TableRAG: Million-Token Table Understanding with Language Models
Si-An Chen, Lesly Miculicich, Julian Martin Eisenschlos, Zifeng Wang, Zilong Wang, Yanfei Chen, Yasuhisa Fujii, Hsuan-Tien Lin, Chen-Yu Lee, Tomas Pfister·October 07, 2024
Summary
TableRAG is a retrieval-augmented generation framework for language models to efficiently understand large tables. It uses query expansion, schema, and cell retrieval to pinpoint crucial information, reducing prompt lengths and mitigating information loss. Developed for million-token benchmarks, TableRAG outperforms existing methods, achieving state-of-the-art performance in large-scale table understanding.
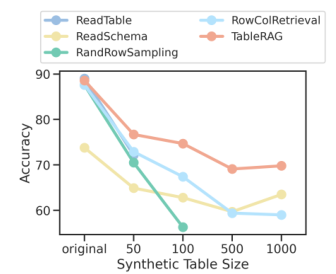
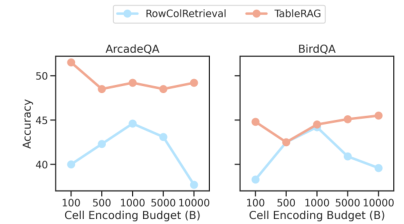
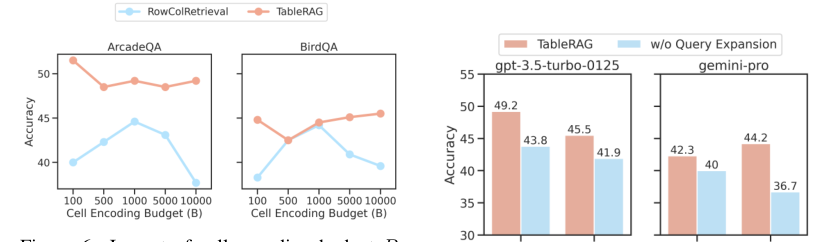
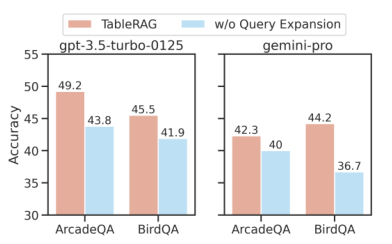



Introduction
Background
Overview of language models and their limitations in understanding large tables
Importance of efficient information retrieval in large-scale datasets
Objective
To present TableRAG, a novel framework that enhances language models' ability to understand and generate responses from large tables
Highlighting the framework's effectiveness in reducing prompt lengths and mitigating information loss
Method
Data Collection
Sources and methods for gathering large table datasets for benchmarking
Importance of diverse and representative datasets for evaluating TableRAG's performance
Data Preprocessing
Techniques for preparing the data to be compatible with TableRAG's framework
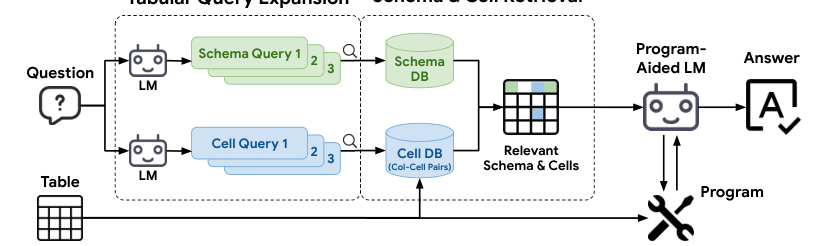
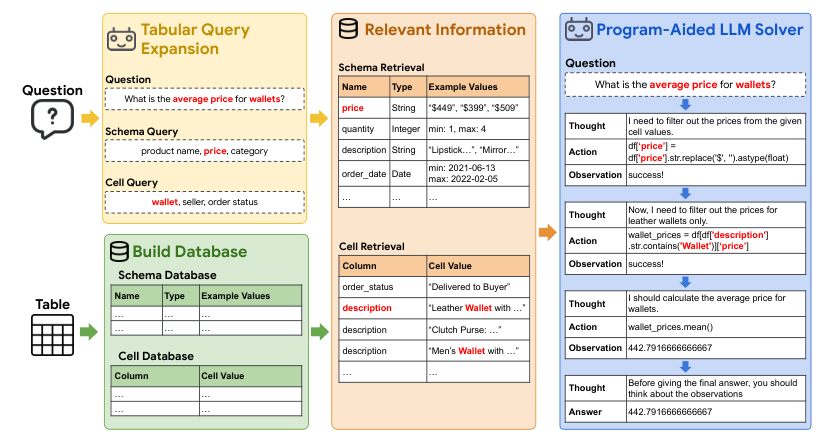
Description of query expansion, schema, and cell retrieval processes
Query Expansion
Explanation of how TableRAG expands queries to cover more relevant information
Benefits of query expansion in improving the precision of information retrieval
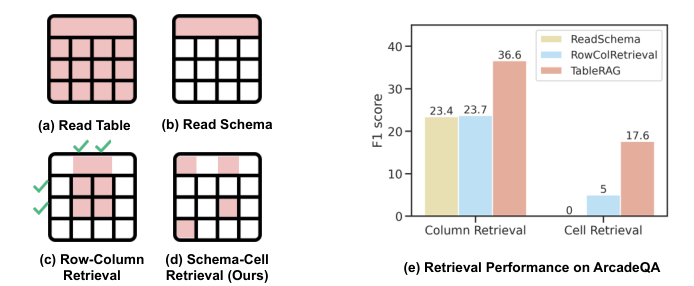
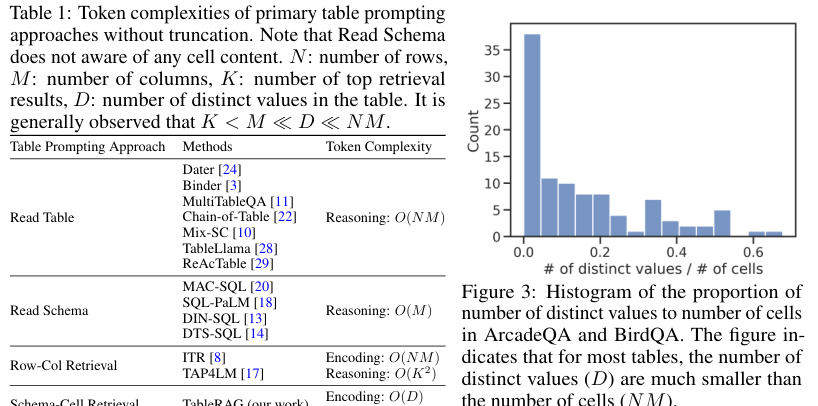
Schema and Cell Retrieval
Detailed process of schema understanding and cell retrieval within large tables
How these components work together to pinpoint crucial information
Model Integration
Description of how TableRAG integrates with existing language models
Optimization strategies for enhancing model performance with TableRAG
Results
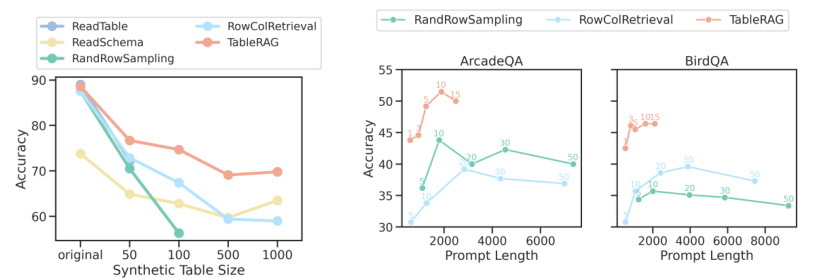
Benchmarking
Overview of the benchmarks used to evaluate TableRAG's performance
Comparison with existing methods in terms of efficiency and accuracy
State-of-the-Art Performance
Detailed results showcasing TableRAG's superior performance in large-scale table understanding
Metrics used to measure performance and improvements over baseline methods
Conclusion
Summary of Contributions
Recap of TableRAG's innovative approach to large table understanding
Discussion on the implications of TableRAG for future research and applications
Future Work
Potential areas for further development and optimization of TableRAG
Exploration of integrating TableRAG with other AI technologies for enhanced performance
Basic info
papers
computation and language
information retrieval
machine learning
artificial intelligence
Advanced features