HiQuE: Hierarchical Question Embedding Network for Multimodal Depression Detection
Juho Jung, Chaewon Kang, Jeewoo Yoon, Seungbae Kim, Jinyoung Han·August 07, 2024
Summary
The HiQuE (Hierarchical Question Embedding) network is a novel depression detection framework that leverages the hierarchical structure of clinical interview questions. It captures the importance of each question in diagnosing depression by learning mutual information across multiple modalities. HiQuE outperforms other state-of-the-art multimodal depression detection models and emotion recognition models on the DAIC-WOZ dataset. This framework is designed to enhance early intervention for individuals experiencing depression by utilizing automated detection methods. The research team includes Juho Jung, Chaewon Kang, Jeewoo Yoon, Seungbae Kim, and Jinyoung Han, with Jinyoung Han as the corresponding author. The paper was presented at the 33rd ACM International Conference on Information and Knowledge Management (CIKM) in 2024.
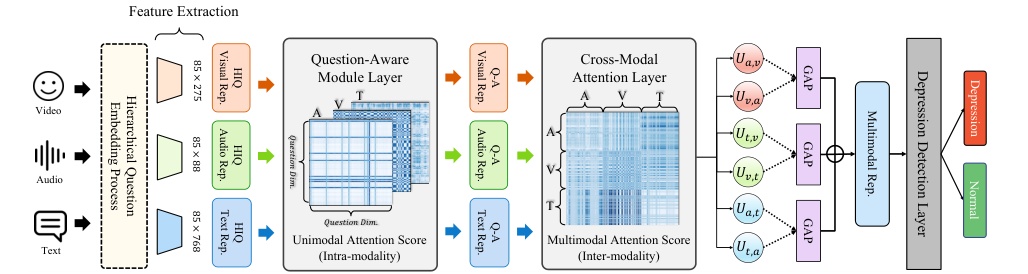
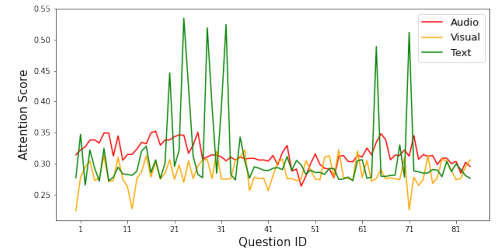
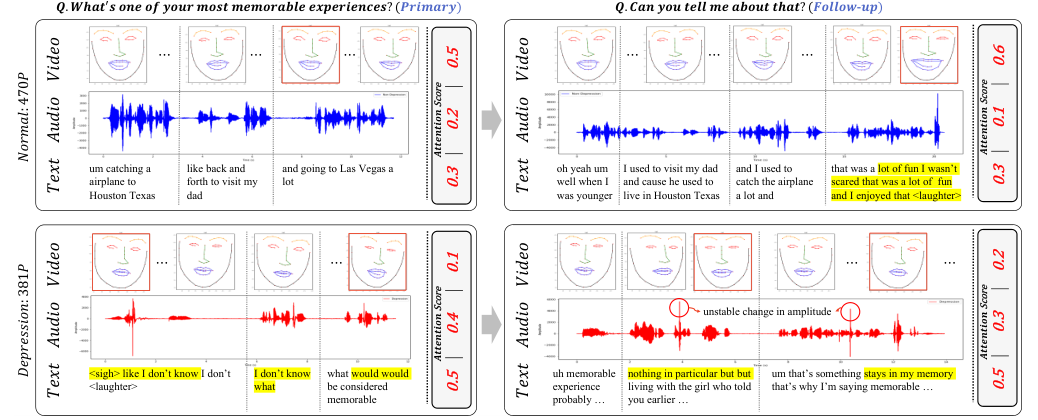
The HiQuE framework introduces an interpretable multimodal depression detection system that leverages the hierarchical relationship between primary and follow-up questions in clinical interviews. It addresses the lack of research on how attention scores of modalities manifest in specific questions and how the degree of modality reflection changes with the sequence of questions and answers. The system uses the DAIC-WOZ dataset, a subset of the Distress Analysis Interview Corpus, which comprises clinical interviews for diagnosing psychological distress disorders. The dataset is augmented by randomly masking 10 out of 85 questions in each interview sequence to balance the class imbalance. The HiQuE architecture consists of three layers: the Question-Aware Module, Cross-Modal Attention, and Depression Detection. It segments the interview sequence into question-answer pairs, annotates them with hierarchical positions, and predicts depression symptoms.
The HiQuE model excels in multimodal depression detection, outperforming twelve state-of-the-art models on the DAIC-WOZ dataset. It combines modality and context-awareness, transforming cross-modal representations into a final multi-modal representation through layer normalization, concatenation, and GAP. The depression detection layer uses a fully connected layer and dropout layer, employing cross entropy as the loss function for binary classification. HiQuE's superior performance highlights its ability to capture distinct depression indicators effectively.
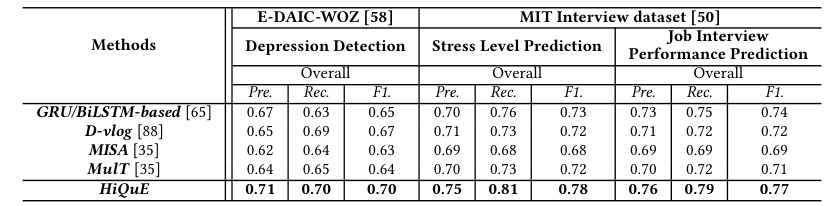
The HiQuE model's generalizability is demonstrated through its performance on the E-DAIC-WOZ and MIT Interview datasets. It outperforms baseline models like GRU/BiLSTM-based, D-vlog, MISA, and MulT in all tasks. The model uses RoBERTa as an encoder due to its superior performance compared to other embedding techniques and large language models (LLMs). HiQuE adapts to unseen questions by extracting text from audio and mapping them to a predefined list based on BERT-score similarity. The results show HiQuE's effectiveness in detecting depression cues from clinical and job interviews, highlighting its potential in various real-world scenarios.
In conclusion, the HiQuE model, presented at CIKM '24, is a significant advancement in multimodal depression detection. It effectively captures the hierarchical structure of clinical interview questions and explores correlations between different modalities to extract valuable information for depression detection. The model's generalizability to unseen questions suggests potential for application in additional speech-related tasks, making it a valuable tool for early intervention in depression.
Advanced features