Learning Loss Landscapes in Preference Optimization
Carlo Alfano, Silvia Sapora, Jakob Nicolaus Foerster, Patrick Rebeschini, Yee Whye Teh·November 10, 2024
Summary
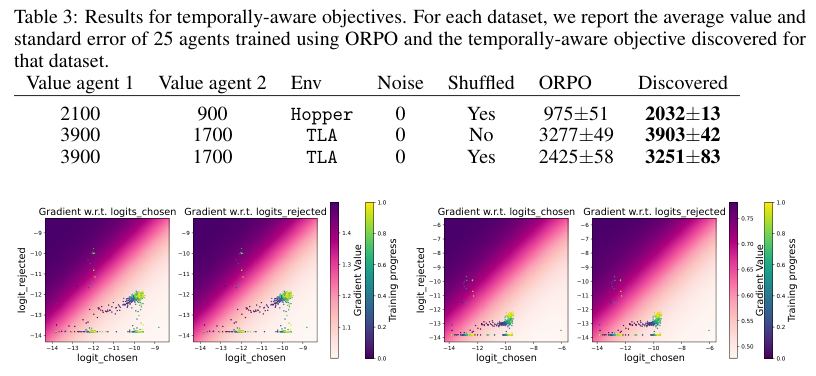
The study explores preference optimization algorithms' performance influenced by dataset properties, introducing a novel mirror descent-based framework that uses evolutionary strategies to discover loss functions for handling problematic scenarios. This approach leads to significant performance improvements over existing methods. The framework demonstrates generalization by applying the discovered loss functions to fine-tune large language models with mixed-quality data, outperforming traditional methods. The text also discusses the evaluation of offline preference optimization algorithms, focusing on ORPO, which outperforms DPO in MuJoCo environments with well-defined reward structures. Key findings include distinct failure modes of ORPO on low-quality datasets, relevant to practical applications. The study provides a proof for Theorem 3.1 in Appendix A, involving plugging equation (8) into a maximum likelihood problem (3) to derive the objective: π⋆ is the argmax of ED log σ. The text discusses the transferability of objectives learned using a specific methodology, showing that a static objective, discovered on the shuffled TLA dataset, successfully transfers to the shuffled Hopper dataset, achieving a final policy value of 1735±39. Additionally, when applied to the LLM-tuning task with shuffled data, the methodology outperforms the baseline, achieving 57% accuracy compared to 62% with the discovered objective. The trained model with the discovered objective also outperforms AlpacaE-val, achieving a 53% winrate, indicating its effectiveness across different domains.
Background
Dataset Properties and Optimization Algorithms
Overview of preference optimization algorithms
Importance of dataset properties in algorithm performance
Objective
Aim of the study: exploring the impact of dataset properties on preference optimization algorithms
Introduction of a novel mirror descent-based framework using evolutionary strategies
Method
Data Collection
Methods for collecting datasets for preference optimization
Data Preprocessing
Techniques for preparing datasets for algorithm application
Framework Implementation
Description of the mirror descent-based framework
Use of evolutionary strategies to discover loss functions
Evaluation
Criteria for assessing algorithm performance
Application of the framework to fine-tune large language models
Results
Generalization Across Datasets
Performance of the framework on mixed-quality data
Comparison with traditional methods
Offline Algorithm Evaluation
Focus on ORPO vs. DPO in MuJoCo environments
Analysis of distinct failure modes of ORPO on low-quality datasets
Theoretical Foundations
Theorem 3.1 Proof
Explanation of the proof involving equation (8) and maximum likelihood problem (3)
Derivation of the objective function π⋆
Transferability of Objectives
Static Objective Transfer
Case study of transferring a static objective from the shuffled TLA dataset to the shuffled Hopper dataset
Results and implications for policy value improvement
LLM-tuning Task
Application of the discovered objective to LLM-tuning with shuffled data
Comparison with baseline methods and AlpacaE-val
Conclusion
Summary of Findings
Key insights into preference optimization algorithms and dataset properties
Discussion of the framework's generalization capabilities and transferability
Implications for Practical Applications
Relevance of the study to real-world scenarios
Future directions for research
Basic info
papers
machine learning
artificial intelligence
Advanced features
Insights
How does the methodology demonstrate transferability across different domains, specifically in the context of LLM-tuning tasks?
What are the key findings regarding the failure modes of the ORPO algorithm on low-quality datasets?
How does the novel mirror descent-based framework improve upon existing methods in handling problematic scenarios?