LuxEmbedder: A Cross-Lingual Approach to Enhanced Luxembourgish Sentence Embeddings
Fred Philippy, Siwen Guo, Jacques Klein, Tegawendé F. Bissyandé·December 04, 2024
Summary
The text discusses the creation of LUXEMBEDDER, a cross-lingual sentence embedding model for Luxembourgish, addressing the scarcity of parallel data for low-resource languages. It uses a high-quality human-generated dataset to enhance performance in tasks like Topic Modeling and Document Clustering. The model demonstrates that including low-resource languages in parallel training can benefit other low-resource languages more than relying solely on high-resource language pairs. Additionally, a Luxembourgish paraphrase detection benchmark was created to promote further research in low-resource language processing.
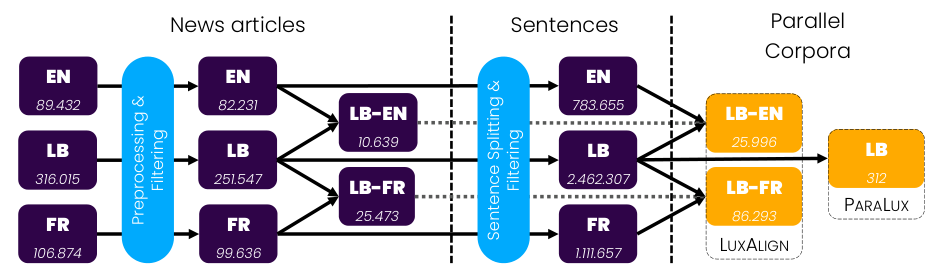
Introduction
Background
Overview of Luxembourgish language and its challenges in NLP
Importance of cross-lingual sentence embedding models
Objective
Aim of the research: developing a model for Luxembourgish and its implications
Method
Data Collection
Source of the human-generated dataset
Characteristics of the dataset
Data Preprocessing
Techniques used for data cleaning and preparation
Model Development
Architecture of LUXEMBEDDER
Training process and parameters
Evaluation
Metrics used for assessing model performance
Comparison with existing models
Results
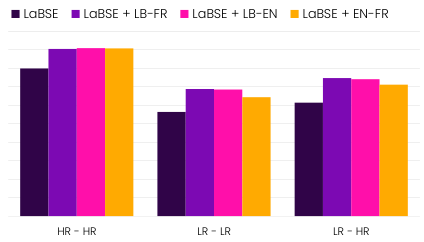
Performance in Topic Modeling and Document Clustering
Detailed results and analysis
Impact of Including Low-Resource Languages
Comparative analysis with models using high-resource language pairs
Conclusion
Summary of Findings
Future Directions
Potential improvements for LUXEMBEDDER
Recommendations for further research
Basic info
papers
computation and language
artificial intelligence
Advanced features
Insights
How does the inclusion of low-resource languages in parallel training affect other low-resource languages, as mentioned in the text?
What was the purpose of creating the Luxembourgish paraphrase detection benchmark, as described in the text?
What is LUXEMBEDDER and what language does it target?
What tasks does LUXEMBEDDER perform well in, according to the text?