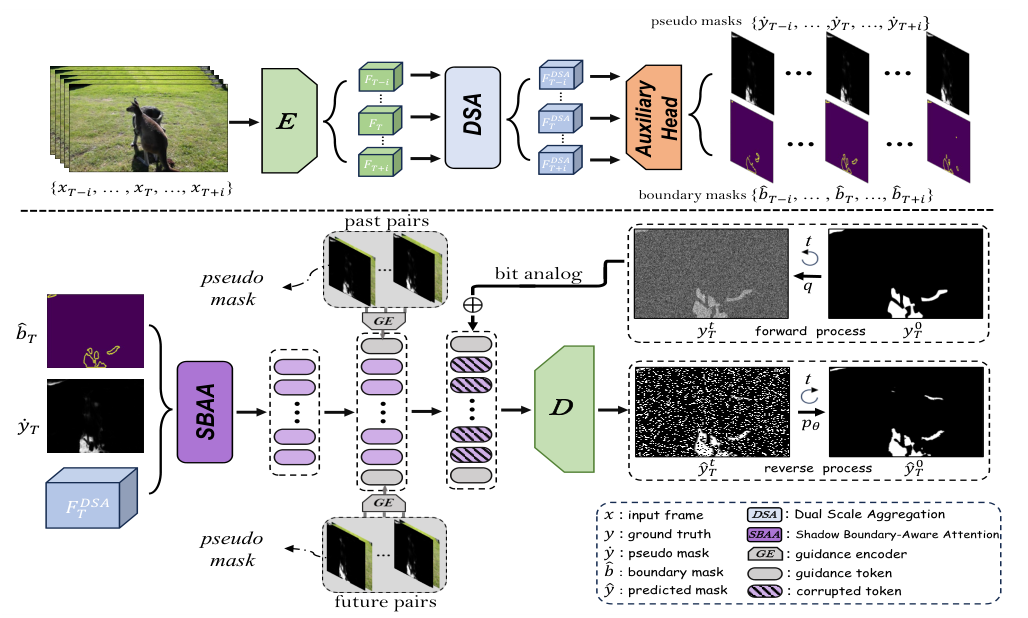
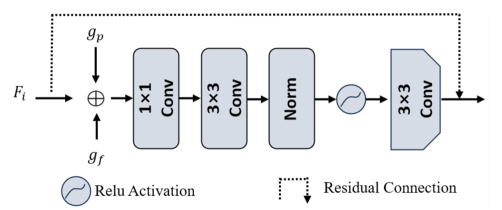
The paper introduces the Timeline and Boundary Guided Diffusion Network (TBGDiff) for video shadow detection, processing 2i+1 frames simultaneously. It uses an encoder to extract temporal-agnostic features, which are then aggregated through the Dual Scale Aggregation (DSA) module, considering both short-term and long-term temporal scales to mitigate temporal bias. The aggregated features are decoded into pseudo masks and boundary masks by an Auxiliary Head. The Shadow Boundary-Aware Attention (SBAA) module further explores shadow characteristics using the boundary mask, pseudo mask, and aggregated feature. A guidance encoder yields Space-Time Encoded Embedding (STEE) for the diffusion process, utilizing timeline temporal information. The paper employs a bit analog strategy to embed noise and conduct the denoise process, predicting the final shadow masks.
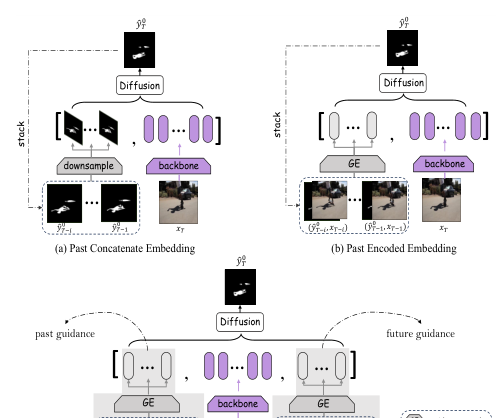
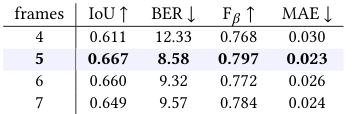
The paper introduces a novel approach for video shadow detection using a timeline and boundary guided diffusion network. Instead of predicting noise, the model predicts masks directly, utilizing robust representation and bit analog strategies. The diffusion's operation is detailed in supplementary material, and ablation studies on hyperparameters are provided. The guidance mechanism is crucial, with three methods proposed: Past Concatenate Embedding (PCE), Past Encoded Embedding (PEE), and Space-Time Encoded Embedding (STEE). PCE and PEE are unidirectional and sequential, leading to lower efficiency and limited temporal guidance usage. STEE addresses these concerns by using all space-time information efficiently, employing pseudo masks for parallel guidance encoding. The objective loss function combines Binary Cross Entropy, lovasz-hinge loss, and auxiliary loss. The model is trained using AdamW optimizer, with a learning rate of 3e-5, batch size of 4, and a fixed random seed for reproducibility. The paper compares the proposed method with 20 state-of-the-art methods, evaluating performance using MAE, IoU, F-measure score, and BER.
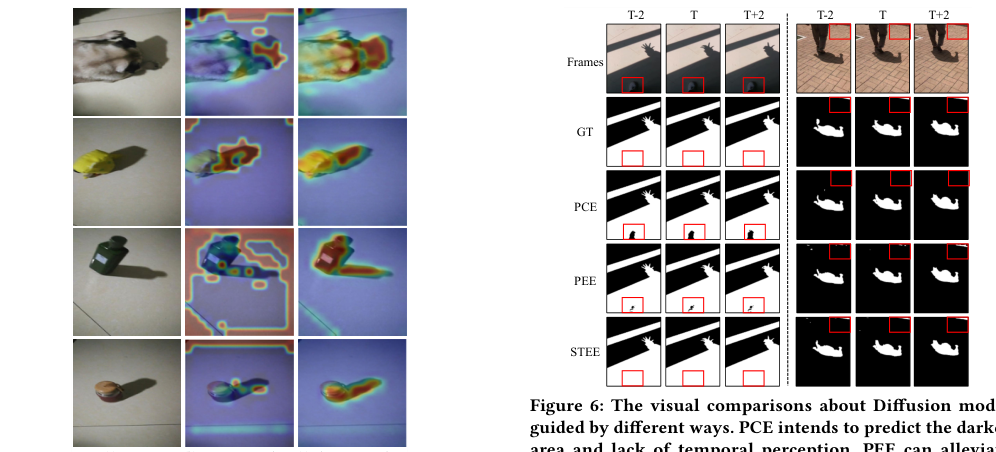
The paper compares various methods for image and video object segmentation and shadow detection, evaluating them based on metrics like Mean Absolute Error (MAE), F-Beta score, Intersection over Union (IoU), and Boundary Error (BER). The study highlights the TBGDiff method, which outperforms state-of-the-art techniques in all metrics. TBGDiff improves MAE, F-Beta score, IoU, BER, S-BER, and N-BER scores compared to other methods. Qualitative comparisons show TBGDiff's superior ability to accurately localize and identify shadow boundaries. The paper also conducts an ablation study, demonstrating the effectiveness of the SBBA and DSA modules in the Diffusion model. TBGDiff is noted for its efficiency, ranking first in terms of FPS and performance metrics despite slightly larger parameters than the smallest model.
In conclusion, the paper presents the Timeline and Boundary Guided Diffusion Network (TBGDiff) for video shadow detection, which outperforms state-of-the-art methods in extensive experiments. The network incorporates temporal information and boundary contexts, utilizing Diffusion models for the first time in this domain. Key components include the Dual Scale Aggregation (DSA) module, Shadow Boundary-Aware Attention (SBAA) module, and Space-Time Encoded Embedding (STEE) for temporal guidance. The paper also provides a comparison with other methods, showcasing the effectiveness and efficiency of the proposed approach.






Introduction
Background
Overview of video shadow detection challenges
Importance of efficient temporal learning and shadow characteristic consideration
Objective
Aim of the research: addressing inefficiencies in temporal learning and lack of shadow characteristic consideration in existing methods
Method
Diffusion Models in Video Shadow Detection
Utilization of Diffusion models for the first time in this context
Processing 2i+1 frames simultaneously for complex real-world scenarios
Dual Scale Aggregation (DSA) Module
Aggregation of temporal features considering both short-term and long-term scales
Mitigation of temporal bias in video shadow detection
Shadow Boundary-Aware Attention (SBAA) Module
Exploration of shadow characteristics using boundary contexts
Enhancement of model's focus on shadow boundaries
Space-Time Encoded Embedding (STEE)
Utilization of timeline temporal information for improved representation
Integration into the Diffusion model for enhanced performance
Bit Analog Strategy
Embedding of noise for denoise process
Direct prediction of shadow masks from aggregated features
Guidance Mechanism
Comparison of three methods: Past Concatenate Embedding (PCE), Past Encoded Embedding (PEE), and Space-Time Encoded Embedding (STEE)
Evaluation of efficiency and temporal guidance usage
Objective Loss Function
Combination of Binary Cross Entropy, lovasz-hinge loss, and auxiliary loss
Optimization of model performance
Training Parameters
AdamW optimizer with learning rate of 3e-5
Batch size of 4 and fixed random seed for reproducibility
Evaluation
Comparison with State-of-the-Art Methods
Metrics: MAE, IoU, F-measure score, and BER
TBGDiff's superior performance across all metrics
Ablation Study
Demonstration of the effectiveness of SBBA and DSA modules
TBGDiff's efficiency and effectiveness in video shadow detection
Conclusion
Summary of the proposed Timeline and Boundary Guided Diffusion Network (TBGDiff)
Outperformance of TBGDiff in extensive experiments compared to state-of-the-art methods
Contribution of key components: DSA, SBAA, and STEE
Potential for future research and applications
Basic info
papers
computer vision and pattern recognition
artificial intelligence
Advanced features