Source Separation & Automatic Transcription for Music
Bradford Derby, Lucas Dunker, Samarth Galchar, Shashank Jarmale, Akash Setti·December 09, 2024
Summary
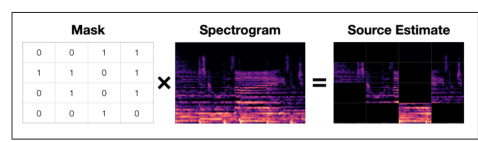
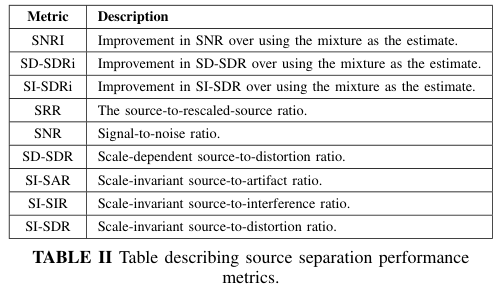
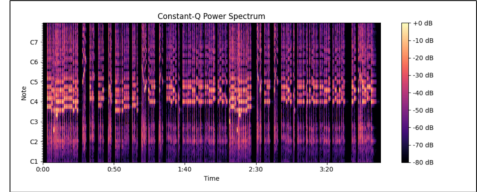
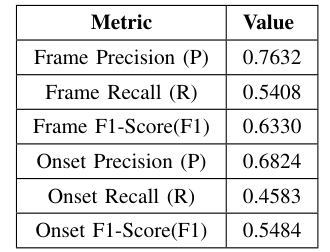
Researchers from Northeastern University's Khoury College of Computer Science developed source separation and automatic transcription techniques for music. They focused on deep learning for source separation, automatic music transcription (AMT), and overcoming challenges like audio noise, training time, and copyright restrictions. Their end-to-end pipeline uses spectrogram masking, deep neural networks, and the MuseScore API to separate music audio into instrument stems, convert them into MIDI files, and transcribe into sheet music. They also created a method for separating audio sources, focusing on isolating vocals from a mix using the short-time Fourier transform and the Nussl library. They used the MAESTRO dataset for transcription work, focusing on 1/4 of the dataset due to resource constraints. Their AMT model uses a deep learning approach to predict a binary piano roll from processed CQT spectrograms, incorporating convolutional, LSTM, and dense layers for feature extraction and temporal dynamics. They successfully created a pipeline for separating vocal data from audio, converting it to MIDI, and displaying as sheet music, though improvements in accuracy and ease-of-use are needed.

Advanced features