Large-Scale 3D Medical Image Pre-training with Geometric Context Priors
Linshan Wu, Jiaxin Zhuang, Hao Chen·October 13, 2024
Summary
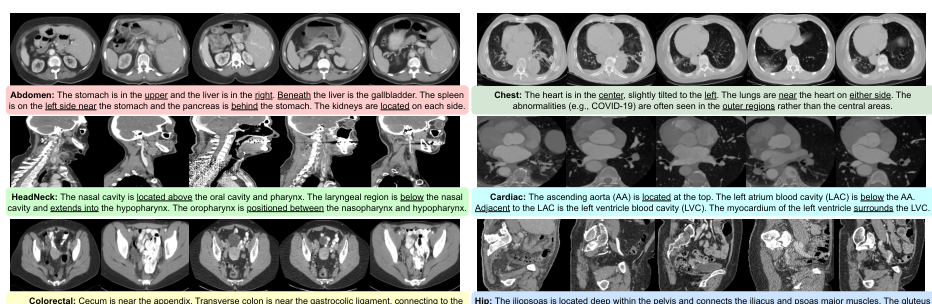
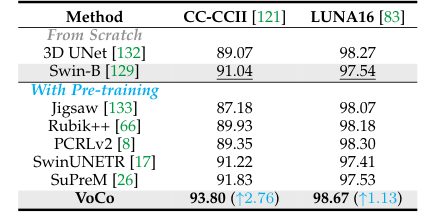
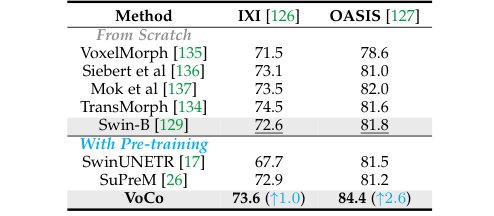
VoCo, a large-scale 3D medical image pre-training framework, addresses annotation scarcity by leveraging geometric context priors. It creates positive and negative pairs for contrastive learning, enabling high-level semantic learning without annotations. VoCo's effectiveness is demonstrated through the creation of PreCT-160K, the largest medical image pre-training dataset, and a benchmark for 48 medical tasks. VoCo shows superior performance, especially on datasets with limited labeled cases, and accelerates fine-tuning convergence.


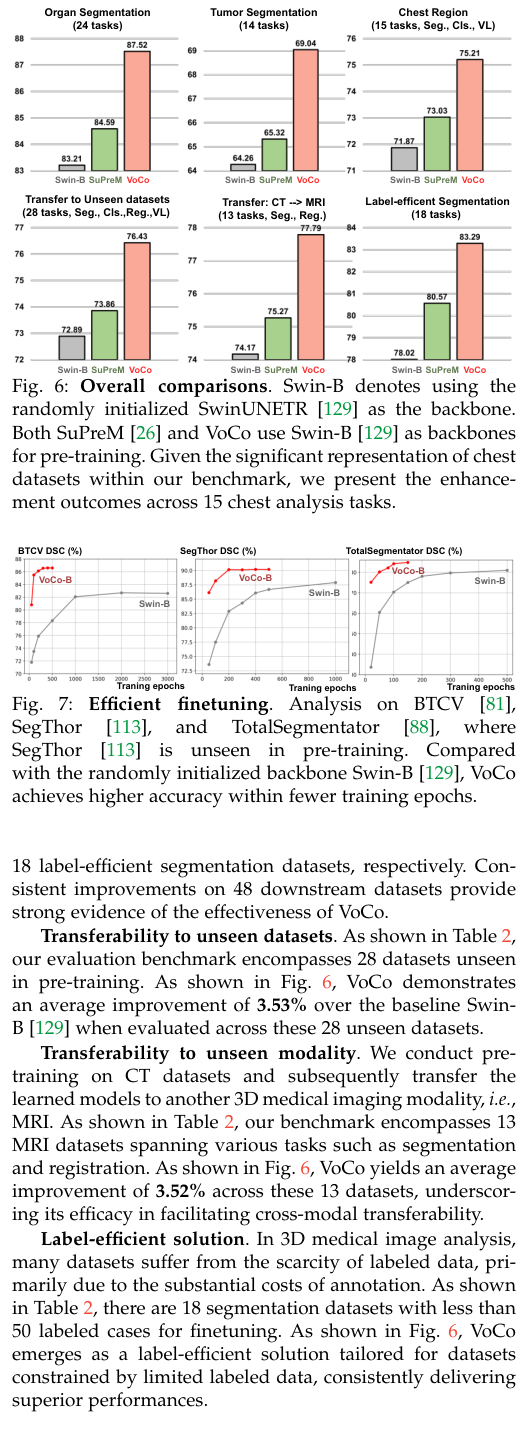
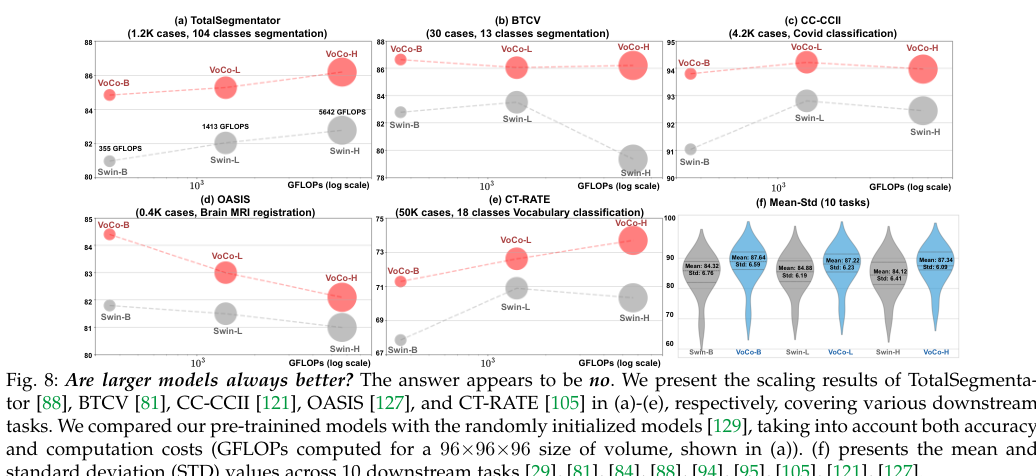
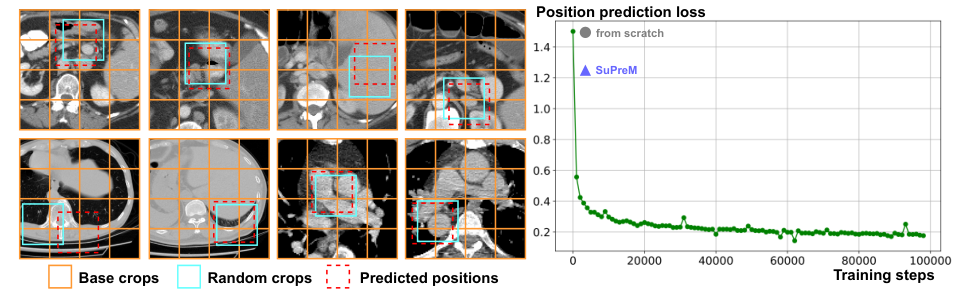

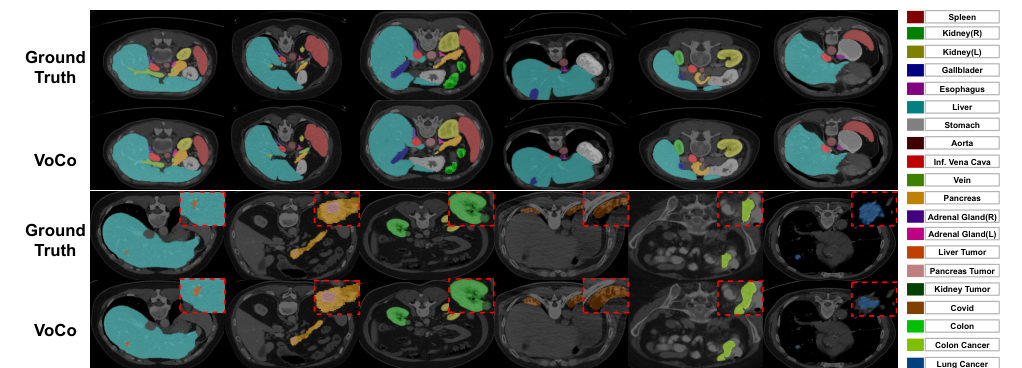
Advanced features