Liberal Entity Matching as a Compound AI Toolchain
Silvery D. Fu, David Wang, Wen Zhang, Kathleen Ge·June 17, 2024
Summary
This paper investigates the limitations of traditional entity matching (EM) methods, which are rule-based and static. To address these issues, the authors introduce Libem, a compound AI toolchain designed for EM. Libem is modular, allowing for data preprocessing, external information retrieval, and self-refinement through learning and optimization. It adapts to different datasets and performance goals, improving accuracy and ease of use. Initial experiments demonstrate Libem's superiority over solo-AI systems, with an average F1 score increase of 3% across four out of five datasets. The project is ongoing, focusing on enhancing tools, speed, self-refinement, and expanding its application to broader data management tasks. Libem is open-source and aims to enhance practical compound AI solutions for entity matching.
Introduction
Background
Traditional EM limitations: rule-based and static approaches
Need for adaptability and performance improvement
Objective
Introduce Libem: a modular AI toolchain for entity matching
Aim to address existing challenges and enhance accuracy
Focus on ease of use and adaptability
Method
Data Collection
Modular approach: supporting various data sources
External information retrieval techniques
Data Preprocessing
Advanced techniques for cleaning and standardizing data
Handling noise and inconsistencies
Compound AI Architecture
1. Data Preprocessing Module
Data normalization
Feature extraction
Entity resolution techniques
2. External Information Retrieval
Integration of external data sources
Real-time data enrichment
3. Learning and Optimization
Self-refinement through AI algorithms
Iterative improvement based on performance feedback
Experiments and Evaluation
Initial Results
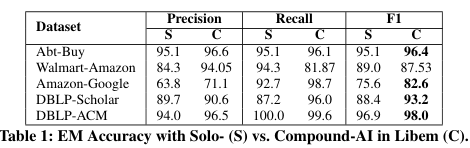
Comparison with solo-AI systems: average F1 score improvement
Performance across four out of five datasets
Ongoing Research
Enhancing tools for speed and efficiency
Expanding to broader data management tasks
Open-Source and Practical Applications
Libem's accessibility and community-driven development
Real-world use cases and practical implications
Conclusion
Libem's contribution to the field of entity matching
Potential for compound AI to revolutionize EM
Future directions and roadmap for the project
Basic info
papers
databases
software engineering
artificial intelligence
Advanced features
Insights
How does Libem address the limitations of rule-based and static EM methods?
What is the primary contribution of the authors' introduced toolchain, Libem?
What are the key features of Libem that make it superior to solo-AI systems?
What does the paper discuss about traditional entity matching methods?