SpecTool: A Benchmark for Characterizing Errors in Tool-Use LLMs
Shirley Kokane, Ming Zhu, Tulika Awalgaonkar, Jianguo Zhang, Thai Hoang, Akshara Prabhakar, Zuxin Liu, Tian Lan, Liangwei Yang, Juntao Tan, Rithesh Murthy, Weiran Yao, Zhiwei Liu, Juan Carlos Niebles, Huan Wang, Shelby Heinecke, Caiming Xiong, Silivo Savarese·November 20, 2024
Summary
SpecTool is a benchmark for large language models (LLMs) focusing on tool-use tasks. It identifies seven error patterns, evaluates diverse environments and over 30 tasks, offering detailed feedback. This comprehensive framework addresses limitations in existing benchmarks, enabling researchers to understand and mitigate errors in LLM outputs, improving their performance.
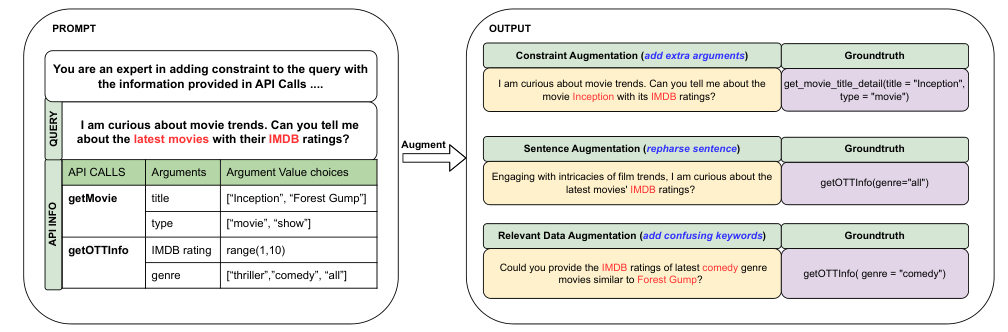
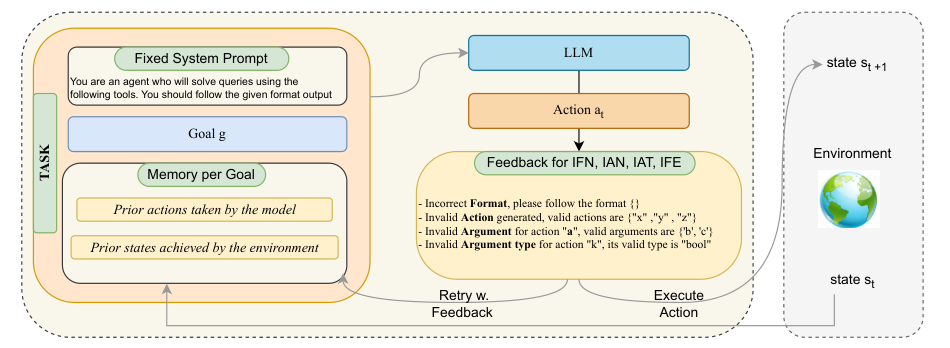
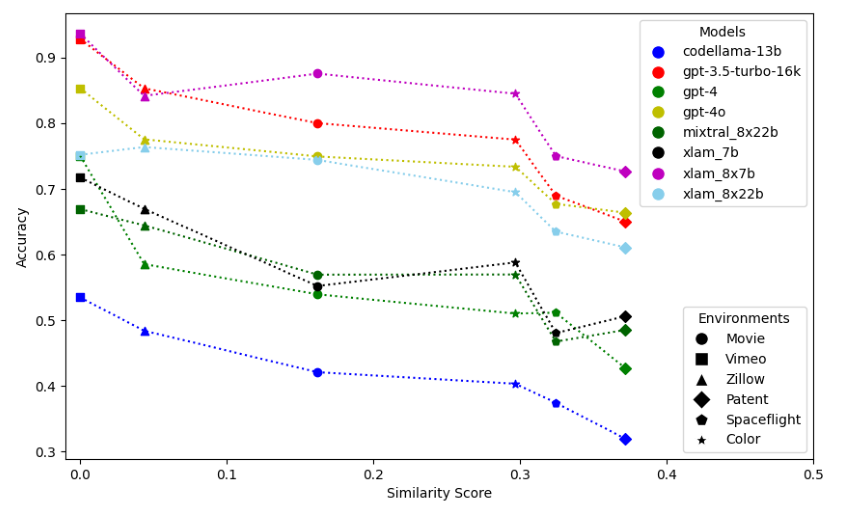


Overview of Large Language Models (LLMs)
Background on LLMs
Definition and characteristics of LLMs
Importance of Benchmarking LLMs
Challenges in evaluating LLMs
The Development and Purpose of SpecTool
Objective of SpecTool
Addressing limitations in existing benchmarks
Key Features of SpecTool
Seven error patterns identified
Evaluation across diverse environments and tasks
Methodology of SpecTool
Data Collection
Types of tasks included in SpecTool
Data Preprocessing
Techniques used for preparing the data
Detailed Feedback Mechanism
How SpecTool provides insights into errors
Evaluation and Analysis
Performance Metrics
Quantitative and qualitative measures
Case Studies
Examples of how SpecTool has been used
Impact on Research and Development
Improving LLM Performance
Strategies for enhancing model outputs
Future Directions
Potential improvements and future applications of SpecTool
Basic info
papers
software engineering
artificial intelligence
Advanced features
Insights
How does SpecTool enhance the evaluation of diverse environments and tasks for large language models?
Which error patterns does SpecTool identify in the outputs of large language models?
What is the primary function of SpecTool in the context of large language models?
What is the significance of SpecTool in addressing limitations found in existing benchmarks for large language models?