Enhancing Trust in Large Language Models with Uncertainty-Aware Fine-Tuning
Ranganath Krishnan, Piyush Khanna, Omesh Tickoo·December 03, 2024
Summary
The text discusses advancements in uncertainty-aware fine-tuning for large language models (LLMs), focusing on improving their ability to provide calibrated uncertainty estimates without sacrificing accuracy. An uncertainty-aware causal language modeling approach is proposed, which optimizes for accuracy and certainty in correct predictions while increasing uncertainty for wrong ones. This method, grounded in decision theory, aims to generate natural language text with reliable uncertainty estimates, ensuring calibrated predictions. The uncertainty-aware causal language modeling (UA-CLM) loss function optimizes autoregressive models by aligning predictive probabilities and uncertainty estimates with token accuracy. Extensive experiments compare UA-CLM to standard methods, evaluating its ability to improve accuracy and uncertainty calibration in natural language generation tasks. UA-CLM outperforms standard causal language models (CLM) in hallucination detection and selective generation across various models, as evaluated using AUROC and AUARC on CoQA, TriviaQA, OK-VQA, and BioASQ datasets. The method uses Llama-2, 13B parameters, Gemma, 2B parameters, and LLaVA-1.5, 7B parameters for experiments. Fine-tuning is performed using the Low-rank Adaptation (LoRA) framework, with models fine-tuned for 3 epochs on 20% of the data split. The UA-CLM loss function optimizes for accuracy and certainty in correct predictions while increasing uncertainty for wrong ones, enhancing model reliability in causal language modeling tasks.






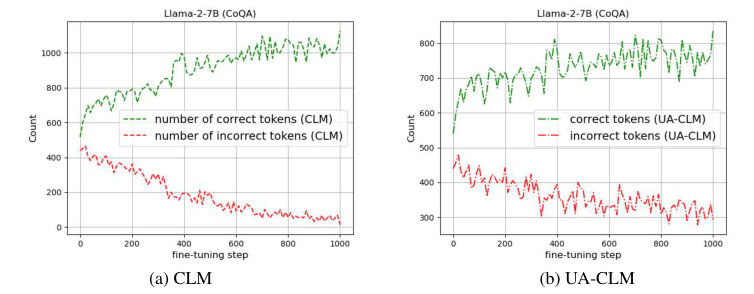
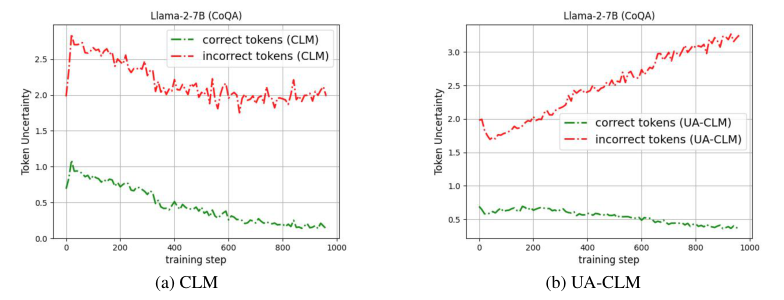
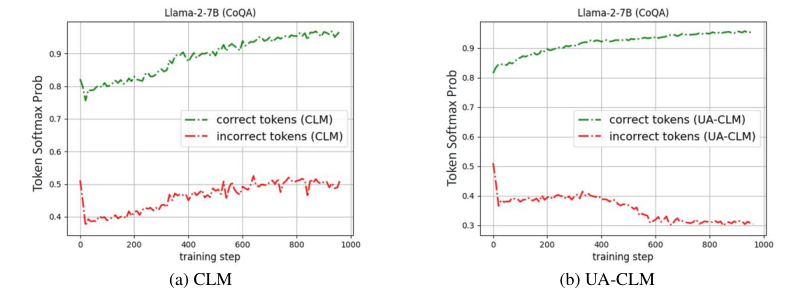
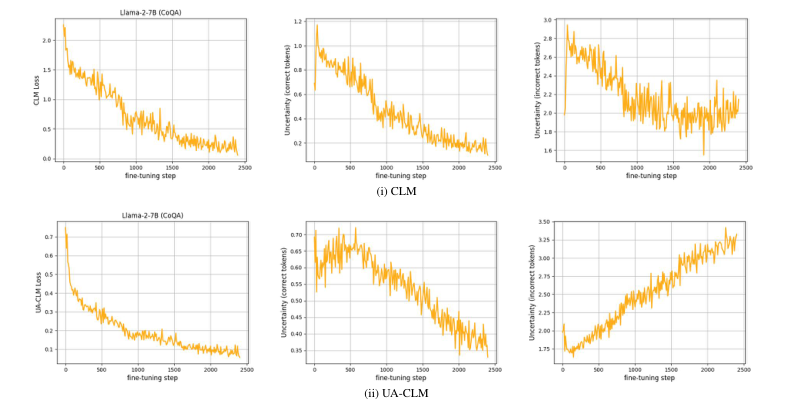
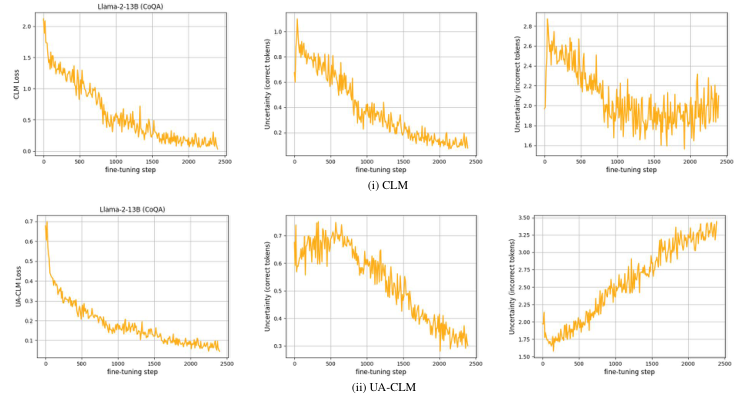
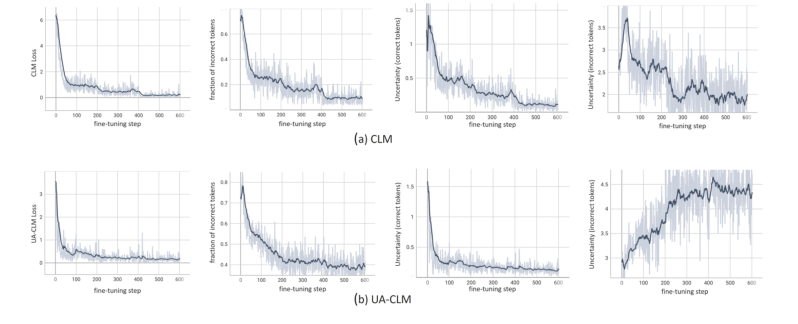
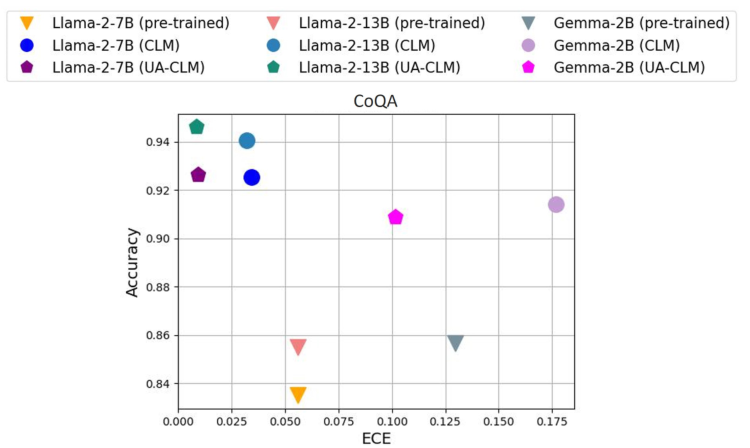
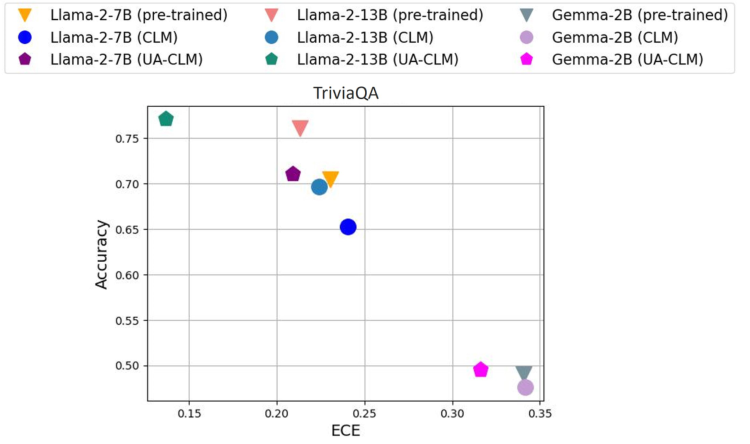
Introduction
Background
Overview of advancements in large language models (LLMs)
Importance of uncertainty-aware fine-tuning in LLMs
Objective
Aim of the research: Enhancing LLMs' ability to provide calibrated uncertainty estimates without compromising accuracy
Method
Uncertainty-Aware Causal Language Modeling (UA-CLM)
Optimization for Accuracy and Certainty
Aligning predictive probabilities and uncertainty estimates with token accuracy
Decision Theory Foundation
Theoretical underpinnings for UA-CLM
UA-CLM Loss Function
Autoregressive Model Optimization
Enhancing model performance through UA-CLM loss function
Experiments
Comparison with Standard Methods
Evaluating UA-CLM against conventional approaches
Task-Specific Evaluation
Assessing UA-CLM's performance on natural language generation tasks
Dataset Analysis
Utilizing CoQA, TriviaQA, OK-VQA, and BioASQ datasets for evaluation
Results
Hallucination Detection and Selective Generation
UA-CLM's superiority in detecting incorrect predictions
Enhanced model reliability in causal language modeling tasks
Model Parameters
Llama-2 (13B parameters), Gemma (2B parameters), and LLaVA-1.5 (7B parameters) used for experiments
Fine-Tuning Process
Application of the Low-rank Adaptation (LoRA) framework
Fine-tuning for 3 epochs on 20% of the data split
Conclusion
Contribution
UA-CLM's impact on improving accuracy and uncertainty calibration
Future Work
Potential areas for further research and development
Basic info
papers
computation and language
machine learning
artificial intelligence
Advanced features
Insights
What fine-tuning framework is used for the models, and how is the UA-CLM loss function applied in the context of causal language modeling tasks?
How does the uncertainty-aware causal language modeling (UA-CLM) approach optimize autoregressive models in terms of predictive probabilities and uncertainty estimates?
What is the main focus of the text regarding advancements in uncertainty-aware fine-tuning for large language models (LLMs)?