Lifelong Personalized Low-Rank Adaptation of Large Language Models for Recommendation
Jiachen Zhu, Jianghao Lin, Xinyi Dai, Bo Chen, Rong Shan, Jieming Zhu, Ruiming Tang, Yong Yu, Weinan Zhang·August 07, 2024
Summary
The paper "Lifelong Personalized Low-Rank Adaptation of Large Language Models for Recommendation" introduces RecLoRA, a model that enhances recommendation systems by incorporating personalized information from large language models (LLMs). The main limitations of current approaches, such as suboptimal performance due to shared LoRA parameters, inefficiency in handling long text sequences, and scalability issues with large datasets, are addressed by RecLoRA. The model uses a Personalized LoRA module for individual users and a Long-Short Modality Retriever for different history lengths. Additionally, it employs a Few2Many Learning Strategy to magnify small training spaces to full spaces. The model outperforms existing baselines in extensive experiments on public datasets.
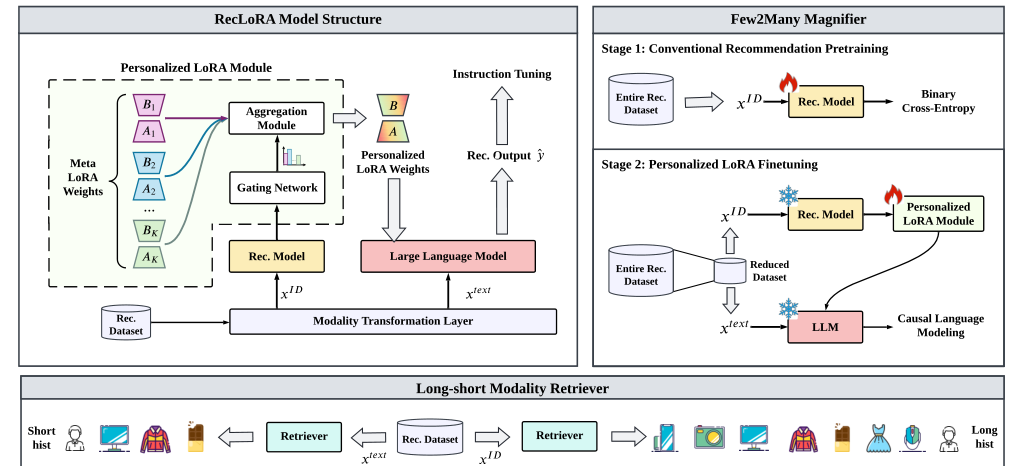
RecLoRA is a novel framework for LLMs in recommendation tasks that introduces a set of parallel, independent LoRA weights, a sequential CRM, and a soft routing method to aggregate meta-LoRA weights. This approach allows for parameter personalization, improves effectiveness with minimal time cost, and pre-trains the CRM on the full training space. The framework achieves a better trade-off between effectiveness and efficiency, requiring only a few-shot training data and extending sequence length without increasing time cost. Offline experiments on three datasets show promising results, validating the proposed model's effectiveness.
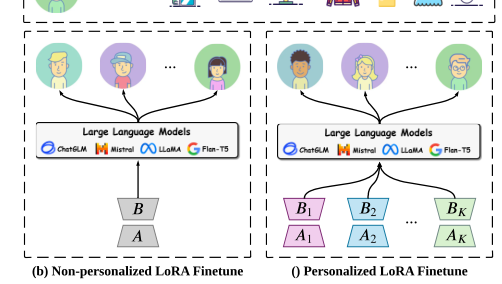
The paper discusses the development of a personalized recommendation system using large language models (LLMs) for item preference estimation. It introduces two main paradigms for input data: ID modality, which involves one-hot encoding for conventional recommendation models, and textual modality, which uses hard prompt templates for LLMs. The paper then discusses conventional recommendation models, which capture collaborative patterns for precise user preference estimation. It also covers large language models as recommenders, detailing how they are adapted for recommendation tasks through low-rank adaptation (LoRA), a parameter-efficient fine-tuning method. The paper explains that LoRA maintains two trainable lightweight matrices attached to a frozen pretrained weight matrix to reduce resource consumption during fine-tuning.
The proposed RecLoRA framework addresses three limitations: constructing personalized low-rank adaptation for LLMs, alleviating effectiveness and efficiency issues with behavior sequence extension, and expanding the receptive field of LLMs to the entire training space. The framework's network architecture and training process are described, with the overall goal of improving recommendation accuracy and efficiency.
In summary, the paper presents RecLoRA, a lifelong personalized low-rank adaptation model for large language models in recommendation systems. It introduces a Personalized LoRA module, a Long-Short Modality Retriever, and a Few2Many Magnifier Strategy to enhance performance and efficiency. The model outperforms existing baselines in experiments on public datasets, demonstrating its effectiveness in recommendation tasks.





Introduction
Background
Overview of recommendation systems and their importance
Challenges faced by current recommendation systems, including performance limitations, handling of long text sequences, and scalability issues
Introduction to large language models (LLMs) and their potential in recommendation tasks
Objective
Objective of the research: to develop a model that enhances recommendation systems by incorporating personalized information from LLMs
Focus on addressing the limitations of existing approaches
Method
Personalized LoRA Module
Description of the Personalized LoRA module for individual users
How it personalizes the model for each user
Long-Short Modality Retriever
Explanation of the Long-Short Modality Retriever for different history lengths
How it adapts to varying sequence lengths in recommendation tasks
Few2Many Learning Strategy
Description of the Few2Many Learning Strategy to magnify small training spaces to full spaces
Benefits of this strategy in terms of efficiency and effectiveness
RecLoRA Framework
Overview of the RecLoRA framework, including its components and how they work together
Detailed explanation of the Personalized LoRA module, Long-Short Modality Retriever, and Few2Many Learning Strategy
Implementation
Data Preprocessing
Methods used for data collection and preprocessing to prepare the data for the RecLoRA model
Training Process
Description of the training process for the RecLoRA model, including the use of a few-shot training data and extension of sequence length without increasing time cost
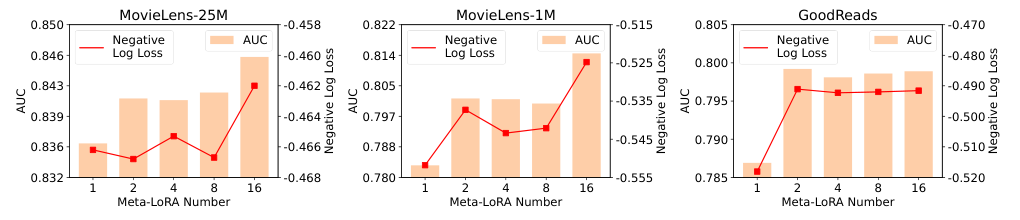
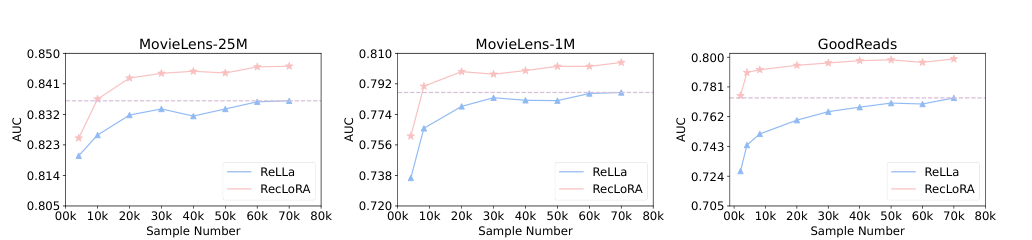
Offline Experiments
Overview of the experimental setup, including the three datasets used for validation
Results and analysis of the offline experiments, demonstrating the effectiveness of the proposed model
Conventional Recommendation Models
ID Modality
Explanation of the ID modality for conventional recommendation models, involving one-hot encoding for user and item representations
Textual Modality
Description of the textual modality using hard prompt templates for LLMs in recommendation tasks
Large Language Models as Recommenders
Low-Rank Adaptation (LoRA)
Detailed explanation of the LoRA method for parameter-efficient fine-tuning of LLMs for recommendation tasks
How LoRA maintains two trainable lightweight matrices to reduce resource consumption
Proposed Model: RecLoRA
Addressing Limitations
Discussion on how RecLoRA addresses the three main limitations of current recommendation systems
Explanation of the network architecture and training process of the RecLoRA framework
Conclusion
Summary of the contributions of the paper
Future directions and potential applications of the RecLoRA model
Basic info
papers
information retrieval
artificial intelligence
Advanced features