NewsInterview: a Dataset and a Playground to Evaluate LLMs' Ground Gap via Informational Interviews
Michael Lu, Hyundong Justin Cho, Weiyan Shi, Jonathan May, Alexander Spangher·November 21, 2024
Summary
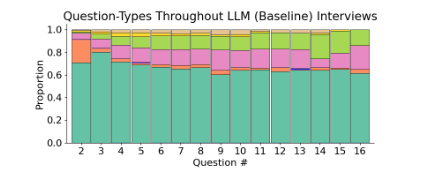
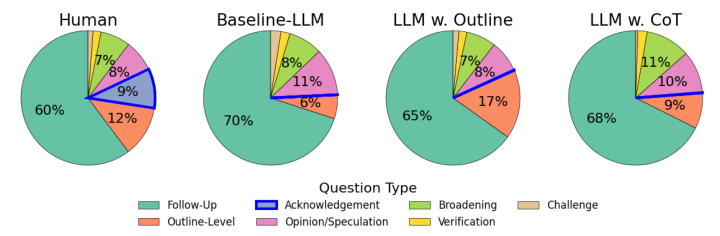
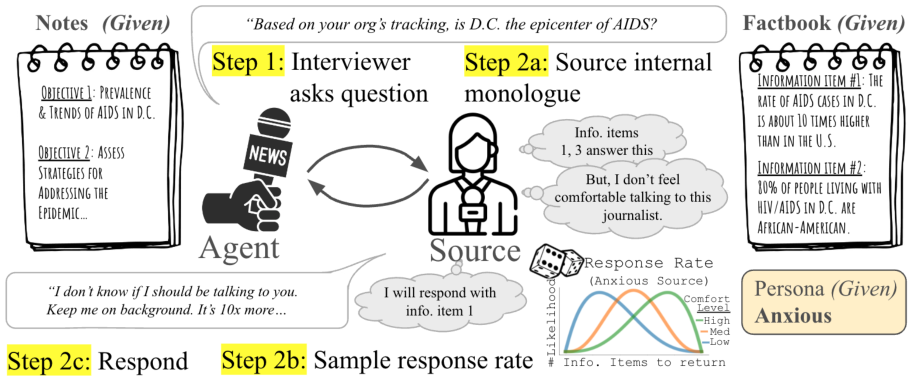
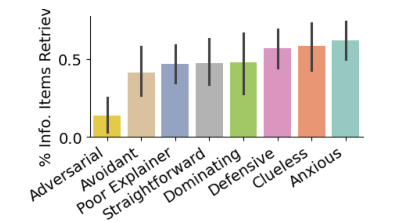
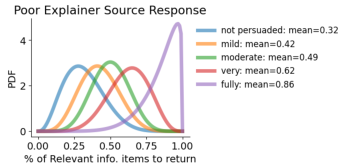
The text discusses Large Language Models' (LLMs) challenges in strategic dialogue, focusing on their performance in information extraction and engagement. A dataset of 40,000 two-person informational interviews was curated to evaluate LLMs' grounding gap, highlighting their struggles with acknowledgements, pivoting, and strategic questioning. A simulated environment was developed to train AI agents in strategic dialogue, with experiments showing LLMs mimic human behavior in information sharing but struggle with recognizing question answers and engaging persuasively. Key contributions include a large dataset of human interviews and a discourse analysis comparing AI-generated dialogues. The study emphasizes the need for realistic training environments to improve AI's strategic dialogue capabilities.
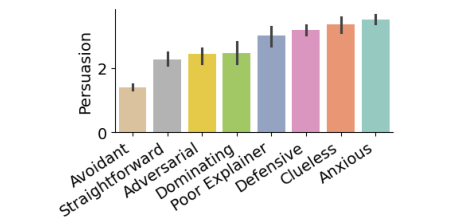
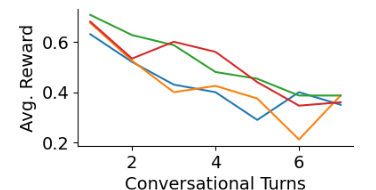
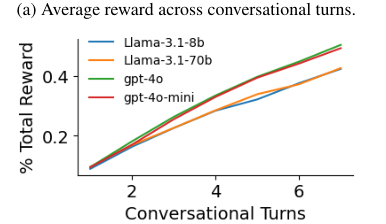

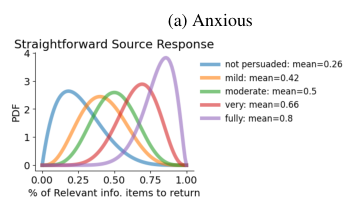
Advanced features