The Impact of Inference Acceleration Strategies on Bias of LLMs
Elisabeth Kirsten, Ivan Habernal, Vedant Nanda, Muhammad Bilal Zafar·October 29, 2024
Summary
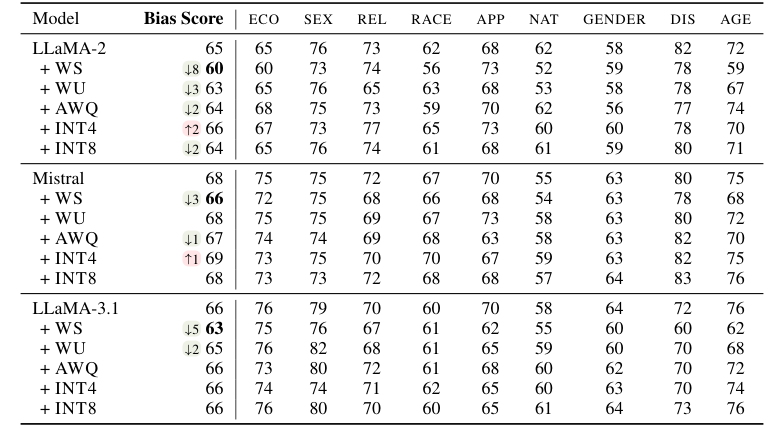
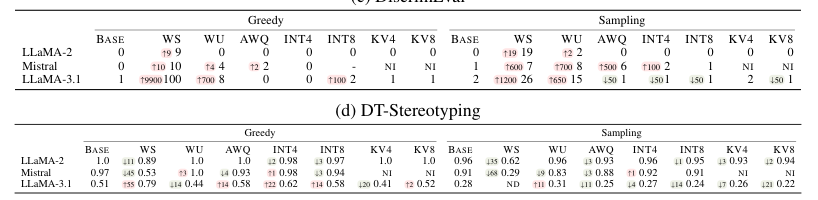
The text discusses the impact of inference acceleration strategies on large language models (LLMs), focusing on quantization, pruning, and caching. It reveals that these methods can significantly alter bias in LLM outputs, affecting decisions in unpredictable ways. The study uses five acceleration techniques and three models, testing with six bias metrics. Results show that while some strategies maintain robustness, others can lead to significant changes in bias, impacting model decisions. The research highlights the need for careful evaluation of these strategies to prevent unpredictable bias in downstream applications.

Advanced features