Multi-Modal Forecaster: Jointly Predicting Time Series and Textual Data
Kai Kim, Howard Tsai, Rajat Sen, Abhimanyu Das, Zihao Zhou, Abhishek Tanpure, Mathew Luo, Rose Yu·November 11, 2024
Summary
The TimeText Corpus (TTC) is a multimodal dataset for forecasting, combining time series and text data, addressing the lack of well-curated datasets for this purpose. The Hybrid Multi-Modal Forecaster (Hybrid-MMF) model integrates numerical and textual data, showing competitive performance but marginal improvements over baselines in some cases. The dataset and code are available for further research. The text discusses using Large Language Models (LLMs) for time series forecasting, focusing on methods like LLMTime, Time-LLM, and Zhou et al.'s approach. Techniques include quantization and alignment for inputting numerical data into LLMs. The work introduces a multimodal forecasting model that combines textual and numerical time-series data, differing from Liu et al.'s Time-MMD in its ability to learn textual embeddings and its focus on multi-modal inputs for textual predictions. The dataset includes weather service discussions and recordings, and a medical dataset from MIMIC-III. The text outlines a hybrid model combining time-series and text data, using a multimodal forecasting framework that integrates time series and text data for enhanced forecasting accuracy. Experiments compare this model against text-only and numerical-only forecasting baselines, evaluating performance in both textual and numerical metrics.




Background
The Need for Multimodal Datasets in Forecasting
Addressing the scarcity of well-curated datasets for combining time series and text data
TTC Dataset Overview
Description of the TimeText Corpus (TTC)
Purpose and applications of the dataset
Objective
Research Aim
Objective of the research on TTC and Hybrid-MMF
Contributions
Unique aspects and contributions of the research
Method
Data Collection
Sources and methods for collecting the TTC dataset
Data Preprocessing
Techniques for preparing the dataset for the Hybrid-MMF model
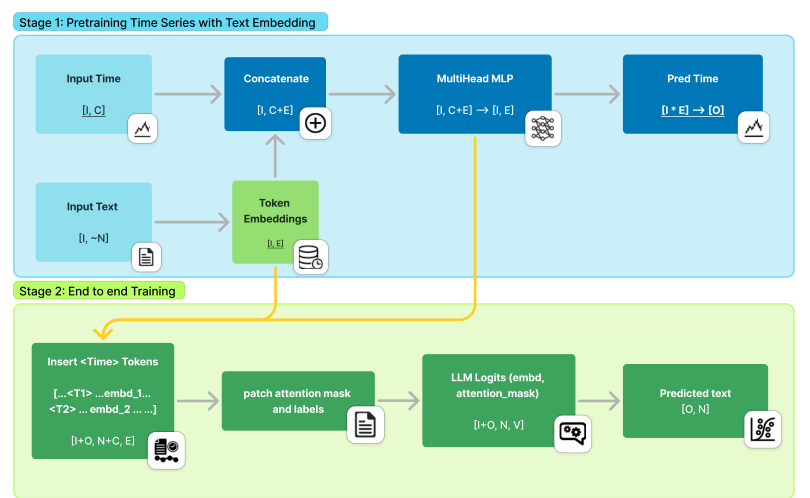
Model Architecture
Detailed description of the Hybrid-MMF model
Integration of numerical and textual data
Large Language Models for Time Series Forecasting
LLMTime, Time-LLM, and Zhou et al.'s Approach
Overview of existing methods using Large Language Models (LLMs) for time series forecasting
Quantization and Alignment Techniques
Methods for inputting numerical data into LLMs
Multimodal Forecasting Model
Model Description
Introduction to the proposed multimodal forecasting model
Distinguishing Features
Comparison with Liu et al.'s Time-MMD model
Dataset Utilization
Description of the included weather service discussions and medical dataset from MIMIC-III
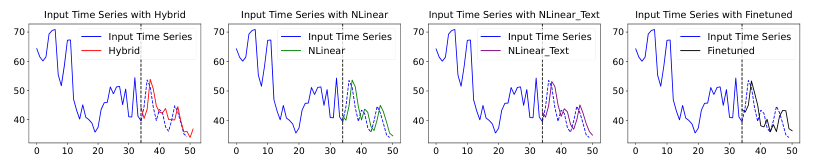
Experiments and Evaluation
Baseline Comparison
Evaluation against text-only and numerical-only forecasting baselines
Performance Metrics
Metrics used for assessing the model's performance in both textual and numerical contexts
Conclusion
Summary of Findings
Future Directions
Potential areas for further research and development
Basic info
papers
artificial intelligence
Advanced features