RuleArena: A Benchmark for Rule-Guided Reasoning with LLMs in Real-World Scenarios
Ruiwen Zhou, Wenyue Hua, Liangming Pan, Sitao Cheng, Xiaobao Wu, En Yu, William Yang Wang·December 12, 2024
Summary
RULEARENA is a benchmark for evaluating large language models' ability to follow complex, real-world rules in reasoning. It covers domains like airline baggage fees, NBA transactions, and tax regulations, assessing proficiency in handling intricate natural language instructions requiring long-context understanding, logical reasoning, and accurate mathematical computation. Unlike traditional benchmarks, RULEARENA extends beyond standard logic representations and is grounded in authentic scenarios, highlighting LLMs' limitations in identifying and applying rules, performing mathematical computations, and overall performance.
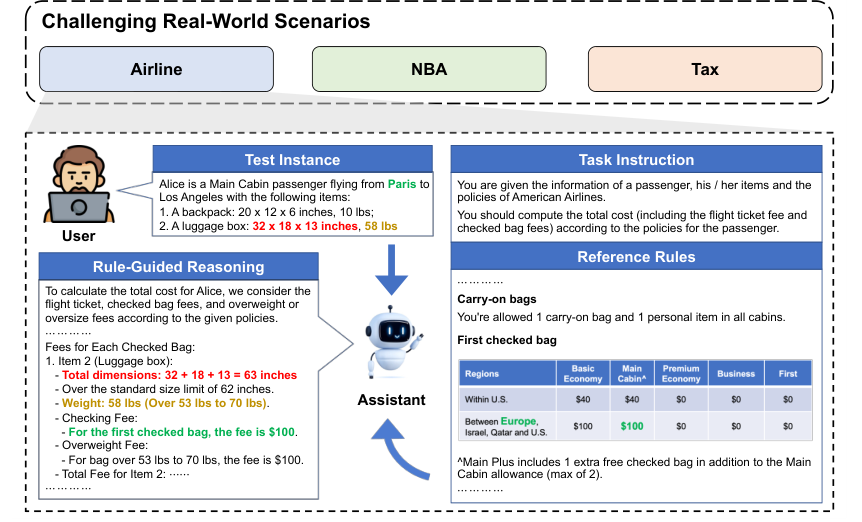
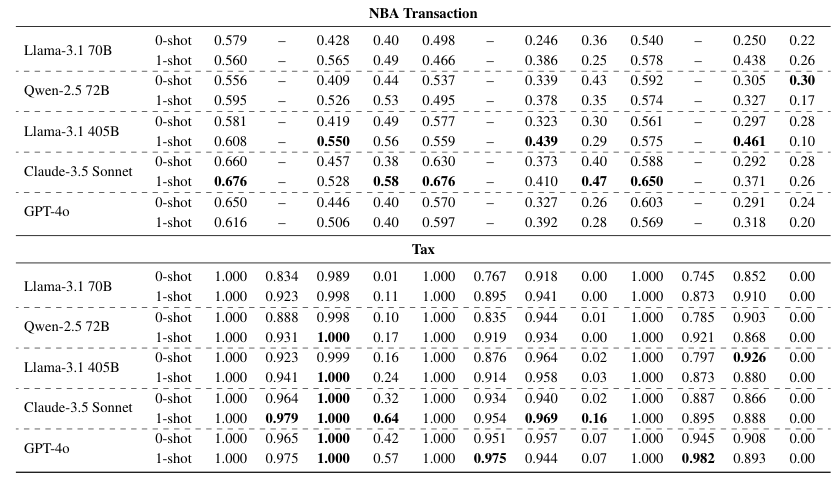
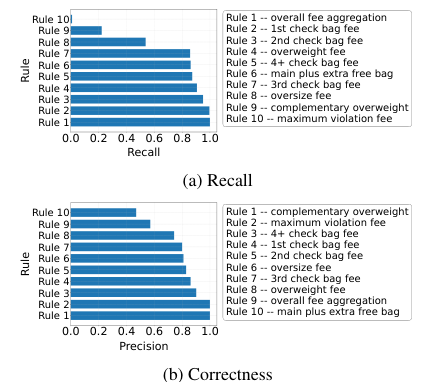
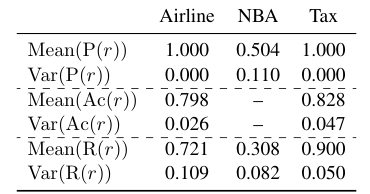
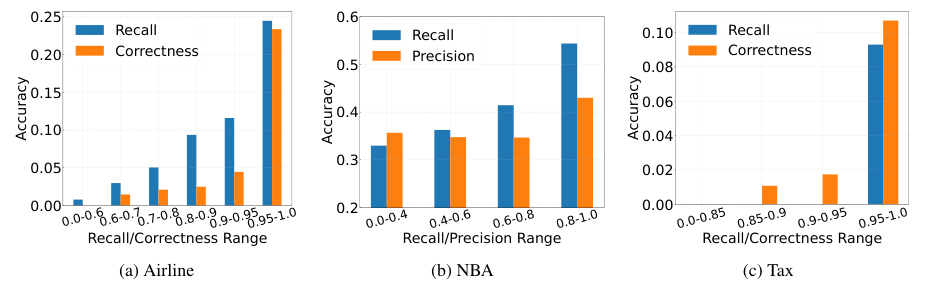
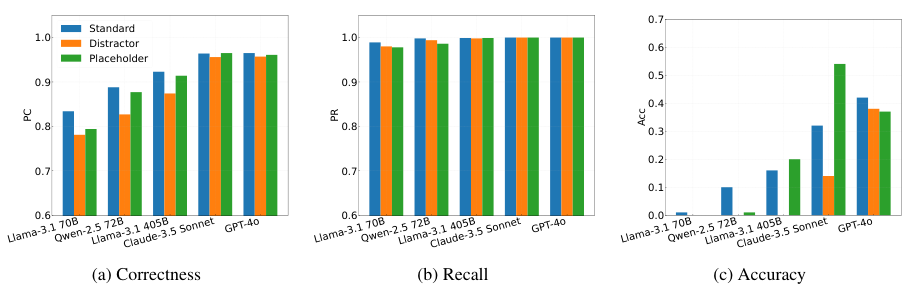




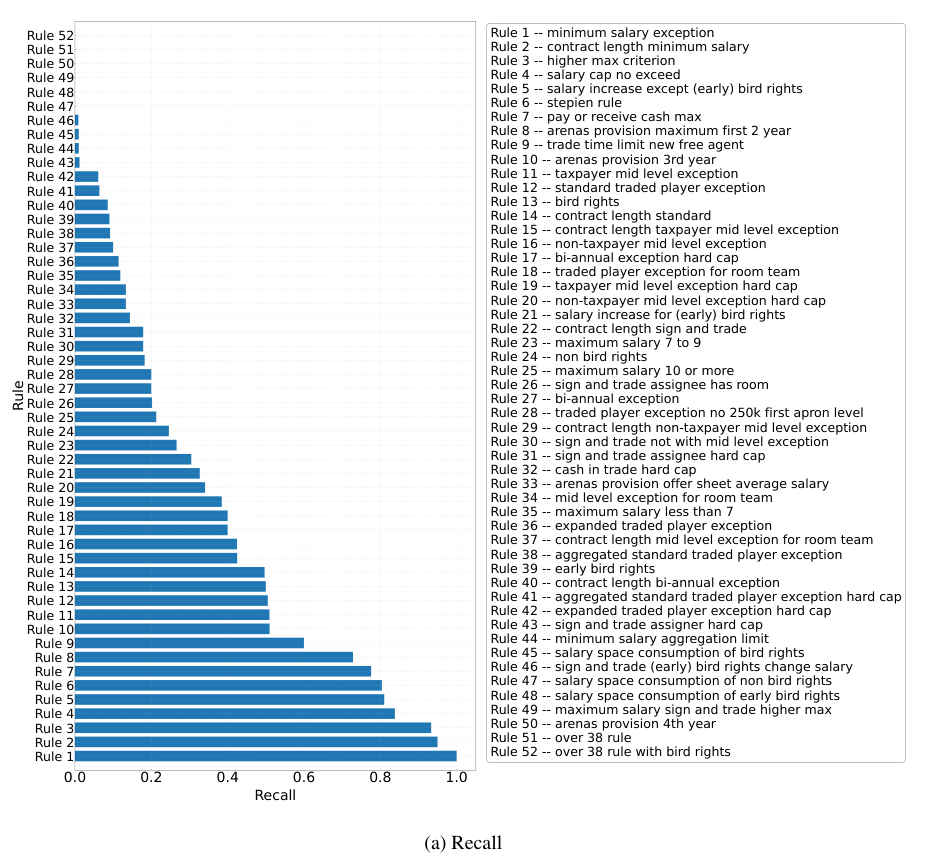
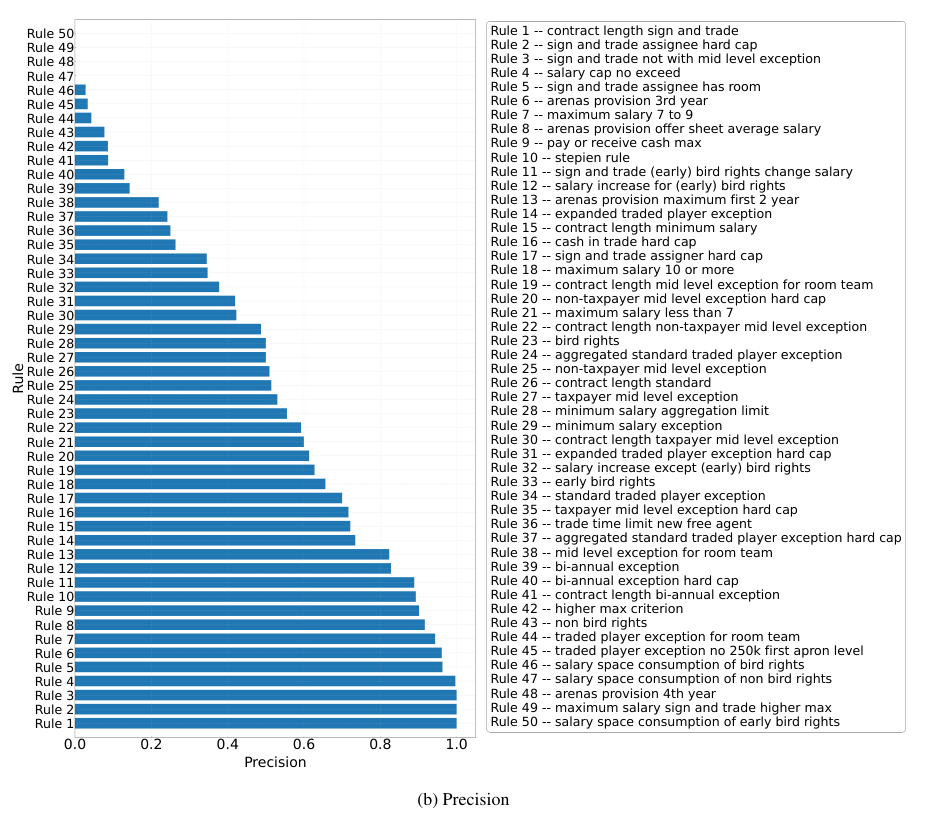
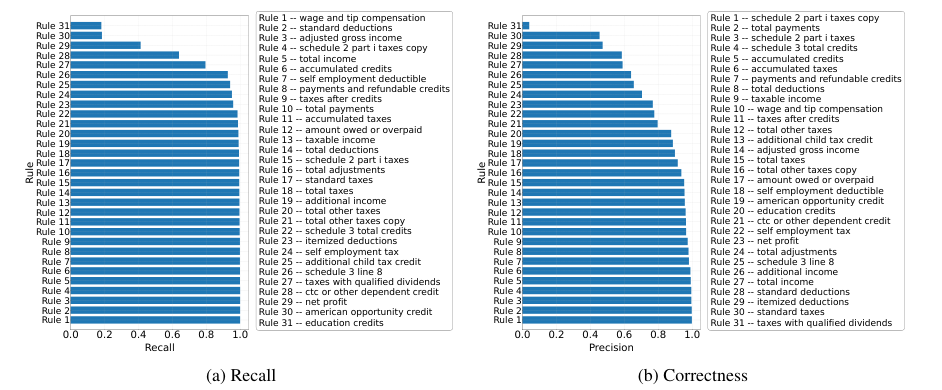


Overview of RULEARENA
Purpose and Significance
Importance of evaluating large language models' rule-following capabilities
Differentiation from traditional benchmarks
Benchmark Domains
Airline baggage fees
NBA transactions
Tax regulations
Methodology of RULEARENA
Data Collection
Source of real-world scenarios
Methods for gathering diverse and authentic examples
Data Preprocessing
Techniques for preparing data for model evaluation
Handling of complex natural language instructions
Evaluation Criteria
Assessment of Long-Context Understanding
Importance of context in rule application
Logical Reasoning
Evaluation of models' ability to reason through complex rules
Mathematical Computation
Assessment of models' proficiency in performing calculations
Performance Metrics
Quantitative measures for evaluating model performance
Challenges and Limitations
Rule Identification
Difficulty in recognizing underlying rules
Rule Application
Challenges in applying identified rules accurately
Mathematical Accuracy
Importance of correct computation in rule-based scenarios
Conclusion
Future Directions
Potential improvements and future research
Implications for AI Development
Importance of RULEARENA in guiding AI advancements
Basic info
papers
computation and language
artificial intelligence
Advanced features
Insights
What specific challenges does RULEARENA highlight regarding large language models' performance in real-world rule application?
How does RULEARENA differ from traditional benchmarks in terms of the scenarios it presents?
Which domains does RULEARENA cover to assess the models' ability to follow complex rules?
What is RULEARENA benchmark designed to evaluate in large language models?