Reward Modeling with Ordinal Feedback: Wisdom of the Crowd
Shang Liu, Yu Pan, Guanting Chen, Xiaocheng Li·November 19, 2024
Summary
The paper introduces a framework for learning reward models (RMs) from ordinal feedback, enhancing human preference alignment in large language models. It addresses limitations in binary preference feedback, proposing a marginal unbiasedness condition inspired by the wisdom of the crowd. This condition enables a probability model for ordinal feedback, reducing Rademacher complexity compared to binary feedback. The framework is applicable to hinge loss and direct policy optimization, offering insights into knowledge distillation. Experiments validate the superiority of fine-grained feedback in RM learning, and incorporating tied preference samples boosts learning performance.
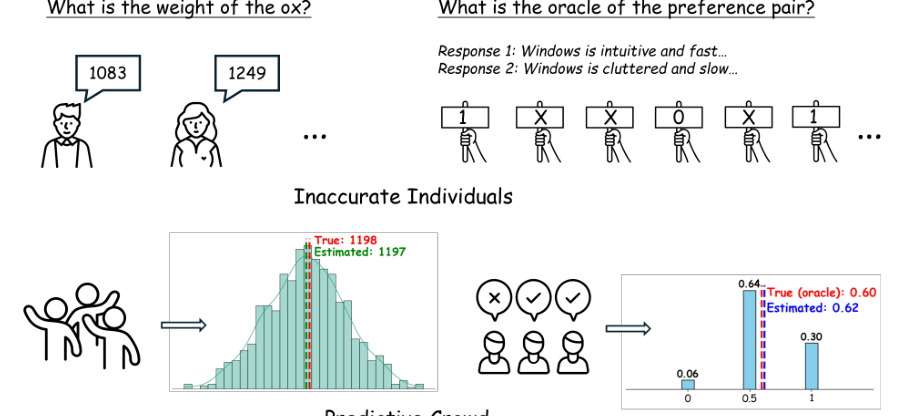
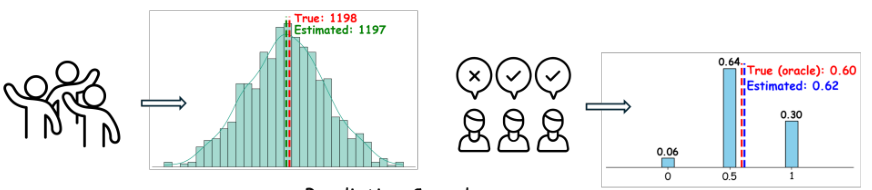

Introduction
Background
Overview of reward models in AI and their importance in aligning with human preferences
Challenges with binary preference feedback in large language models
Objective
To introduce a framework for learning reward models from ordinal feedback, addressing limitations in binary preference feedback
To propose a marginal unbiasedness condition inspired by the wisdom of the crowd for ordinal feedback
To demonstrate the superiority of fine-grained feedback in RM learning and the impact of incorporating tied preference samples
Method
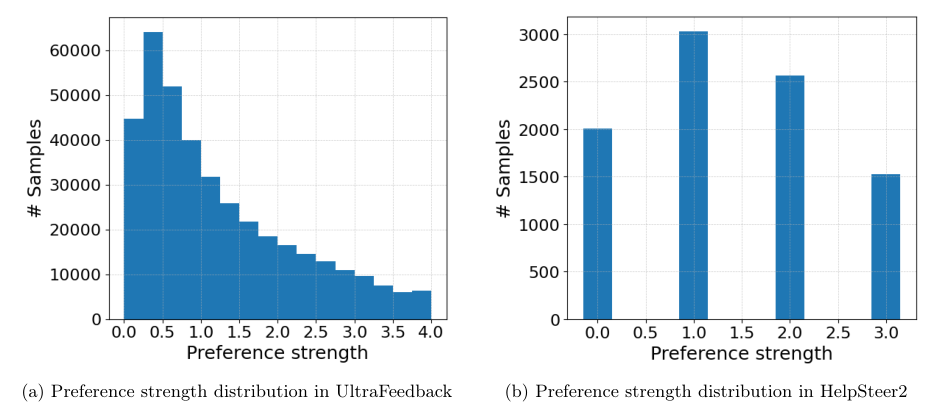
Data Collection
Sources and types of ordinal feedback data
Methods for collecting ordinal preference data from human evaluators
Data Preprocessing
Techniques for handling and preparing ordinal feedback data for model training
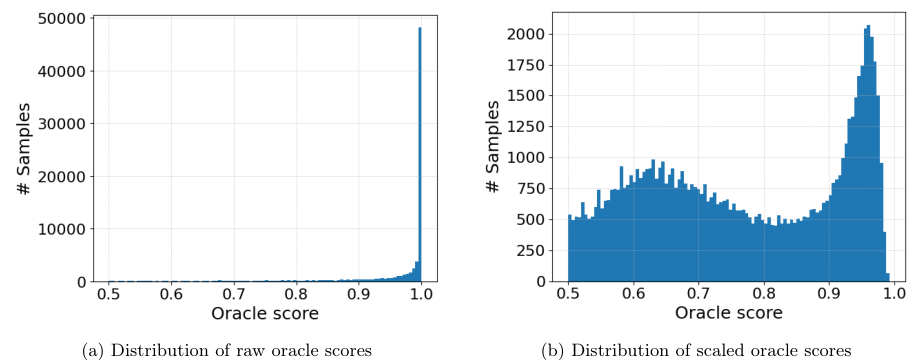
Normalization and scaling of ordinal values for consistent model performance
Framework for Learning Reward Models
Marginal Unbiasedness Condition
Explanation of the condition inspired by the wisdom of the crowd
How it enables a probability model for ordinal feedback
Comparison of Rademacher complexity with binary feedback
Application to Loss Functions
Integration of the framework with hinge loss and direct policy optimization
Insights into knowledge distillation techniques for reward model learning
Experiments and Validation
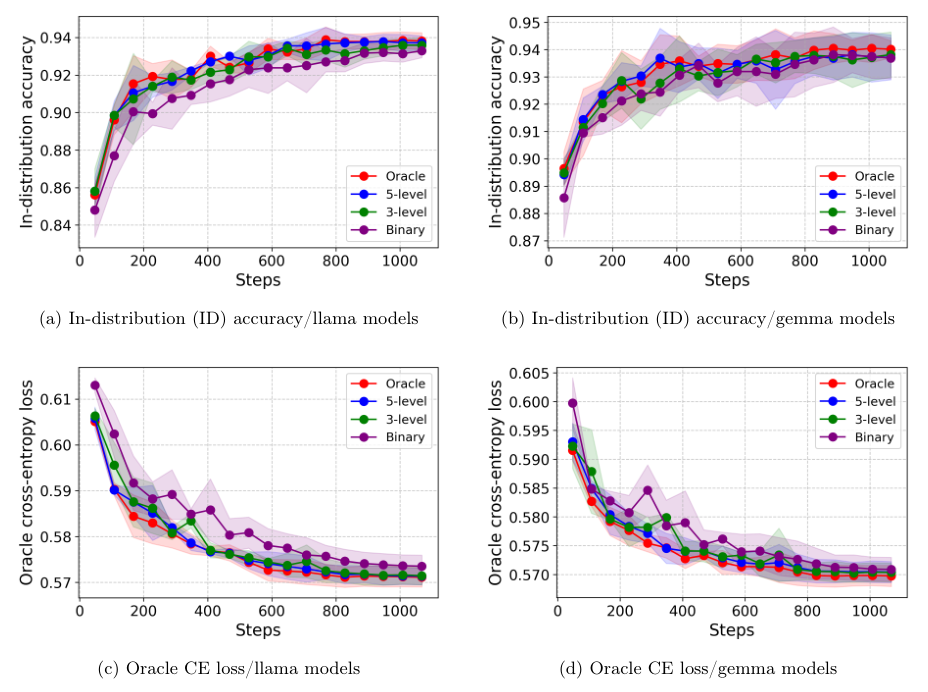
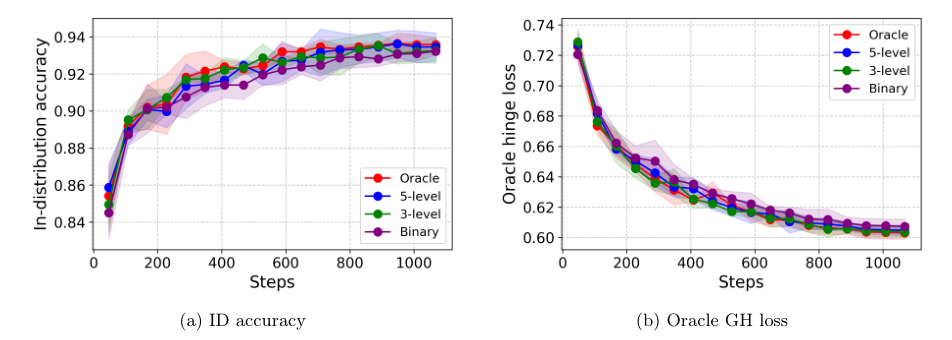
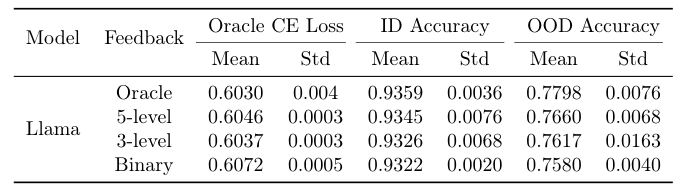
Fine-Grained Feedback Superiority
Experimental setup for comparing binary vs. ordinal feedback in RM learning
Results demonstrating the benefits of using fine-grained ordinal feedback
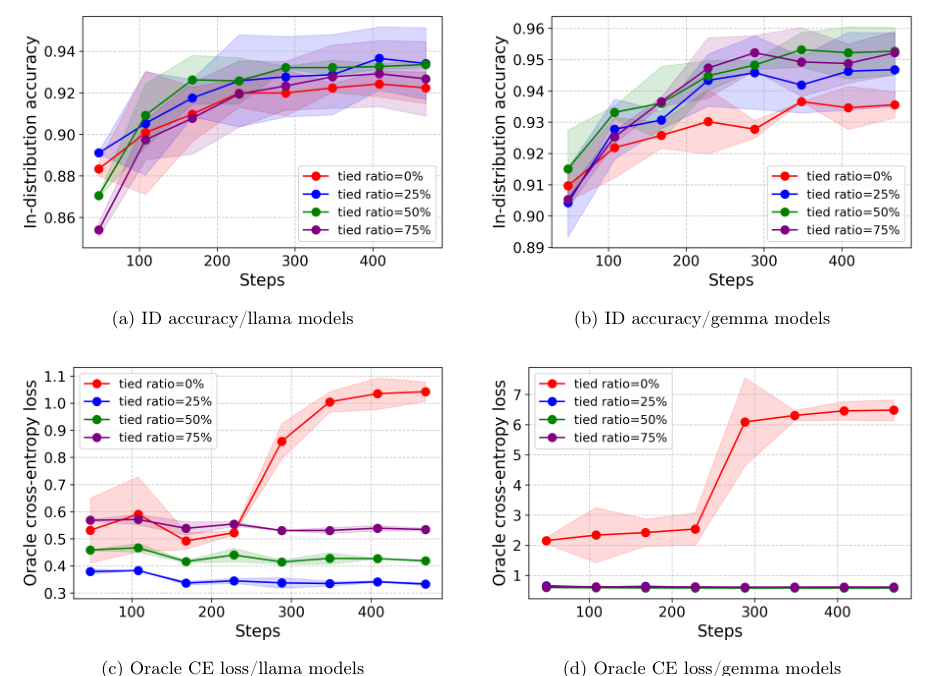
Impact of Tied Preference Samples
Methodology for incorporating tied preference samples in the learning process
Analysis of how tied samples affect learning performance and model alignment with human preferences
Conclusion
Summary of Contributions
Recap of the framework's main contributions to reward model learning from ordinal feedback
Future Work
Potential areas for further research and development in the field
Considerations for scaling and adapting the framework to different applications and domains
Basic info
papers
computation and language
machine learning
artificial intelligence
Advanced features
Insights
What are the key outcomes of the experiments conducted to validate the effectiveness of the proposed framework?
What limitation does the paper identify with binary preference feedback, and how does it address this issue?
How does the paper propose to improve human preference alignment in large language models?